

一次利用rowid优化分页语句的过程
这是一个我碰到的来自生产环境的真实案例,问题sql本身单次执行速度还凑合,2~3秒出结果,但问题的焦点有两个:一个是sql只是一个简单的单表查询,表大小2gb,数据量360w左右;另外一个就是每次查询,都要产生近300m的临时表空间消耗。在业务繁忙时,多机构在前台同时执行该sql,就造成了io的暴增,进而影响到后端存储的整体性能,然后又影响到了该存储上的其它数据库(不想多说,每当想起这点都极度崩溃,简直了。。。。哔了狗了。。。)。
先简单说说环境情况,19c rac 的库,sql 内容如下:
select cpi.* from cancellation_policy_interface cpi where
cpi.company_id in (:1 , :2 , :3 , :4 , :5 , :6 , :7 , :8 , :9 , :10 ,
:11 , :12 , :13 , :14 , :15 , :16 ) and cpi.sign_date >= :17 and
cpi.sign_date <= :18 and cpi.tenant_id = 1456431580603097090 order by
cpi.id desc offset :19 rows fetch next :20 rows only;
单表查询,带很多绑定变量,表的where列数据库统计信息如下:
可以看到这些列的基数非常低,无论怎么在他们上面建索引,在cbo自动模式情况下,铁定走全表扫描了,而分页语句中,全表扫描是无法消除排序的。
其中列“id”为主键,但是order by 后面跟的又是desc,这就更麻烦了,和索引默认排序完全相反。
表的索引情况如下:
可以看到已有的索引于本sql完全无用,所以最初的执行计划如下:
在带入绑定变量具体值后,sql内容如下:
select /* index(cpi idx_test2) */
cpi.*
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 14334857315806097090
order by cpi.id desc
offset 478000 rows fetch next 1000 rows only;
执行计划如下:
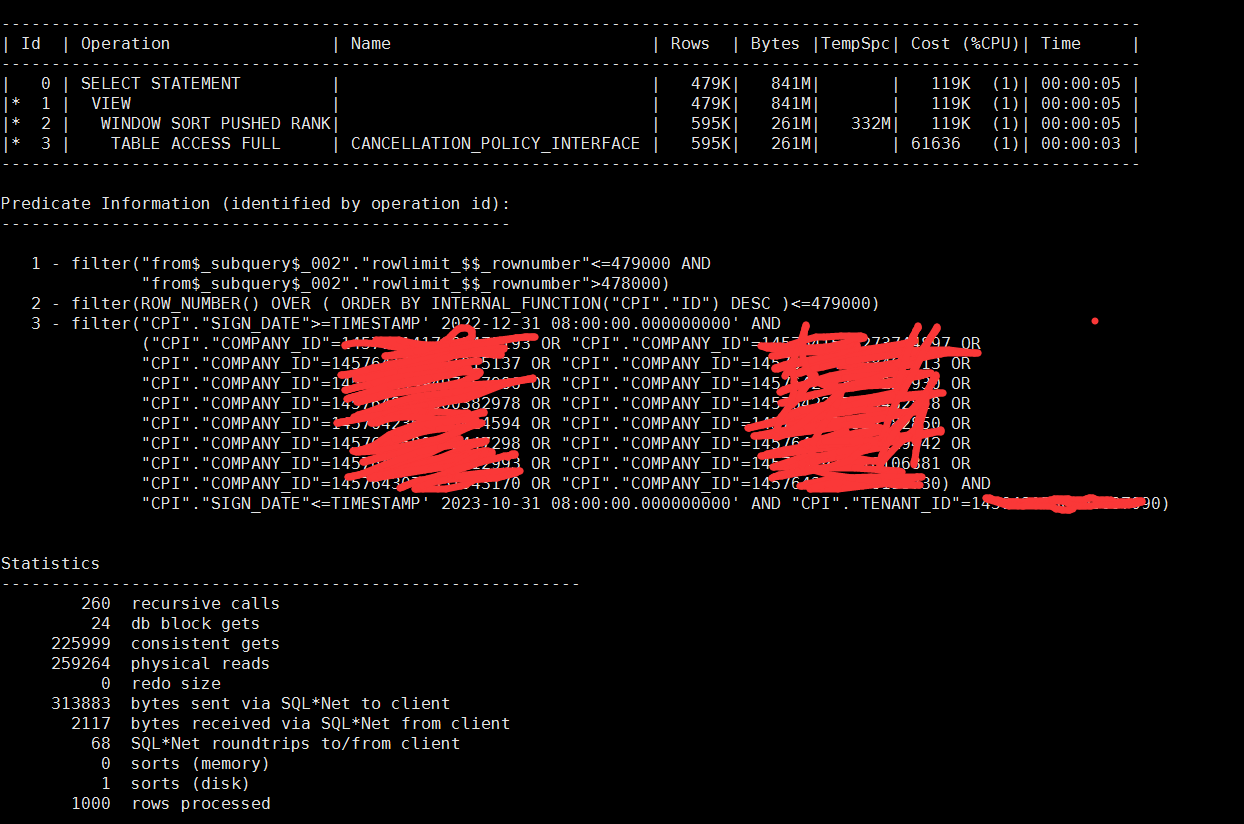
可以看到原始sql产生了大量的逻辑读和物理读,并且产生了磁盘排序,通过a-time抓取的计划,可以看到产生了300m的临时表空间使用:
(生产测试来回切换,截图颜色不同,但内容基本一样)
12c后开始支持的featch next 分页方式,实际上被解析成了一个开窗函数:
filter(row_number() over ( order by internal_function("cpi"."id") desc )<=479000)
这个地方我暂时还没弄清楚,这个“<=479000”是否已经利用上了传统分页语句中的“count stopkey”特性,我也不太清楚这个“window sort pushed rank”是否本身就包含了count stopkey的特性在里面(毕竟没有明显的count stopkey在计划里面显示出来),因为a-rows这个地方按我的理解是,它是这一步执行完成后,最终返回的记录数量,但实际过程中有可能是将整个数百万结果进行了遍历排序的,而“count stopkey”指的是“只扫描需要的行数就停止扫描并立即返回”,有没有哪位兄弟愿意解惑一下这个呀?看10046/10053什么的实在脑壳疼,我有点儿想白嫖这个知识点。。。
但是这个地方也要注意到,id=2这一步走的开窗函数filter row_number() over()<=479000,从这个地方上来看它有点儿复合count stopkey特性,在知识储备不够的情况下,那我就假设cs特性没用上吧,不然哪儿来那么大的临时表空间使用量?pga配置了10几个g呢,这么小的表!
我在后端抓取该sql的历史活动会话记录中,一个小时内有数十上百个session 在执行这个sql,并且同一个session甚至存在多次执行的情况(抓取使用的sql就不贴了,怕闹笑话)。
简单分析一下:
- 这个sql的问题点,一个在于分页语句中,首先需要获取前4789000行记录,然后在返回其中的最后1000行,对于一个才360w的表来说,返回几十万的数据,无疑就需要走全扫了,这个首先会产生大量io;
- 排序的问题,导致临时表空间的占用,这又是一个io消耗。
- 有没有使用上传统的count stopkey特性,这个我心里还打了个问号。
那么问题的解决点就是如何消除以上三个疑点。
根据已有的分页语句优化知识:
- where 条件后带等值过滤和范围过滤,同时有order by 的,按照“等值条件,order by 列,范围条件”的基本原则,建立如下索引:
create index idx_test on cancellation_policy_interface(company_id,tenant_id,id desc, sign_date);
- 但是本案例中,等值过滤并不能很好的过滤掉大多数记录,于是又建立了如下索引,因为id是主键,虽然where没用到它,但是order by 是它呀:
create index idx_test2 on cancellation_policy_interface(id desc,company_id,tenant_id,sign_date);
注意id后跟上desc,与order by 保持一致。
在不改写sql的情况下,通过hint提示,强行分别使用了这两个索引,得到的结果如下:
第一个索引:
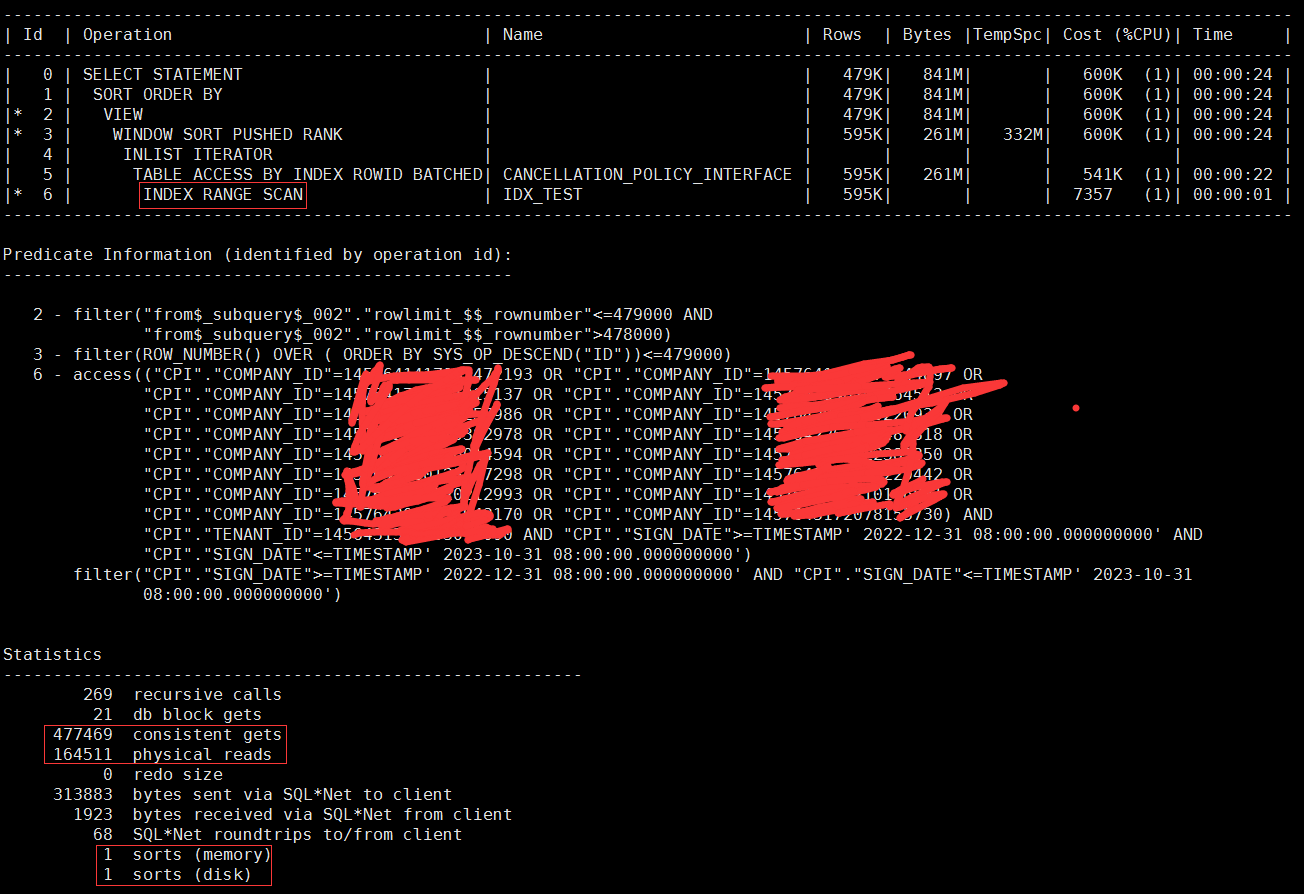
第二个索引:
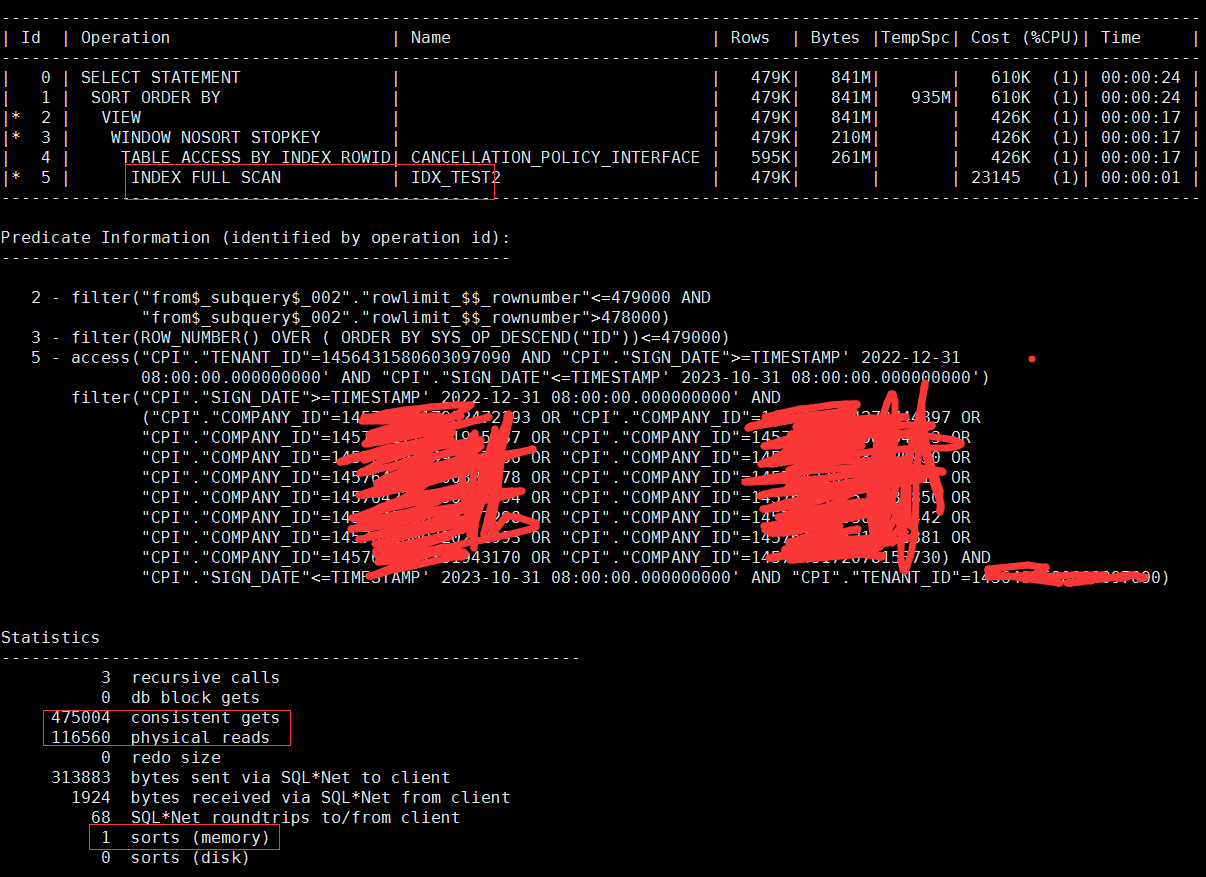
无一例外的,都产生了大量的逻辑和物理读,也无法消除排序,其中第一个索引甚至产生了磁盘排序。
为什么就是无法消除排序呢?我认为根本的原因还是在featch next这个功能被解析成了开窗函数,但是注意看开窗函数里面有个 order by ,这个很可能就是产生排序的原因了。
在脑子一团浆糊,对新特性本能带排斥的情绪下,我想到的就是,12c的这个featch next 分页框架估计还是有些问题,在少量记录的情况下问题不大,但是当记录数量非常巨大的时候,就有问题了。那干脆返回传统的技术框架上来试试好了。
于是开始上传统的分页架构,sql如下:
select * from (
select a.*, rownum rn
from (
select /* index(cpi idx_test2) */
cpi.*
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 1236431544863097090
order by cpi.id desc
) a
where rownum <= 479000)
where rn>478000;
sql里面贴出来的,是强制使用了idx_test2这个索引,笔者在这个框架下尝试过如下几种方式:
- 不加hint提示,会走全扫,逻辑读 物理读都超过20w次,无法消除排序,还有磁盘排序,产生临时表空间消耗,结果就不贴了。
- 加hint idx_test,走索引范围扫描,逻辑读 物理读同样很大,无法消除排序:
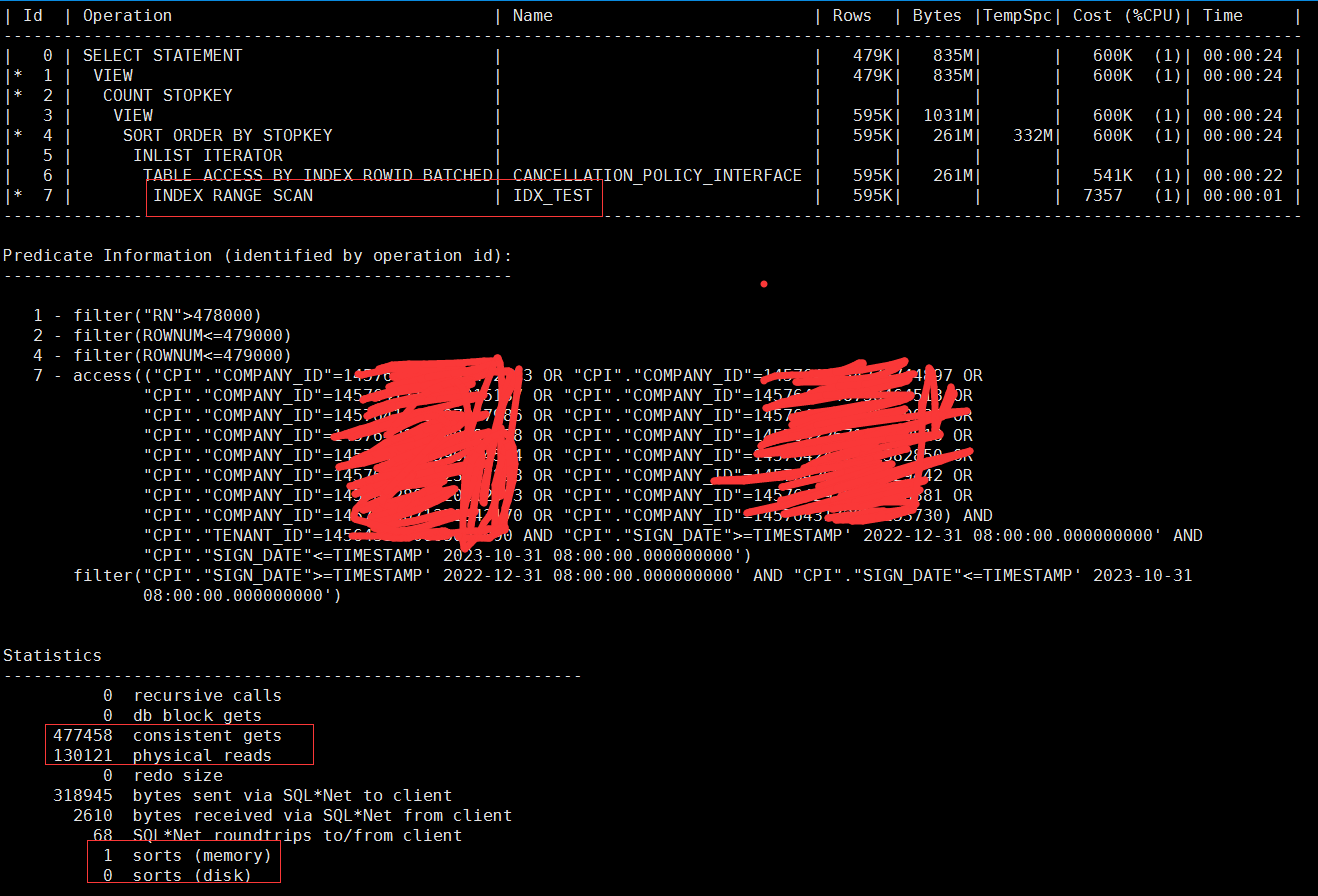
- 加hint idx_test2,走索引全扫,逻辑读 物理读同样很大,但消除了排序:

到了这一步之后,优化取得了一定的进展,消除了排序,但是还有个问题就是,逻辑与物理读还是太高了,上了生产之后,弄不好情况会更糟。
怎么才能消除这个物理读呢?这个地方的物理读,实际上绝大部分都是因为那几十万条rownum回表造成的,那么怎么消除这个回表呢?笔者突然间就想到了两个关键点:1. id 是主键;2. 可以用rowid来代替回表呀。
于是在10秒钟内,改写了新的sql如下:
select * from cancellation_policy_interface
where rowid in (select rid from
(select id,rid,rn from (
select a.*, rownum rn
from (
select /* index(cpi idx_test2) */
cpi.id,rowid rid
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 1236431555863097090
order by cpi.id desc
) a
where rownum <= 479000)
where rn>478000)
);
sql的意思我就不班门弄斧的解释了,各位兄弟应该都能看明白,idx_test,和全扫什么的我也不测了,就用这个idx_test2,结果如下:
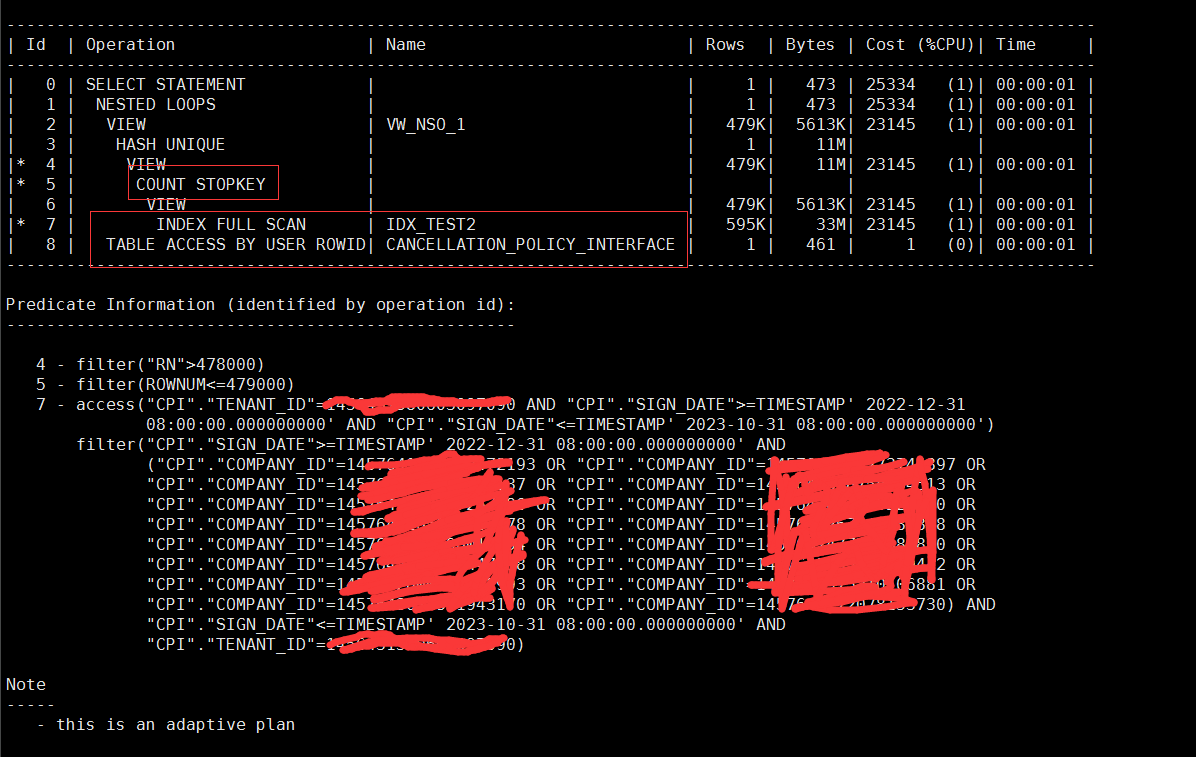
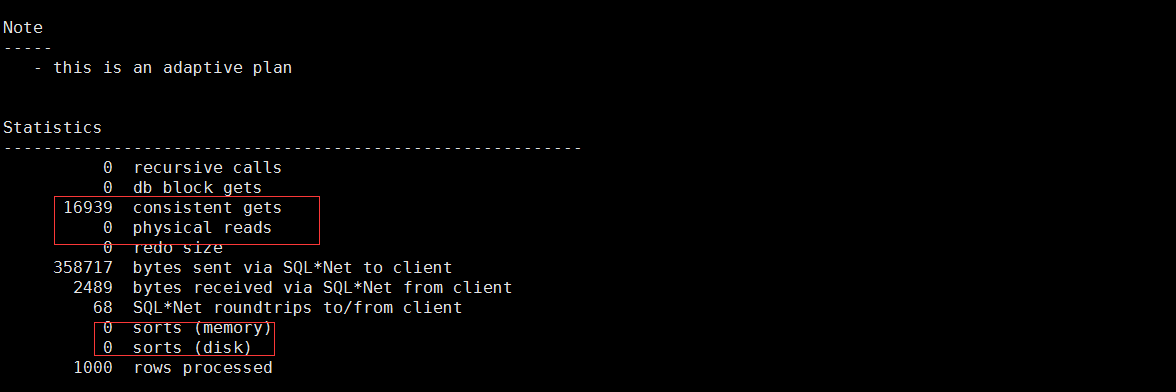
逻辑读降低了几十倍,物理读如果多次执行的话完全为0,排序也消失了,临时表空间消耗也消失了,sql虽然稍微变复杂了一点,但性能提升不小呀。
到了这里,原理实际上就两个:1. 利用id为主键,把他建到新的带desc的索引里面,消除排序,同时只记录下最内层分页语句的rowid,这样就不会在这里回表,因为id和rowid都已经在索引里面了;2. 第二次获取count stopkey特性,拿到最终的rowid;3. 最后通过rowid(此时只剩下1000个),直接从原表里面取记录即可。
利用改写后的sql和原sql查询产生的记录结果比对了一下,结果完全一样(这是改写的前提条件呀)。
这个案例有一定的参考性,可以为今后将来类似的分页语句优化做参考,值得记录一下,虽然估计有很多前辈高手早就不屑一顾了,但对我来说还是很有价值呀。第一次写这类的文章,以往我都是往笔记里面一扔了事儿,自己清楚就好,过程当中可能会存在一些错误或者不足之处,希望各位一定一定不吝赐教。
掌声,鲜花!
经过一天的思考之后,我对这个fetch next 始终念念不忘,oracle 这么大个公司,怎么可能在设计这个新特性的时候,会不考虑到这个count stopkey的优势呢?于是我又拿了原来的fetch next 框架重新实验,区别是这次我还是利用了rowid的特性:
第一种尝试:不加任何hint,让cbo自己选择
select * from cancellation_policy_interface
where rowid in (select a.rid from
(
select
cpi.id,rowid rid
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 1234431854603097090
order by cpi.id desc
offset 478000 rows fetch next 1000 rows only
) a
);
结果如下:
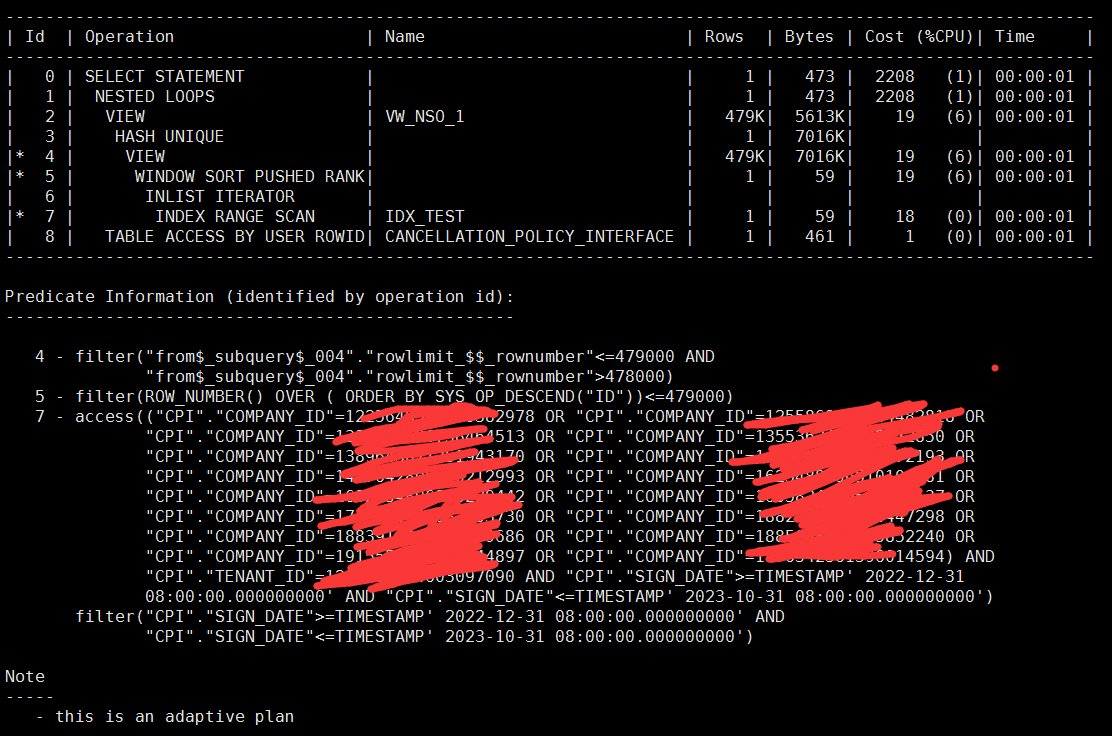
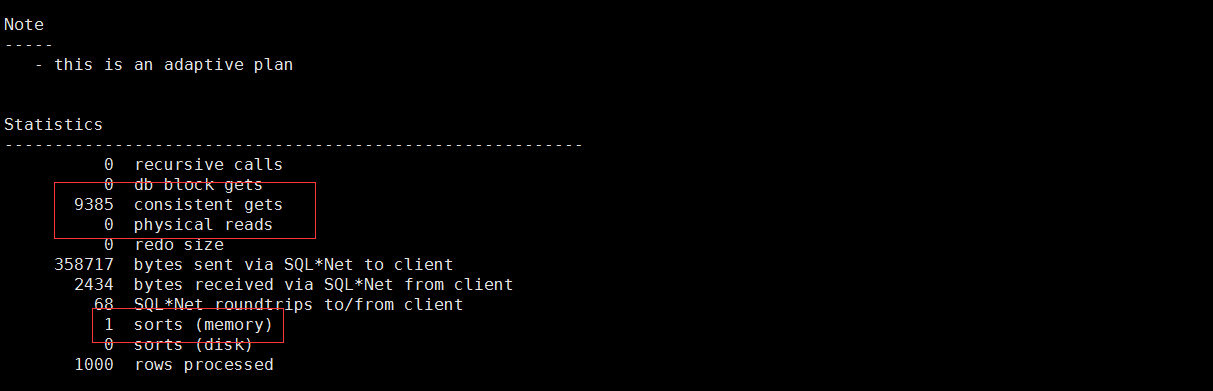
嘿!效果不错,逻辑读非常低,甚至比上面的sql还低,因为cbo自动选择的idx_test,而且走的范围扫描。这个地方从表象来看,似乎可以证明这个fetch next 其实是用到了stopkey 这个功能的,不然逻辑读不可能这么低。当然这次还是没能完全消除排序,但是注意看,排序只有内存排序.
下面试试idx_test2:
select * from cancellation_policy_interface
where rowid in (select a.rid from
(
select /* index(cpi idx_test2) */
cpi.id,rowid rid
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 1234435628603097090
order by cpi.id desc
offset 478000 rows fetch next 1000 rows only
) a
);
结果如下:
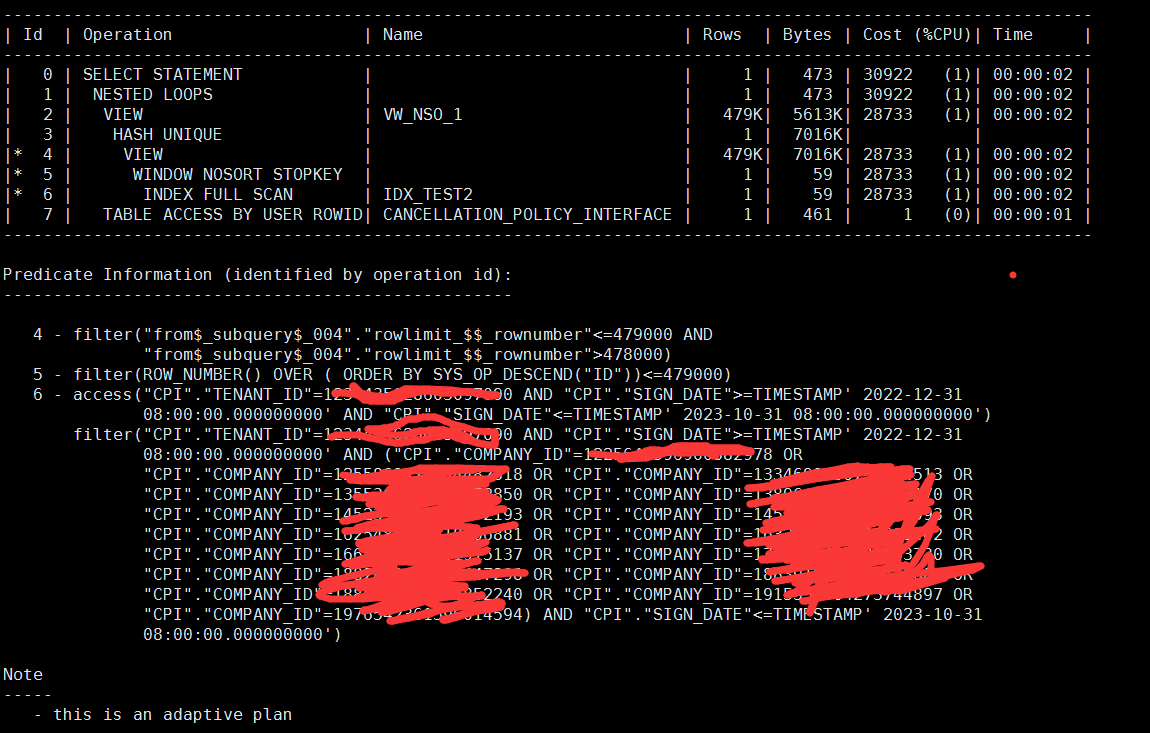

效果也不错,并且这里我们看到了明显的stopkey关键字,证明了fetch next实际上是继承了传统分页框架的count stopkey特性的,同时还完全消除了排序。只是这里走idx_test2这个索引的时候,用的索引全扫,因为where条件里面没有id列,所以这个方式他的逻辑读会大一些。
两种方式各取舍点,在意io性能的,就用第一种方式,在意排序的就用第二种方式。
也许读者们可以注意到,两种方式fetch next解析后,他都有个order by关键字呀,为啥一个有内存排序,一个就没有呢?我猜测,只是猜测哈,问题的关键点就在于我们两个索引的列顺序上了,我们都知道索引是有序的,但是复合索引存储的时候到底是怎么个排序法,这估计需要好好研究下复合索引的存储结构模式,我也说不太明白,就不闹笑话了。
那么这里就可以稍微做点儿总结:这个sql的关键性能点,还是在于回表的时候,访问了太多的数据,因为它是select *,那么遇到这种情况的时候,我们要想办法减少回表次数,或者减少回表时访问的数据量,rowid这个绝招就可以想办法利用起来解决这个问题。方法多样,今后的情况也会多样,灵活运用就是,多动手,多测试。
看来我这人比较较真儿,这是我第n次更新这篇文章了,我始终对索引无法完全消除排序耿耿于怀,经过我无数次的实验,也吃尽了经验和知识储备不足的苦头,从索引的源头开始理解,总算是弄清楚了为什么在这个例子当中,idx_test 索引始终无法消除排序的困惑了,原因就在于:
组合索引的原则,属于第一列全局有序,之后的列属于局部有序的情况。
但是在实际的数据组合当中,当我们在排序完第1,第2列之后,同时第3列的排序仍然可以有条件做到全局有序的情况时,索引就可以消除排序。但是当我们排序完第1,第2列之后,第3列无法做到全局有序时,最终还是会发生排序。
那么在本例子当中,从统计信息当中可以看到,字段tenant_id从始至终都只有1个值,那么如果以它为第一列,id为第二列,其它列放在后面(顺序无论),那么情况就是,第一列的值完全一样只有1个,第二列自然就全局有序。
建立如下索引,理论上除了可以享受到索引范围扫描(虽然这个范围扫描带来的好处不怎么样,因为tenant_id只有一个,范围扫描近乎索引全扫了)这个好处之外,还可以消除排序:
create index idx_test3 on cancellation_policy_interface(tenant_id,id desc, company_id,sign_date);
做个测试:
select * from cancellation_policy_interface
where rowid in (select a.rid from
(
select /* index(cpi idx_test3) */
cpi.id,rowid rid
from cancellation_policy_interface cpi
where cpi.company_id in (
1457642800320212993,
1389643071351943170,
1452341417982472193,
1976542361596014594,
1883919494972579686,
1915554564273744897,
1632254896303229442,
1665824169501915137,
1255869476144482818,
1334699586758464513,
1882859647123447298,
1625488596510106881,
1225648596900382978,
1778596425632153730,
1355362489522472850,
1885648559645852240)
and cpi.sign_date >= to_timestamp('2022-12-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.sign_date <= to_timestamp('2023-10-31 08:00:00','yyyy-mm-dd hh24.mi.ss')
and cpi.tenant_id = 1234435628603097090
order by cpi.id desc
offset 478000 rows fetch next 1000 rows only
) a
);
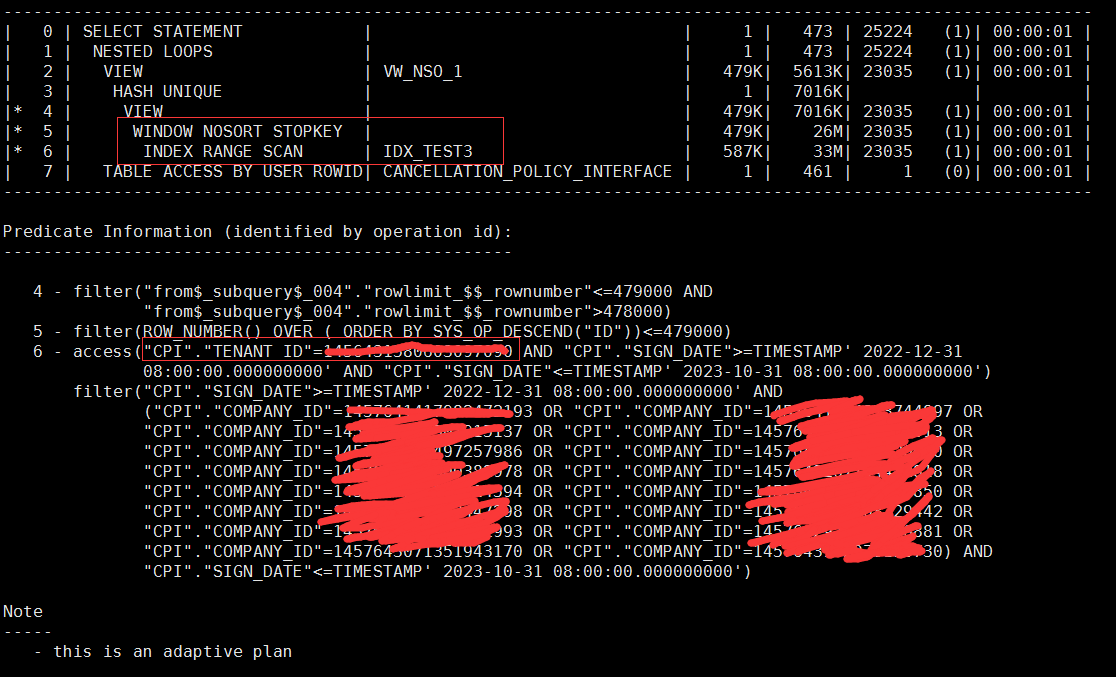
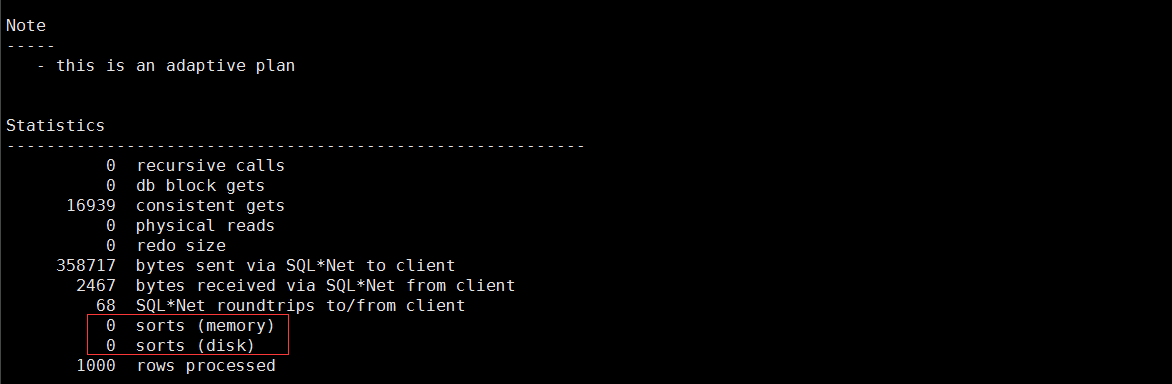
与心理的预期完全一致!
好了,也许还有很多疏漏之处,大家有高招绝招和指点的,请一定在后面留言!此文章我就不再做更新了,智商不怎么达标,实在太费脑子了。