

ogg抽取进程全部abend
投递进程无延迟,抽取进程均abend;
观察ogg日志,提示无法写入sysaux表空间!!!
排查发现sysaux表空间不足,扩容后,问题处理完成,反思?
为什么sysaux表空间不足,是什么对象占用过多导致的?后续如何规避?
其实思路有点类似诊断awr裸数据基表占用过大的空间导致系统表空间不足,其实思路一样,定位大对象,然后mos检索相关对象如何安全有效的清理!
2.1 估算sysaux表空间数据增长的情况
sql> select ts# from v$tablespace where name='sysaux' and rownum=1;
ts#
----------
1
select a."used_g",b."used_g",a."used_g"-b."used_g" as "7_day" from
(select round(sum(max(tablespace_usedsize)*8192/1024/1024/1024),4) as "used_g",
1 id
from dba_hist_tbspc_space_usage where
trunc(to_date(rtime,'mm/dd/yyyy hh24:mi:ss'))=trunc(sysdate)
and tablespace_id=1
group by tablespace_id) a,
(select round(sum(max(tablespace_usedsize)*8192/1024/1024/1024),4) as "used_g",
1 id
from dba_hist_tbspc_space_usage where
trunc(to_date(rtime,'mm/dd/yyyy hh24:mi:ss'))=trunc(sysdate)-5
and tablespace_id=1
group by tablespace_id) b where a.id=b.id;
used_g used_g 7_day
---------- ---------- ----------
51.8245 11.9203 39.9042
本来脚本是计算7天的数据增长,但是检查发现dba视图最近也是只有记录5天的!!!
这个db是新建的库,脚本修改为有数据的5天数据增长,可以发现sysaux5天增长了进40g空间!!!
2.2 找到top segments
select * from (
select owner,segment_name,segment_type,round(bytes/1024/1024/1024) as "bytes_g"
from dba_segments where tablespace_name='sysaux'
and bytes>1*1024*1024*100
) a order by a.bytes_g;
owner segment_name segment_type bytes_g
-------------------- ------------------------------ ------------------ ----------
system logmnr_col$ table partition 0
sys sys_lob0000011147c00038$$ lobsegment 0
system logmnr_i2col$ index partition 0
mdsys sys_lob0000064076c00006$$ lobsegment 0
system logmnr_col$ table partition 0
system logmnr_col$ table partition 0
system logmnr_col$ table partition 0
system logmnr_col$ table partition 0
system logmnr_col$ table partition 0
system logmnr_col$ table partition 0
system logmnr_i2col$ index partition 0
system logmnr_i2col$ index partition 0
system logmnr_i2col$ index partition 0
system logmnr_i2col$ index partition 0
system logmnr_i2col$ index partition 0
system logmnr_i2col$ index partition 0
system sys_lob0000001462c00009$$ lobsegment 1
system logmnr_restart_ckpt$_pk index 3
system logmnr_restart_ckpt$ table 45
19 rows selected.
2.3 查询一下top表信息
sql> select table_name,partitioned from dba_tables
where table_name='logmnr_restart_ckpt$';
table_name par
------------------------------ ---
logmnr_restart_ckpt$ no
select * from system.logmnr_restart_ckpt$ where rownum<=20;
---- ---------- ---------- ----------
1 1 8.9662e 11 131
33 9421 6648 47838
02000003f8f2c5977000000090aa6f9d70000000ce01
00004f8b4c0010000000b43724bfd0000000b43724bf
d000000083002100cd2400000f000000f8190000deba
0000022000000000000001000000 2 1
其实基本上了解到这个是非分区表! 并且这个表有45g的大小占用!
2.4 检索相关资料
sysaux tablespace getting heavily utilized when extracts are running (doc id 2802325.1)
这篇mos的文章描述,ckpt检查点写入太过频繁,导致这个基表很大,那么如何降低基表的写入频率,可以对参数进行控制,设置max_sga_size,检查点的写入间隔将是max_sga_size*5,从而大大降低检查点的写入频率
oracle goldengate - version 18.1.0.0.1 and later
sysaux gets filled up when extract is started and continuously grows.
stopping the extracts stops the growth and the tablespace releases
the space after sometime but as soon as the extracts are started again
the tablespace again gets filled up.
cause
excessive checkpointing by the extracts
solution
please check the logminer checkpoint interval using alert log.
for example here, the alert log indicates the logminer checkpoint is 10m.
this is far too small and will cause excessive checkpointing.
logminer: memory size = 999m, checkpoint interval = 10m
this value can be influenced by setting
tranlogoptions integratedparams (max_sga_size 1000)
in which case it will be set to 5 times this value
e.g. logminer: memory size = 999m, checkpoint interval = 5000m
increasing this value will decrease the checkpointing.
sysaux 空间使用问题故障排除(文档 id 1399365.1)
system.logmnr_restart_ckpt$ grows quite fast (doc id 735071.1)
这篇文章描述,oracle db版本是10.2~11.1的情况下,ckpt基表数据增长很快,默认检查点也是10m写入,可以修改_checkpoint_frequency 到1000,从而降低检查点的写入频率,其实和上述ogg 18.1原理是一样的,只是具体操作不一样。
oracle database - enterprise edition
- version 10.2.0.1 to 11.1.0.6 [release 10.2 to 11.1]
streams capture setup is defined and two symptoms have been observed:
1) system.logmnr_restart_ckpt$ table grows daily and the number
of rows in the table just grow
2) excessive archive log generated in this database,
when starting capture
cause
observe if the value of capture parameter _checkpoint_frequency is below 10,
which is the default value for this parameter.
this parameter control how often the logminer session associated
to the capture is going to do a logminer checkpoint,
so having a value of 10 means that after 10mb of redo activity
we do a logminer checkpoint.
this causes lots of entries on table system.logmnr_restart_ckpt$
and causes that the streams tables grows, also this causes delays
on the streams performance.
solution
in order to conduct this database to a normal situation, please do:
1) increase capture parameter _checkpoint_frequency to 1000 , by doing:
exec dbms_capture_adm.stop_capture ('capture');
begin
dbms_capture_adm.set_parameter
('capture','_checkpoint_frequency','1000');
end;
/
exec dbms_capture_adm.start_capture ('capture');
note that the capture may take some time to start as there are lot of
checkpoints to manage.
the aim of this is to reduce the number of logminer checkpoint and
therefore reduce the number of entries on logmnr_checkpoint_entries
table and also reduce the consume and increase performance.
value 1000 for _checkpoint_frequency is a recommended value for
releases 10gr2 and 11g, according to metalink note 418755.1
2) during next 10 days shrink table system.logmnr_restart_ckpt$
and associated indexes, to reduce
the amount of space consumed by this table.
execute at least once in a day, although recommended is three times in a day,
the steps documented on metalink note 429599.1 to do the shrink:
how to reduce the highwater of logmnr_restart_ckpt$ (doc id 429599.1)
那这一篇文章,就是讲述如何清理这个基表,从10.2的版本开始,oracle 有参数checkpoint_retention_time 定期进行清理,默认是60天,当然每个版本都存在差异,不要被这个60天吓到了。
那么清理策略:
1.修改参数,指定清理的周期,例如原本保留7天修改为3天,近乎只保留一半,而且这个删除操作是时时刻刻执行的,你写入新的检查点,计算保留时间大于的就被删除,delete操作,非分区表,感觉oracle后续可以在优化一下,类似审计基表12c之后自动改为分区表可以删除分区从而加快删除的速度;
2.oracle也提到了一句设置_checkpoint_frequency,这个就是上述2篇文章提到的检查点写入的频率,频率低写的数据少,保留天数多一点总量还是少的。
oracle database - enterprise edition
- version 10.2.0.2 to 11.2.0.2.0 [release 10.2 to 11.2]
oracle streams enables the sharing of data and events in a data stream,
either within a database or from one database to another.
this article is intended to provide information regarding
the management of logmnr_restart_ckpt$ table.
solution
periodically, the mining process checkpoints itself for quicker restart.
these checkpoint information is maintained in the sysaux tablespace by default.
from oracle 10.2 onwards, the purging of logmnr_restart_ckpt$ is done
automatically by oracle. there is a capture parameter
checkpoint_retention_time that determines how
frequently the purge occurs.
checkpoint_retention_time, controls the amount of checkpoint data that is
retained by moving the first_scn of the capture process forward.
when the checkpoint_retention_time
is exceeded (default = 60 days), the first_scn is moved and the streams metadata
tables previous to this scn(first_scn) can be purged.
space in the sysaux tablespace should be reclaimed at this time.
you can alter checkpoint_retention_time to lesser value to purge
the metatdata tables more frequently using the following syntax :
exec dbms_capture_adm.alter_capture
(capture_name =>'strmadmin_capture ',checkpoint_retention_time=>7);
--
it is also useful to tune _checkpoint_frequency appropriately in order
to minimise the checkpoint information stored and this should be mentioned.
alter table system.logmnr_restart_ckpt$ enable row movement;
alter table system.logmnr_restart_ckpt$ shrink space ;
alter table system.logmnr_restart_ckpt$ modify lob (ckpt_info) (shrink space);
alter table system.logmnr_restart_ckpt$ disable row movement;
alter index shrink space;
2.5 问题处理
1)降低ogg ckpt写入频率
修改前,查询db alert,发现很不规律,有写入频率低的,也有默认的10m
[oracle@xx trace]$ cat alert_cdbprod1.log |grep memory
logminer: memory size = 8195m, checkpoint interval = 40980m
logminer: memory size = 999m, checkpoint interval = 10m
备注:写入间隔高的设置了参数max_sga_size 4098
调整抽取进程对应参数,添加参数
tranlogoptions integratedparams(max_sga_size 1000, parallelism 2)
观察db alert
logminer: memory size = 999m, checkpoint interval = 5000m
但是第一次调整参数后,检查发现抽取进程延迟很高,因此为了加快避免抽取进程延迟;
第二次设置如下参数,加大内存限制,并行加大
tranlogoptions integratedparams(max_sga_size 2000, parallelism 12)
2)减少ogg ckpt保留时间
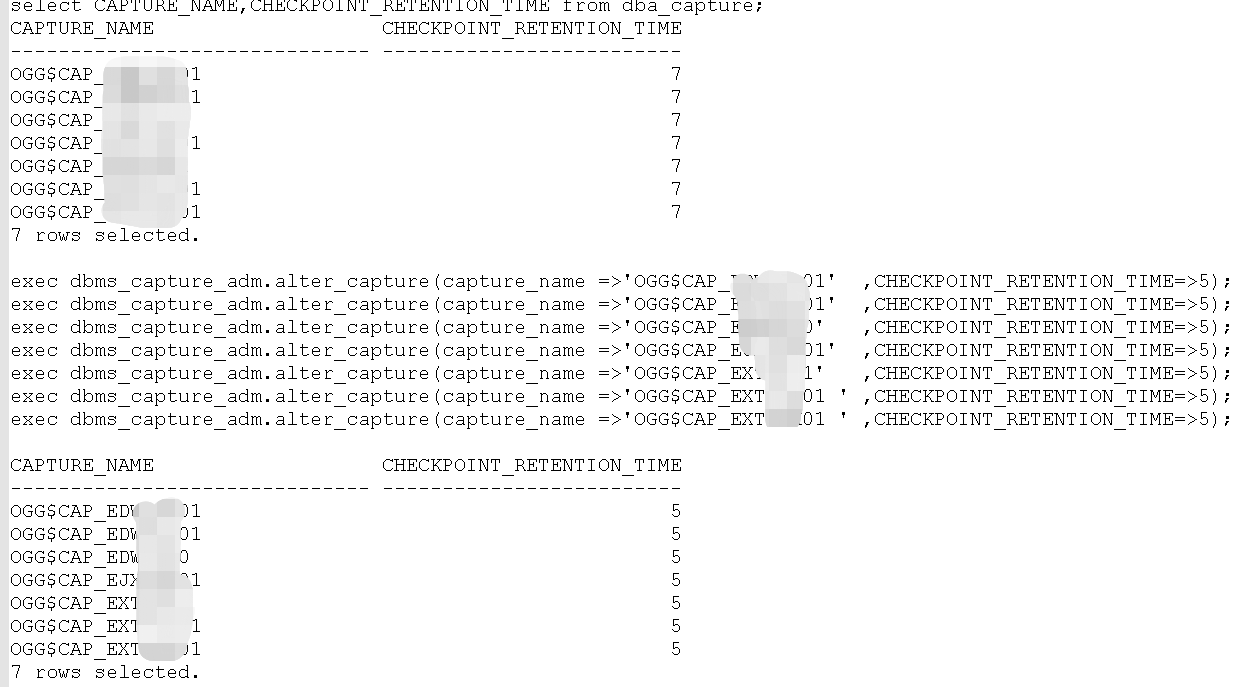
本次ogg19.1 for db 19.3 ogg有7个抽取进程,默认保留时间是7天,调整为5天!
观察调整后,数据是否降低!
select /* parallel(12,a) */ count(*) from system.logmnr_restart_ckpt$ a;
---数据在降低
count(*)
----------
33227356
--在降低
count(*)
----------
31242474
1.对于后续ogg抽取进程,都可以配置加上内存参数的限制参数,从而降低基表的写入频率;
2.加强数据库的监控,sysaux这么重要的系统表空间使用率比较高就快速告警,并且提前进行人为干预去分析什么对象占用的,占用是否合理;
3.上述问题已经调整了写入频率,保留时间调整为5天,持续观察如果数据还是增长,可以考虑再次降低保留时间或者对sysaux表空间扩容。