

前 言
为啥开头就放一个二维码呢?是因为近期抄袭被吵的沸沸扬扬,相信每个博主也都遇到过被爬取文章的情况,当你的作品,文章被人拿去标原创,去售卖真的会被恶心到,以前写文章的时候发现有的博主读完你的文章然后自己实验一遍发出去,虽然也有点无耻,但勉强能接受。以前还有培训机构把我翻译的 051、052、053 ocp 资料拿去给学员当教材了,我也没去管,后来各个网站直接爬取我的文章,看到的比较多,也没法去找到本人,我也就懒得去管了,但想着也是恶心,昨晚上我还发现有个叫“xx运维”的网站,直接爬取墨天轮很多博主的文章一字不改的发过去了,我发现很多博主的文章都在里面,虽然阅读量为零但还是感觉恶心人,而且这种爬虫的网站也不在少数,所以说,国内知识米乐app官网下载的版权意识还是很薄弱,大佬们辛辛苦苦出本书,写的文章,巡检脚本,几天就给你整很多盗版的,看看国外就没这样的事儿。没办法,我只能在开头和结尾加申明了。

有些时候为了缩短数据泵导入导出的时间,一般会选择将大表和其他表分开导出,尤其是遇到大表有 lob 字段的,导出时间会更慢。这样则需要分开导出大表和其他表,而单独导出大表也会很慢,可以利用 rowid 分片技术将大表分开来同时导出,提高导出效率。另外,数据泵常用的导出导入命令及最佳实践也值得参考学习。
1、大表信息
表记录只有 1525536 条,但是只有 1.8g 大小,有两个 clob 字段,查看 lob 大小有 13.71g 大小。
connected to:
oracle database 19c enterprise edition release 19.0.0.0.0 - production
version 19.15.0.0.0
sql> select count(*) from prod.t_ca_tx_his;
count(*)
----------
1525536
sql> set line 120
sql> col owner for a30
sql> col segment_name for a30
sql> select owner,segment_name,bytes/1024/1024/1024 from dba_segments where segment_name='t_ca_tx_his' and owner='prod';
owner segment_name bytes/1024/1024/1024
------------------------------ ------------------------------ --------------------
prod t_ca_tx_his 1.83007813
sql> desc prod.t_ca_tx_his
name null? type
----------------------------------------------------------------- -------- --------------------------------------------
sequence_no not null number(18)
pk_tx_his not null varchar2(36)
fk_user_ccbscf varchar2(36)
fk_person_ccbscf varchar2(36)
soft_ca_brand not null varchar2(20)
soft_ca_user_id varchar2(50)
target_url varchar2(300)
tx_code varchar2(20)
tx_request clob
tx_response clob
tx_error_code varchar2(50)
tx_error_message varchar2(500)
create_time not null date
fk_user_create not null varchar2(36)
user_name_create not null varchar2(60)
sql> col segment_name for a30
sql> select segment_name,bytes/1024/1024/1024 from dba_segments where owner='prod' group by segment_name,bytes/1024/1024/1024 order by 2 asc;
.........省略........
segment_name bytes/1024/1024/1024
------------------------------ --------------------
t_open_message_sms_record 2.8125
sys_lob0000167075c00010$$ 13.7119141
--查看某用户下 lob 字段大小
set line 345 pages 456
col owner for a20
col table_name for a40
col segment_type for a20
col column_name for a35
select
a.owner,
b.table_name,
b.column_name,
a.segment_type,
round(sum(a.bytes/1024/1024/1024),2) g
from dba_segments a
left join dba_lobs b
on a.owner = b.owner
and a.segment_name = b.segment_name
where a.segment_type='lobsegment'
and a.owner in('&owner')
group by a.owner,b.table_name,b.column_name,a.segment_type
order by 5 desc;
owner table_name column_name segment_type g
-------------------- ---------------------------------------- ----------------------------------- -------------------- ----------
prod t_ca_tx_his tx_response lobsegment 13.71
2、正常导出大表
sql> set linesize 9999
sql> col owner for a10
sql> col directory_name for a30
sql> col directory_path for a60
sql> select * from dba_directories;
sql> create or replace directory public_dump as '/data/ora-share';
sql> grant read,write on directory public_dump to public;
$ expdp prod/prod_#31 directory=public_dump logfile=prod.t_ca_tx_his.log dumpfile=prod.t_ca_tx_his.dmp tables=t_ca_tx_his compression=all cluster=n
export: release 19.0.0.0.0 - production on wed nov 29 15:00:36 2023
version 19.15.0.0.0
米乐app官网下载 copyright (c) 1982, 2019, oracle and/or its affiliates. all rights reserved.
connected to: oracle database 19c enterprise edition release 19.0.0.0.0 - production
flashback automatically enabled to preserve database integrity.
starting "prod"."sys_export_table_01": prod/******** directory=public_dump logfile=prod.t_ca_tx_his.log dumpfile=prod.t_ca_tx_his.dmp tables=t_ca_tx_his compression=all cluster=n
processing object type table_export/table/table_data
processing object type table_export/table/index/statistics/index_statistics
processing object type table_export/table/statistics/table_statistics
processing object type table_export/table/statistics/marker
processing object type table_export/table/procact_instance
processing object type table_export/table/table
processing object type table_export/table/grant/owner_grant/object_grant
processing object type table_export/table/comment
processing object type table_export/table/constraint/constraint
. . exported "prod"."t_ca_tx_his" 3.710 gb 1524771 rows
master table "prod"."sys_export_table_01" successfully loaded/unloaded
******************************************************************************
dump file set for prod.sys_export_table_01 is:
/data/ora-share/prod.t_ca_tx_his.dmp
job "prod"."sys_export_table_01" successfully completed at wed nov 29 16:16:40 2023 elapsed 0 01:16:03
--排除大表导出其他表和对象 t_auth_original
nohup expdp \'/ as sysdba\' directory=public_dump dumpfile=expdp_prod_cc-2023-11-25_%u.dmp compression=all exclude=table:\"in \'t_ca_tx_his\'\" exclude=statistics parallel=4 cluster=no schemas=prod_cc logfile=expdp_prod_cc112521.log &
3、利用分片导出 lob 大表
--可以利用 rowid 切片方式导出 lob 大表 vi tableid.par userid='/ as sysdba' directory=public_dump content=all compression=all cluster=no tables=prod.t_ca_tx_his nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_01.dmp logfile=tableid_01.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=0\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_02.dmp logfile=tableid_02.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=1\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_03.dmp logfile=tableid_03.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=2\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_04.dmp logfile=tableid_04.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=3\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_05.dmp logfile=tableid_05.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=4\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_06.dmp logfile=tableid_06.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=5\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_07.dmp logfile=tableid_07.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=6\" & nohup expdp parfile=tableid.par dumpfile=t_ca_tx_his_08.dmp logfile=tableid_08.log query=\"where mod\(dbms_rowid.rowid_block_number\(rowid\),8\)=7\" &
查看日志,大概每个 tableid 均需要 22 分钟左右,如不用 rowid 分片则需要一个多小时才能导出 01:16:03 。
more tableid_08.log ;;; export: release 19.0.0.0.0 - production on wed nov 29 16:53:42 2023 version 19.15.0.0.0 米乐app官网下载 copyright (c) 1982, 2019, oracle and/or its affiliates. all rights reserved. ;;; connected to: oracle database 19c enterprise edition release 19.0.0.0.0 - production ;;; ************************************************************************** ;;; parfile values: ;;; parfile: tables=prod.t_ca_tx_his ;;; parfile: compression=all ;;; parfile: content=all ;;; parfile: directory=public_dump ;;; parfile: userid=/******** as sysdba ;;; ************************************************************************** flashback automatically enabled to preserve database integrity. starting "sys"."sys_export_table_08": /******** as sysdba parfile=tableid.par dumpfile=t_ca_tx_his_08.dmp logfile=tableid_08.log query="where mod(dbms_rowid.rowid_block_number(rowid),8)=7" processing object type table_export/table/table_data processing object type table_export/table/index/statistics/index_statistics processing object type table_export/table/statistics/table_statistics processing object type table_export/table/statistics/marker processing object type table_export/table/procact_instance processing object type table_export/table/table processing object type table_export/table/grant/owner_grant/object_grant processing object type table_export/table/comment processing object type table_export/table/constraint/constraint . . exported "prod"."t_ca_tx_his" 471.9 mb 190827 rows master table "sys"."sys_export_table_08" successfully loaded/unloaded ****************************************************************************** dump file set for sys.sys_export_table_08 is: /data/ora-share/t_ca_tx_his_08.dmp job "sys"."sys_export_table_08" successfully completed at wed nov 29 17:15:40 2023 elapsed 0 00:21:50 job "sys"."sys_export_table_05" successfully completed at wed nov 29 17:15:40 2023 elapsed 0 00:21:54 job "sys"."sys_export_table_01" successfully completed at wed nov 29 17:16:26 2023 elapsed 0 00:22:42 job "sys"."sys_export_table_07" successfully completed at wed nov 29 17:17:50 2023 elapsed 0 00:24:01 job "sys"."sys_export_table_02" successfully completed at wed nov 29 17:17:27 2023 elapsed 0 00:23:42 job "sys"."sys_export_table_04" successfully completed at wed nov 29 17:16:45 2023 elapsed 0 00:22:59 job "sys"."sys_export_table_03" successfully completed at wed nov 29 17:16:24 2023 elapsed 0 00:22:38 job "sys"."sys_export_table_06" successfully completed at wed nov 29 17:16:03 2023 elapsed 0 00:22:15
4、目标库分别导入 dmp
导入时是挨个 dmp 执行串行导入,每个 dmp 都会锁表,第一个 dmp 导入完成后表锁释放,接着导入第二个,实际上也不是特别快。
--创建好表空间和用户 create tablespace dt_cc_data datafile ' data' size 20g autoextend on next 8192 maxsize 32767m; --查看原用户创建语句及权限 set long 9999 select dbms_metadata.get_ddl('user',username) from dba_users where username='prod'; --执行导入命令: nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_01.dmp logfile=t_ca_tx_his_01.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_02.dmp logfile=t_ca_tx_his_02.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_03.dmp logfile=t_ca_tx_his_03.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_04.dmp logfile=t_ca_tx_his_04.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_05.dmp logfile=t_ca_tx_his_05.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_06.dmp logfile=t_ca_tx_his_06.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_07.dmp logfile=t_ca_tx_his_07.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append & nohup impdp \'/ as sysdba\' directory=public_dump dumpfile=t_ca_tx_his_08.dmp logfile=t_ca_tx_his_08.log cluster=no remap_tablespace=prod_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append &
注意:oracle 12c 以后的 impdp 的 transform 参数已经扩展为包括 disable_archive_logging 选项。该选项的默认值为 “n”,不会影响日志行为。将该选项设置为 “y”,这将会使表和索引在导入前将日指属性设置为 nologging,从而导入期间减少相关日志的产生,导入后再将日志属性重置为 logging。如果目标库有 adg、ogg 等其他复制软件在数据库级别开启了 force logging,那么“transform=disable_archive_logging:y” 参数将会无效,也会生成大量归档日志。
查看如下日志,导入最短 7 分钟,第二个 dmp 则需要 14 分钟,最后一个最长时间则需要 54 分钟,由此可见是串行导入的,这块并没有缩短时间。
# more t_ca_tx_his_02.log
;;;
import: release 19.0.0.0.0 - production on wed nov 29 17:50:49 2023
version 19.21.0.0.0
米乐app官网下载 copyright (c) 1982, 2019, oracle and/or its affiliates. all rights reserved.
;;;
connected to: oracle database 19c enterprise edition release 19.0.0.0.0 - production
master table "sys"."sys_import_full_04" successfully loaded/unloaded
starting "sys"."sys_import_full_04": "/******** as sysdba" directory=public_dump dumpfile=t_ca_tx_his_02.dmp logfile=t_ca_tx_his_02.log cluster=no remap_tablespace=prod
_scfop_tbs:cc_op_data remap_schema=prod:cc_op transform=disable_archive_logging:y table_exists_action=append
processing object type table_export/table/procact_instance
processing object type table_export/table/table
table "cc_op"."t_ca_tx_his" exists. data will be appended to existing table but all dependent metadata will be skipped due to table_exists_action of append
processing object type table_export/table/table_data
. . imported "cc_op"."t_ca_tx_his" 475.4 mb 189956 rows
processing object type table_export/table/grant/owner_grant/object_grant
processing object type table_export/table/comment
processing object type table_export/table/constraint/constraint
processing object type table_export/table/index/statistics/index_statistics
processing object type table_export/table/statistics/table_statistics
processing object type table_export/table/statistics/marker
job "sys"."sys_import_full_04" successfully completed at wed nov 29 18:45:39 2023 elapsed 0 00:54:44
job "sys"."sys_import_full_06" completed with 1 error(s) at wed nov 29 18:05:29 2023 elapsed 0 00:14:31
job "sys"."sys_import_full_04" successfully completed at wed nov 29 18:45:39 2023 elapsed 0 00:54:44
job "sys"."sys_import_full_07" completed with 1 error(s) at wed nov 29 18:32:05 2023 elapsed 0 00:41:05
job "sys"."sys_import_full_10" completed with 1 error(s) at wed nov 29 18:39:14 2023 elapsed 0 00:48:06
job "sys"."sys_import_full_05" completed with 1 error(s) at wed nov 29 18:12:09 2023 elapsed 0 00:21:12
job "sys"."sys_import_full_11" completed with 1 error(s) at wed nov 29 18:18:57 2023 elapsed 0 00:27:48
job "sys"."sys_import_full_08" completed with 1 error(s) at wed nov 29 18:25:49 2023 elapsed 0 00:34:48
job "sys"."sys_import_full_09" completed with 1 error(s) at wed nov 29 17:58:31 2023 elapsed 0 00:07:28
5、数据泵其他用法
expdp help=y expdp 参数 directory:用于转储文件和日志文件的目录对象。 dumpfile:指定导出备份文件的命名。 logfile:指定导出备份日志的命名。里面记录了备份中的信息。 full:导出整个数据库 (默认是n,就是默认只会导出登录用户的所有数据)。 schemas:要导出的方案的列表 (指定想要导出哪个用户下的数据)。 exclude:排除特定对象类型。(表名要大写) sample:要导出的数据的百分比。 tablespaces:标识要导出的表空间的列表。 version:指定导出数据库的版本,一般用于高版本数据库的数据要导入到低版本数据库中时用到。 parallel:更改当前作业的活动 worker 的数量。 reuse_dumpfiles:覆盖目标转储文件 (如果文件存在) [n]。 tables:标识要导出的表的列表。例如, tables=hr.employees,sh.sales:sales_1995。 query:用于导出表的子集的谓词子句。例如, query=employees:"where department_id > 10"。 job_name:要创建的导出作业的名称。 impdp参数 impdp help=y directory 供转储文件, 日志文件和 sql 文件使用的目录对象。 dumpfile 要从 (expdat.dmp) 中导入的转储文件的列表, logfile 日志文件名 (import.log)。 full 从源导入全部对象 (y)。 schemas 要导入的方案的列表。 exclude 排除特定的对象类型, 例如 exclude=table:emp。 job_name 要创建的导入作业的名称。 tablespaces 标识要导入的表空间的列表。 reuse_datafiles 如果表空间已存在, 则将其初始化 (n) parallel 更改当前作业的活动 worker 的数目。 query 用于导入表的子集的谓词子句。 version 要导出的对象的版本, 其中有效关键字为: tables 标识要导入的表的列表。 table_exists_action 导入对象已存在时执行的操作。 有效关键字: (skip)跳过, append附加, replace 替换和 truncate清空表后在添加。 remap_tablespace 将表空间对象重新映射到另一个表空间。 remap_schema 将一个 schema 中的对象加载到另一个 schema。 remap_table 将表名重新映射到另一个表。例如, remap_table=emp.empno:remappkg.empno。
数据泵常用导入导出语句
--data mining and real application testing options
--ude-00010: multiple job modes requested, schema and tables.
schemas 和 tables 不能同时出现。
--仅导出元数据表结构
nohup expdp \'/ as sysdba\' directory=public_dump schemas=dt_cc content=metadata_only exclude=statistics logfile=dt_cc0916.log dumpfile=expdp_metadata_only_dt_cc-2023-09-16_%u.dmp compression=all parallel=4 &
--sql语句
sql> select to_char(current_scn) from v$database;
to_char(current_scn)
----------------------------------------
14898415798
--导出某 schema 的数据
nohup expdp \'/ as sysdba\' directory=public_dump schemas=prod flashback_scn=14898415798 exclude=statistics logfile=expdp_prod0420.log dumpfile=expdp_prod_2022-04-20_%u.dmp compression=all cluster=n parallel=8 &
--导出某用户下以 t_price 开头的表。
nohup expdp prod/'rop_p98#' directory=public_dump logfile=prod_t_price63tables.log dumpfile=expdp_prod_t_price63tables.dmp tables=t_price% flashback_scn=9759642727 compression=all exclude=statistics parallel=4 cluster=no &
--按条件导出大表的一部分数据
expdp prod/'rop_p98#' directory=public_dump logfile=prod.t_auth_original.log dumpfile=expdp_prod.t_auth_original.dmp tables=t_auth_original compression=all query="where digest_time '>=' to_date\('2023-01-01','yyyy-mm-dd'\)"
--使用 parfile 导出表的一部分数据
expdp scott/tiger directory=exp_dir parfile=emp_main.par
vim emp_main.par
tables=emp_main
dumpfile=emp_main.dmp
logfile=emp_main.log
query="where sendtime between to_date('20220101','yyyymmdd') and to_date('20220401','yyyymmdd')"
--利用 sqlfile 参数生成创建索引,触发器,约束的 sql 语句,该参数可以用于 impdp,主要作用是未真实在目标端执行导入的情况下,生成 sql 文件包含该 dmp 文件的所有 ddl 语句,使用语法为
impdp \'/ as sysdba \' directory=public_dir dumpfile=expdp_full_t2_cc_2022-10_17_%u.dmp logfile=t2_index.log sqlfile=t2_cre_index.sql include=index include=trigger include=constraint
nohup impdp \'/ as sysdba\' directory=expdp_dir dumpfile=expdp_prod-2021-08-17_%u.dmp parallel=4 logfile=impdp_prod_081720.log logtime=all transform=disable_archive_logging:y &
注意:在不管是非归档还是归档情况下使用 disable_archive_logging 都会减小导入时间,减少归档量,但是需要注意如果数据库是 force logging 情况下,disable_archive_logging 参数会无效。
--导入到其他用户
nohup impdp \'/ as sysdba\' directory=public_dump logfile=impdp_d2_cc0826.log dumpfile=expdp_prod_cc-2021-08-25_%u.dmp remap_schema=prod_cc:d2_cc remap_tablespace=cc_data:d2_cc_data,cc_index:d2_cc_index parallel=4 &
--查看表的统计信息
sql> alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
sql> select table_name,owner,num_rows,last_analyzed from dba_tables where table_name like 'act_ge_%' and owner='op_demo';
--收集用户统计信息
sql> exec dbms_stats.gather_schema_stats('op_demo')
sql> exec dbms_stats.gather_schema_stats(ownname => 'd5_cc',options => 'gather auto',estimate_percent => dbms_stats.auto_sample_size,method_opt => 'for all columns size repeat',degree => 5)
--只导出表结构和数据,排除索引和统计信息
nohup expdp \'/ as sysdba\' directory=public_dump schemas=prod exclude=statistics,index logfile=prod0712.log dumpfile=onlydata_expdp_prod-2021-07-12_%u.dmp compression=all parallel=4 cluster=n &
--导入用户元数据
impdp \'/ as sysdba\' directory=dump_dir logfile=new_imp_t2_app.log dumpfile=t2_app-2021-05-31_new.dmp remap_schema=t2_app:t1_app remap_tablespace=t2_app_tbs:t1_app_tbs
--直接导入
nohup impdp \'/ as sysdba\' directory=expdp_dir dumpfile=expdp_prod-2021-08-16_%u.dmp parallel=4 logfile=impdp_prod_0817.log logtime=all transform=disable_archive_logging:y &
--使用 dblink 不落地导入
nohup impdp system/oracle_19c@test directory=expdp_dir network_link=prod_link flashback_scn=9010004930 exclude=statistics parallel=4 cluster=no schemas=prod,prod_cc logfile=impdp_prod.log logtime=all transform=disable_archive_logging:y &
注意:logtime=all,oracle 12c 以后的新参数,记录导入导出的时间,将时间信息输出到控制台和日志里。
--导出序列
sql> select ' create sequence '||sequence_name|| ' increment by '|| increment_by ||' start with '||last_number||' maxvalue '|| max_value ||' cache '||cache_size||' order nocycle ;'
from user_sequences;
--导出序列
sql> select dbms_metadata.get_ddl('sequence',u.object_name) from user_objects u where object_type='sequence';
--导出序列
nohup expdp \'/ as sysdba\' directory=public_dump logfile=prod.log dumpfile=expdp_prod-2021-05-21_%u.dmp schemas=prod compression=all parallel=4 cluster=n &
nohup impdp \'/ as sysdba\' directory=public_dump include=sequence logfile=imp_d4_cc_seq.log dumpfile=expdp_prod_scfop-2021-07-09.dmp remap_schema=prod:d4_cc remap_tablespace=cc_data:d4_cc_data parallel=2 &
sql> select sequence_name from user_sequences;
--sql 大全 https://www.modb.pro/db/45337
导出部分数据
对一个数据量在 tb 级别的生产库做全库迁移费时又费力,但创建测试环境时,我们往往并不需要用到所有的数据,只需要使用部分数据进行功能性测试即可。对此,数据泵提供了两种方式用于导出部分数据,一种方式是 query,即按条件导出,类似于查询语句中的 where。例如,导出业务用户下每张表的前 5000 行数据,命令如下:
expdp \'/ as sysdba\' parfile=expdp.par vim expdp.par directory=expdir parallel=8 cluster=n dumpfile=jieke_%u.dmp logfile=jieke_1130.log schemas= ( 'prod', 'cc', 'app', 'prod_cc' ) query="where rownum<=5000"
另一种方式是 sample,即数据抽样百分比。针对全库、用户和表三种模式,我们可以在导出时使用此参数来进行设置,使用方法示例如下。导出 scott 用户下每张表 20% 的数据,命令如下:
导出 scott 用户下每张表格 20% 的数据,命令如下:
expdp \'/ as sysdba\' directory=expdir dumpfile=scott_data.dmp logfile=scott_data.log schemas=scott sample=20
导出 scott 用户下的所有表,但只对大表 emp 抽取 20% 的数据,命令如下:
expdp \'/ as sysdba\' directory=expdir dumpfile=scott_data.dmp logfile=scott_data.log schemas=scott sample=scott.emp:20
使用 attach 参数查看导入进度
impdp system/oracle attach=sys_import_schema_02
expdp prod/prod attach=sys_export_table_01
export: release 19.0.0.0.0 - production on wed nov 29 15:32:47 2023
version 19.15.0.0.0
米乐app官网下载 copyright (c) 1982, 2019, oracle and/or its affiliates. all rights reserved.
connected to: oracle database 19c enterprise edition release 19.0.0.0.0 - production
job: sys_export_table_01
owner: prod
operation: export
creator privs: false
guid: 0b46179e09764e60e06347dd000cb607
start time: wednesday, 29 november, 2023 15:00:39
mode: table
instance: jdb1
max parallelism: 1
timezone: 00:00
timezone version: 32
endianness: little
nls character set: al32utf8
nls nchar character set: al16utf16
export job parameters:
parameter name parameter value:
client_command prod/******** directory=public_dump logfile=prod.t_tx_his.log dumpfile=prod.t_his.dmp tables=t_tx_his compression=all cluster=n
compression all
trace 0
state: executing
bytes processed: 0
current parallelism: 1
job error count: 0
job heartbeat: 1851
dump file: /data/ora-share/prod.t_tx_his.dmp
bytes written: 57,344
worker 1 status:
instance id: 1
instance name: jdb1
host name: rac19c
object start time: wednesday, 29 november, 2023 15:01:48
object status at: wednesday, 29 november, 2023 15:01:48
process name: dw00
state: executing
object schema: prod
object name: t_tx_his
object type: table_export/table/table_data
completed objects: 1
total objects: 1
completed rows: 914,779
worker parallelism: 1
export> status
6、导入导出中常用 sql 语句
col job_name for a30
col owner_name for a20
col operation for a20
col job_mode for a20
col state for a20
select * from dba_datapump_jobs;
owner_name job_name operation job_mode state degree attached_sessions datapump_sessions
-------------------- ------------------------------ -------------------- ------------------------------ ------------------------------ ---------- ----------------- -----------------
system sys_import_schema_02 import schema executing 4 1 6
system sys_import_schema_01 import schema not running 0 0 0
查询该job涉及的对象:
col object_name for a30
select a.object_id, a.object_type, a.owner, a.object_name, a.status from dba_objects a, dba_datapump_jobs j
where a.owner=j.owner_name and a.object_name=j.job_name and j.job_name='sys_import_schema_01';
object_id object_type owner object_name status
---------- ----------------------- ------------------------------ ------------------------------ -------
110320 table system sys_import_schema_01 valid
查询的结果显示:是一个系统在导入时生成的表:
select owner,object_name,subobject_name, object_type,last_ddl_time from dba_objects where object_id=110320;
owner object_name subobject_name object_type last_ddl_time
------------------------------ ------------------------------ ------------------------------ ----------------------- -------------------
system sys_import_schema_01 table 2021-08-16 17:53:33
确定问题所在,接下来我们只需要删除impdp时产生的表:
drop table system.sys_import_schema_01 purge;
检查
select * from dba_datapump_jobs;
set line 200 pages 1000
col message for a86
col target for a35
select sid,serial#,target,start_time,elapsed_seconds,time_remaining,message,round(sofar/totalwork*100,2) "%_complete"
from v$session_longops
where 1=1
--and sid=2983
--and serial#=123
and time_remaining>0;
23c 中新出现的三个诊断数据泵性能的视图:
v$datapump_process_info --获取 datapump 进程信息
v$datapump_processwait_info --获取 datapump 进程等待信息
v$datapump_sessionwait_info --获取 datapump 会话等待信息
7、数据泵使用最佳实践
参考 oracle 公益课堂 b 站视频;
https://www.bilibili.com/video/bv1264y1b7a8
exp/imp expdp/impdp 的基本概念
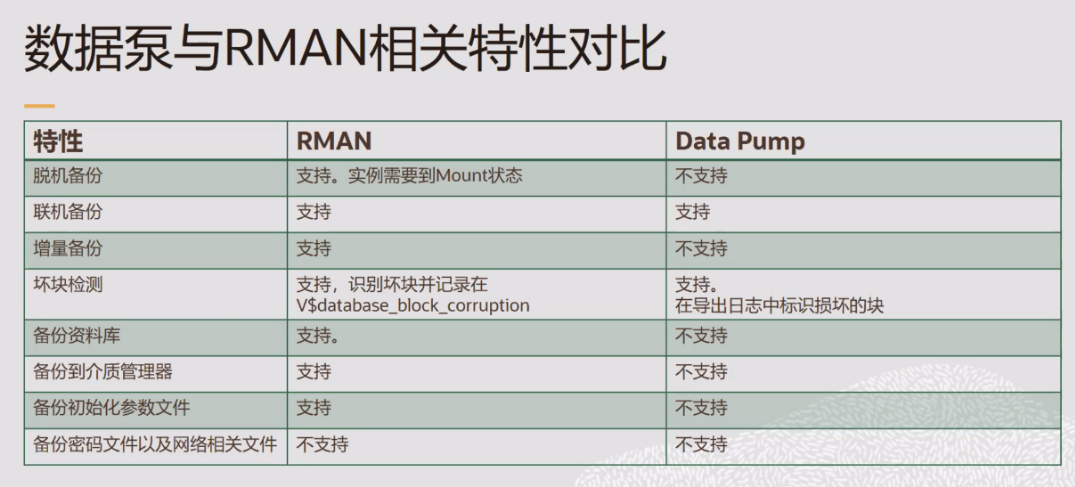
expdp 和 impdp 叫做数据泵(oracle data pump),是 oracle 10g 开始出现的导入导出工具,相对于数据泵 exp 和 imp 叫做传统导入导出工具(the original export and import utilities),一般来说,oracle 建议使用数据泵,因为他支持 oracle10g 之后的所有新特性,而传统导入导出工具不支持。这两种类型的导入导出工具都支持跨操作系统平台和跨 oracle 版本。
exp/imp expdp/impdp的主要区别
1)expdp/impdp 数据泵是服务端的工具,它只能在服务端使用而不能在客户端使用,也不能在 dg 库上使用
2)exp/imp 可以在服务端和客户端使用,也可以在只读的 dg 库上使用
使用传统导入导出工具的情况:
1、 需要导入由 exp 生成的文件
2、 需要导出将会由 imp 导入的文件,例如从 oracle 10g 导出数据,接着要导入到更低版本的数据库中。
oracle 数据泵技术可以非常高速的在两个库之间转移数据和元数据。这种技术只在 oracle10.1 和之后的版本可用。
数据泵组件
数据泵由三部分组成:
1、 命令行客户端(expdp 和 impdp)
2、 dbms_datapump 包 (也就是 data pump api)
3、 dbms_metadata 包 (也就是 metadata api)
命令行客户端与传统的 exp 和 imp 非常相似,但它是通过使用 dbms_datapump 包提供的过程执行导入导出命名。所有的数据泵执行过程都是在服务器端进行的,这意味着所有的非授权用户,需要让 dba 创建一个directory 来读写数据泵文件。对于授权用户,有一个默认的 directory 可以用。dbms_datapump 和dbms_metadata 包可以独立于 expdp、impdp 而独立使用,就像 oracle 的其他包一样。
导入导出传输模式
1)exp 导出分为表模式,用户模式,完全模式。分别对应导出表,导出整个用户下的对象,导出整个库下的所有对象
2)expdp 导出分为表模式、用户模式、数据库模式、可传输表空间模式
源库和目标库
1) 源库是指提供数据来源的数据库
2) 目标库是指需要将数据导入的数据库

19c 数据泵新特性
- 支持云对象存储作为数据加载的存储目标
- 可移动表空间的测试模式
- 允许表空间在 tts 导入期间保持只读状态
- 支持资源使用限制
- 在导入操作时排除 encryptionn 子句
- 支持对象存储文件的通配符







数据泵最佳实践



metrics
report additional job information to the import log file [no].
向导入日志文件[no]报告额外的作业信息。
logtime
specifies that messages displayed during import operations be timestamped.
valid keyword values are: all, [none], logfile and status.
指定导入操作期间显示的消息的时间戳。
有效的关键字值包括:all、[none]、logfile 和 status。






要想预估导出文件的大小,可以使用“estimate_only=y”选项运行expdp。
导入 oracle 12c 及以上版本时,建议搭配“transform=disable_archive_logging:y”参数,在归档模式下不生成归档日志。
对于数据泵,建议大家记住“expdp/impdp -help”命令。其中几个关键的参数用法如下。
·cluster:rac中默认为y,利用集群资源并行工作,建议关闭(cluster=n)。
·content:导出内容,默认为all,可以选择元数据[metadata_only]或仅数据[data_only]。
·include:导出/导入时指定的对象。
·exclude:与include互斥,导出/导入时排除的对象。
·network_link:远端数据库dblink连接。
·parfile:参数文件,避免在不同的操作系统下,因转义字符的不同而带来影响。
·query:特定对象筛选条件,类似于select中的where条件。
·sample:数据抽样比,一般用于搭建测试环境。
·sqlfile:对导入内容生成sql文本语句。
·remap_schema/remap_table/remap_tablespace:用于重定向目标端导入对象。
·compression:导出文件压缩,空间紧张时可以使用此参数,可以选择所有内容[all]、元数据[metadata_only]或仅数据[data_only]。
·partition_options:用于迁移分区表,none表示与源端保持一致,departition表示将每个分区表和子分区表作为一个独立的表创建,并使用表和分区(子分区)名字的组合作为自己的名字,merge表示将所有分区合并到一个表。
确认字符集是否一致,需要保证源库上的字符集和目标库上的字符集一样,否则expdp/impdp (exp/imp) 容易报告错误,并且丟数据。
select userenv('language') from dual;
userenv('language')
----------------------------------------------------
american_america.al32utf8
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【jiekexu dba之路】,第一时间一起学习新知识!
————————————————————————————
公众号:jiekexu dba之路
csdn :https://blog.csdn.net/jiekexu
墨天轮:https://www.modb.pro/u/4347
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————
