


互联网时代,数据的迅猛增长给数据库带来了可扩展性的挑战,gen ai 带来的数据暴增更加剧了这种挑战。传统的数据分片已经不能承载新时代数据暴增的需求,更简单且具有前瞻性的方法则是采用原生分布式数据库来解决扩展性问题。在这种规模化场景的背景下,tidb 的研发团队和开源贡献者们始终致力于解决事务一致性、数据持久性以及大规模扩展所带来的新挑战,以及保障关键应用的稳定性。
作为 tidb 7 系列的第二个长期支持版本 (lts) ,tidb 7.5 着眼于提升规模化场景下关键应用的稳定性。新版本中,tidb 在可扩展性与性能、稳定性与高可用、sql 以及可观测性等方面获得了持续的提升。tidb 7.5 lts 包含了已发布的 7.2.0-dmr、7.3.0-dmr 和 7.4.0-dmr 版本中的新功能、提升改进和错误修复,累计优化和修复功能 70 余项。本文将探讨 tidb 7.5 如何在规模化场景下实现关键应用整体稳定性的提升,探讨资源管控支持后端任务和管理资源消耗超出预期的查询(runaway queries)等重要特性,这些特性让用户可以在灵活调度资源降低总体成本的情况下可以保持关键应用的稳定性。
资源管控支持后段任务管理
提升执行关键业务的稳定性
tidb 7.1 引入的资源管控(resource control)特性,多个业务可共享同一个 tidb 集群,dba 可为不同的工作负载设置资源配额和优先级,例如为关键业务分配更高的优先级,确保其能够优先获得资源,避免受到其他工作负载的干扰。此前,资源管控无法对 ddl、analyze、import 等后端任务进行控制,这些任务通常定期或不定期触发,在执行的时候会消耗资源,从而对关键业务的运行产生影响。自 tidb 7.4 开始,资源管控支持后端任务管理。当一种任务被标记为后端任务时,tikv 会动态地限制该任务的资源使用,以尽量避免此类任务在执行时对前台任务产生影响。tikv 通过实时地监测所有前台任务所消耗的 cpu 和 io 等资源,并根据实例的总体资源上限计算出后端任务可使用的资源阈值,所有后端任务在执行时会受此阈值的限制。当后端任务被识别匹配后,资源管控会自动进行,即当系统资源紧张时,后端任务会自动降为最低优先级,以确保前台任务的执行效率。这个功能的增强允许 dba 通过设置自动识别后端任务,并降低其资源消耗。未来,这个功能将进一步扩展,提供给用户更丰富的配置选择,从而赋予用户对集群中后端任务更多的控制权。下表展示了当“analyze”后端任务以默认优先级和低优先级运行时对前台工作负载的影响对比:
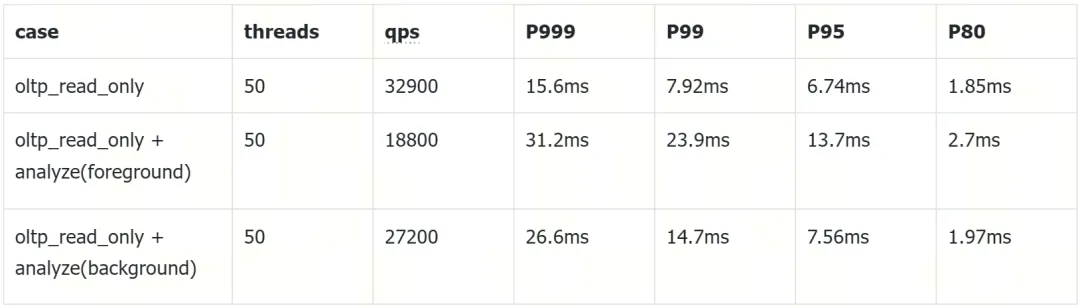
在上表的示例中,第一行展示了当所有集群资源均可供前台工作负载使用时的性能。第二行展示了在后台添加 “analyze” 任务时发生的情况。第三行则展示了利用新特性自动对 “analyze” 任务进行管控时的效果。
将后端任务(add index,import
into 任务)调度到指定的 tidb 节点执行
tidb 7.2 开始,引入了,该框架的目标是实现对所有后端任务的统一调度与分布式执行,并为接入的后端任务提供统一的资源管理能力。分布式框架支持后端任务(特指 add index 和 import into 任务)在 tidb 集群的所有 tidb 节点上执行,以提升此类任务的性能。而 tidb7.5 允许 dba 将 add index,import into 这类消耗资源较多的后端任务调度到指定的 tidb 节点上执行,从而和存量 tidb 节点上的负载进行隔离,避免对业务产生影响。当在想要运行后端任务的节点上设置 tidb_service_scope 为 background 时,后端任务分布式框架将调度该节点执行后端任务。但未经这样设置,则该节点将不会被用于执行后端任务。
这一改进真正的突破在于能够动态地添加 tidb 节点来处理突发的这类后端任务。如果需要导入一个庞大的表,只需向集群中添加若干个 tidb 节点来完成,而不会对现有 tidb 节点造成任何额外压力,添加索引的方式也是如此。完成任务后,这些节点可以被撤销。这一功能为在生产集群上轻松处理大型任务(add index ,import 大量数据)提供了更加无缝的方式
暂停和恢复执行 ddl 任务
在 v7.1 版本之前,用户在某些场景下会遇到 ddl 执行的痛点,具体表现为:
●集群版本升级时,若有正在执行的 ddl 未被取消,可能导致升级后的数据异常。
●对于拥有数十亿行数据的大表,为其添加索引可能需要相当长的时间,对在线业务造成不可忽视的影响。
为了解决这些问题,我们在 v7.1.0 中引入了一项新功能:ddl 任务的暂停和恢复。这一功能在 v7.5.0 中正式发布,为用户带来了更加灵活和高效的 ddl 执行体验。具体而言,该功能巧妙地解决了上述痛点:
●在使用 tiup 对集群升级的过程中,系统将自动暂停正在执行的 ddl 任务,并在升级完成后自动恢复执行该 ddl 任务。全程无需人为干预,有效避免由于人员疏忽导致未暂停 ddl 而引起集群升级后数据不一致的问题。
●针对执行耗时较长的 ddl,比如给大表添加索引,用户可以在业务高峰期来临前手动暂停该 ddl,并在业务低谷期恢复该 ddl 任务,从而有效避免对在线业务的影响。
ddl 任务的暂停和恢复机制支持断点续传,不仅保障了 ddl 任务的安全性和稳定性,同时最大化地保证了用户数据一致性和业务的稳定性。
监控和管理资源消耗超出预期的查询
突发的查询性能下降,是影响数据库整体性能最常见的问题,很难完全规避。即使设置了资源组限额,也只能消除资源组间的相互影响,而个别 sql 的过渡消耗仍会对降低资源组内的其他操作的性能。为解决此问题,tidb 7.2 资源管控引入了对 runaway queries 的管理,自动识别并处理消耗超出预期的查询,在 tidb 7.3 引入了手动管理 runaway queries 监控列表的功能,将 sql 特征添加到隔离监控列表,从而实现快速隔离 runaway queries。无论用户是否使用了资源组,都可以借助 runaway queries 管理来缓和突发的 sql 性能问题。dba 现在可以为每个资源组设置“查询限制 (query limit)”,并配备几个关键参数。exec_elapsed 用于设定查询持续时间的阈值,任何超出这一阈值的查询都会被识别为 runaway query。action 决定当识别到 runaway query 时进行的动作,可以把执行优先级降到最低也可以终止该查询。watch 用于快速匹配已经识别到的 runaway query,即在一定时间内再碰到相同或相似的查询,可以直接按照配置的措施进行处理,避免其在被识别的过程中对资源进行消耗。如果一些 runaway queries 并没有被自动识别,dba 也可以通过 sql 命令 "query watch"手动将查询的特征加入“监视列表”,类似于设置数据库级别的 sql 黑名单,特别适合那些对数据库响应时间要求很高的客户,为突发的 sql 性能问题提供了一种有效的防范措施。这项功能和资源管控结合使用,意味着在业务系统之间以及业务系统内部都能实现更高的稳定性,从而最大限度地减少多业务合并过程中可能出现的潜在风险。
立即体验 tidb 7.5
从 tidb 7.0 开始,tidb 在数据库整合的技术方向上持续演进,致力于在多业务融合的场景下同时提升关键业务的稳定性和降低总体成本,7.5 lts 将资源管控、分布式框架、可观测性理念的组合推升到更为成熟的阶段,可以为当前追求业务连续性同时也希望降低总体成本的客户带来创新的部署和运维方式。
您可或文末【阅读原文】浏览 tidb 7.5 release notes ,了解更多新增和优化特性。
👇点击下图,立即咨询 tidb 企业版👇