

oracle 数据库的运行不可避免的会遇到各种各样的错误,就比如数据表出现坏块,此时,你这张表的数据就无法访问了,有什么好的办法可以恢复呢?
什么,你没有遇到过?😱
😏 那就祝你不久的将来遇到,哈哈开个玩笑~ 玩归玩,闹归闹,经验必须要老到!👍🏻
今天就给大家讲讲怎么处理数据表的坏块情况!
对于 oracle 数据块物理损坏的情形,通常可以分为两种情况:
- 有备份,通过 rman 恢复
- 无备份,通过 dbms_repair 修复
1、rman
有备份的情况下,这是很理想的情形,我们可以直接通过 rman 块介质恢复(block media recovery)功能来完成受损块的恢复。
这里我是不建议恢复整个数据库或者数据库文件来修复这些少量受损的数据块,有点浪费时间。
可参考官方文档:
2、dbms_repair
那如果没有任何备份怎么办? (ps:备份大于一切!)
我们可以使用 oracle 自带的 dbms_repair 包来实现修复。
📢 注意: 使用 dbms_repair 包来修复,并非完全恢复,而是标记坏块,然后不对起进行访问,这部分被标记的数据也就丢失了,这是无法避免的。
可参考mos文档:
1、环境安装
使用我编写的一键安装脚本创建:
cd /volumes/dba/voracle/github/single_db
vagrant up
vagrant ssh

2、测试数据准备
创建表空间:
create tablespace eason datafile '/oradata/orcl/eason.dbf' size 1g autoextend on;

创建用户:
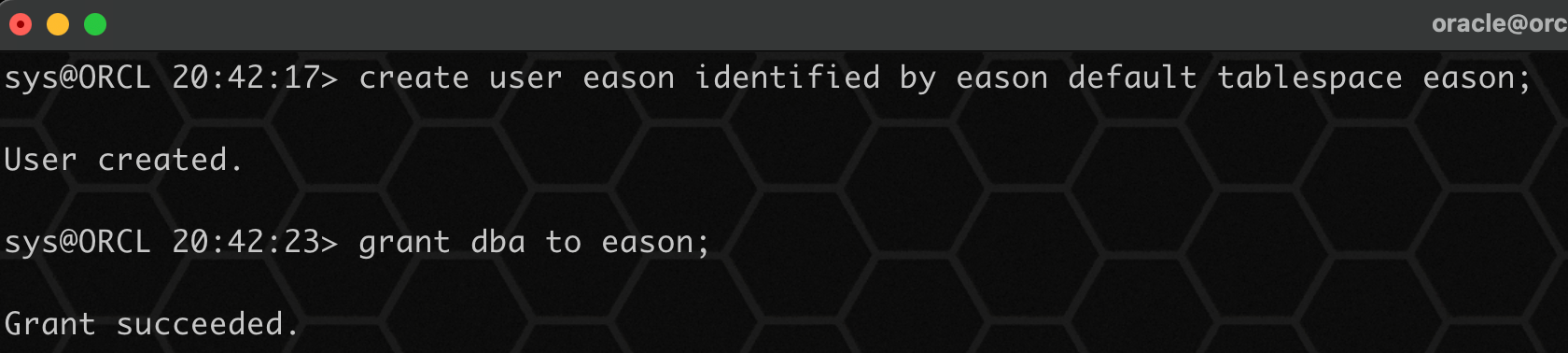
create user eason identified by eason default tablespace eason;
grant dba to eason;
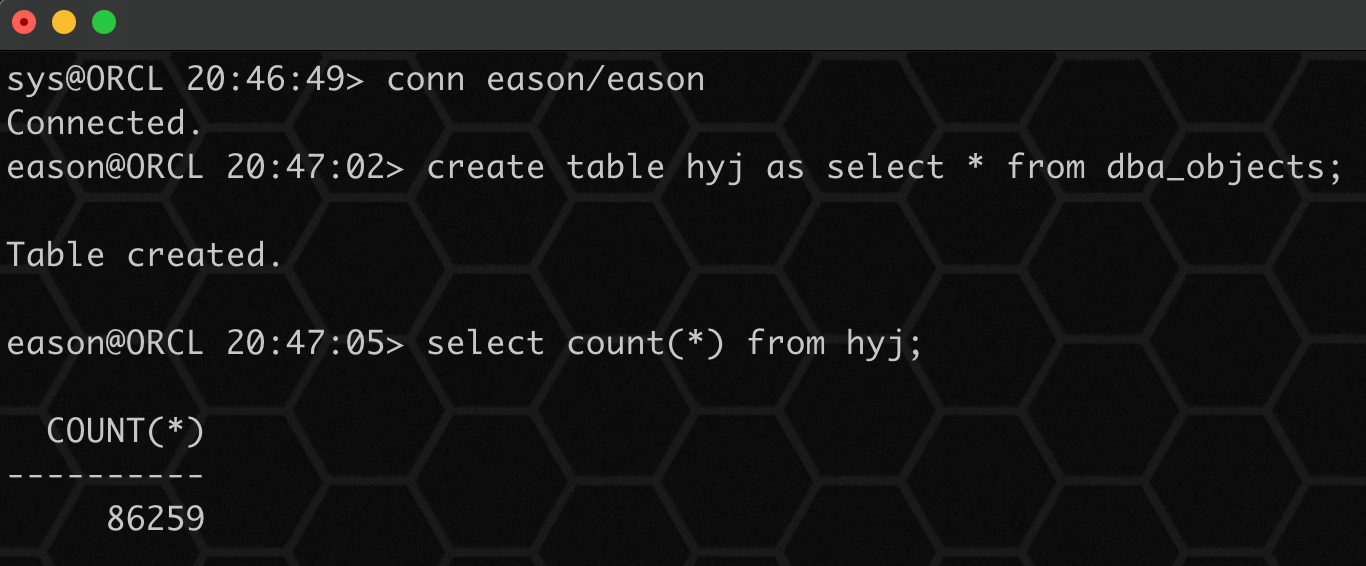
创建测试表:
create table hyj as select * from dba_objects;
创建表索引:
create index i_hyj on hyj(object_id);

3、查看表相关信息
查看表段上的相关信息:
select segment_name , header_file , header_block,blocks from dba_segments where segment_name ='hyj';

查出包含行记录的数据块:
select distinct dbms_rowid.rowid_block_number(rowid) from eason.hyj order by 1;
dbms_rowid.rowid_block_number(rowid)
------------------------------------
1411
1412
1413
...
...
...
2665
2666
2667
1232 rows selected.

select * from dba_extents where segment_name='hyj';
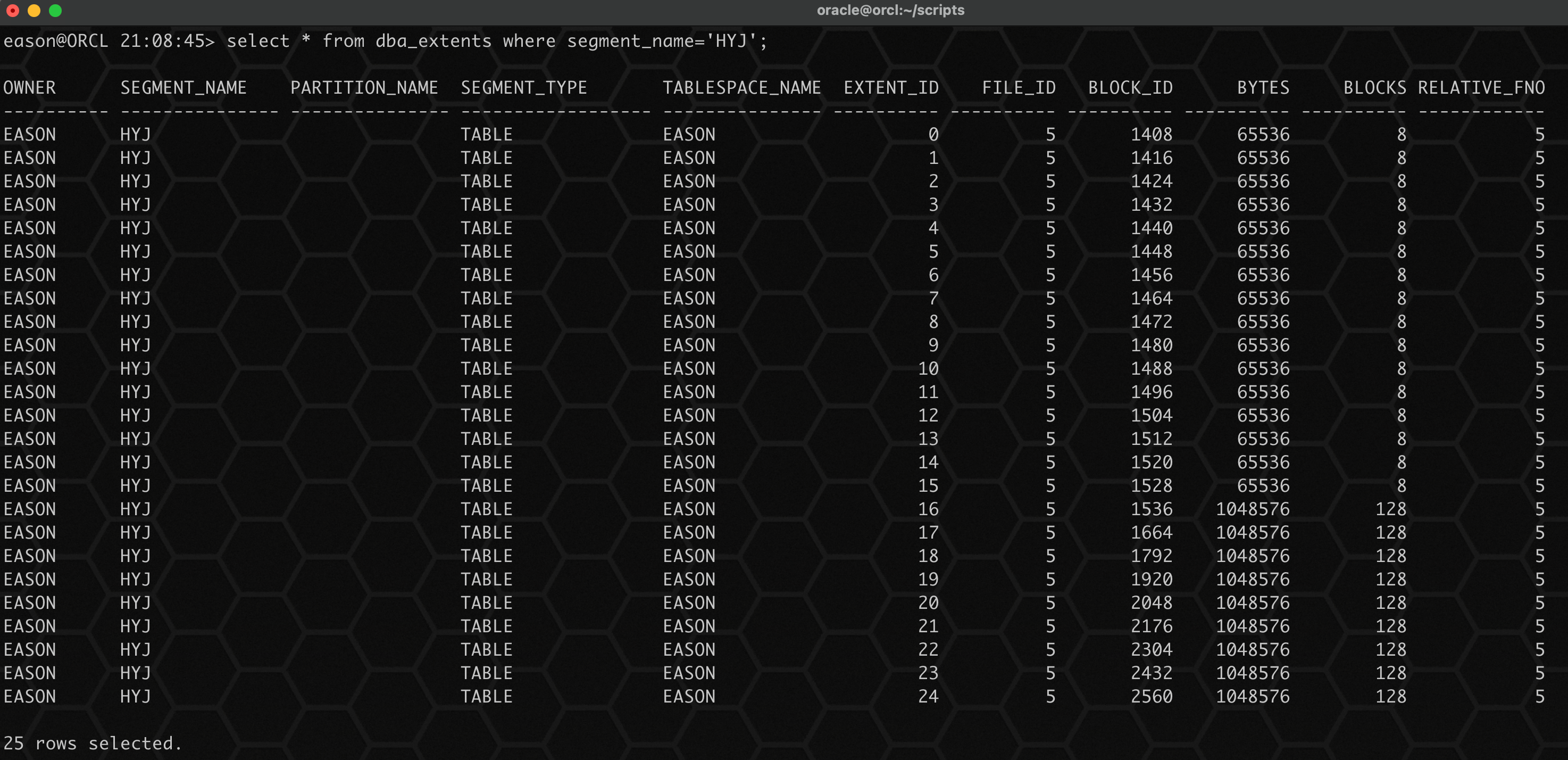
📢 注意: 这里看到 header_block 和 block_id 不一致,其实一个 segment 的第一个区的第一个块是 first level bitmap block,第二个块是 second level bitmap block,这两个块是用来管理 free block 的,第三个块是 pagetable segment header,这个块才是 segment 里的 header_block。
4、rman 备份
首先,我们先做一个全备份,用来演示 rman 修复坏块!
run {
allocate channel c1 device type disk;
allocate channel c2 device type disk;
crosscheck backup;
crosscheck archivelog all;
sql"alter system switch logfile";
delete noprompt expired backup;
delete noprompt obsolete device type disk;
backup database include current controlfile format '/backup/backlv_%d_%t_%t_%s_%p';
backup archivelog all delete input;
release channel c1;
release channel c2;
}

5、模拟坏块
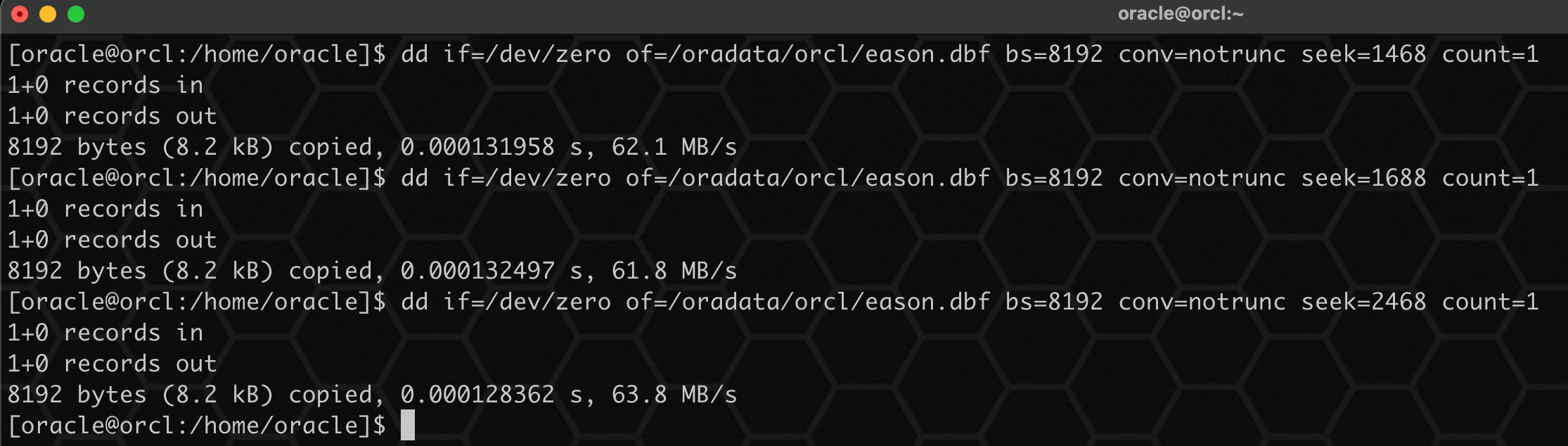
破坏 1468、1688、2468 数据块的内容:
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=1468 count=1
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=1688 count=1
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=2468 count=1
清除 buffer cache 的内容:
alter system flush buffer_cache;
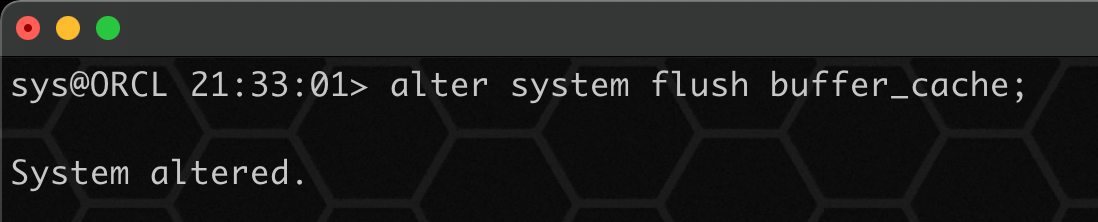
再次查询表 hyj,此时查询已经报错,发现有坏块:
select * from eason.hyj;
当然,也可以使用 bbed 进行坏块模拟!
6、坏块检查
下面在介绍几种发现坏块的方式:
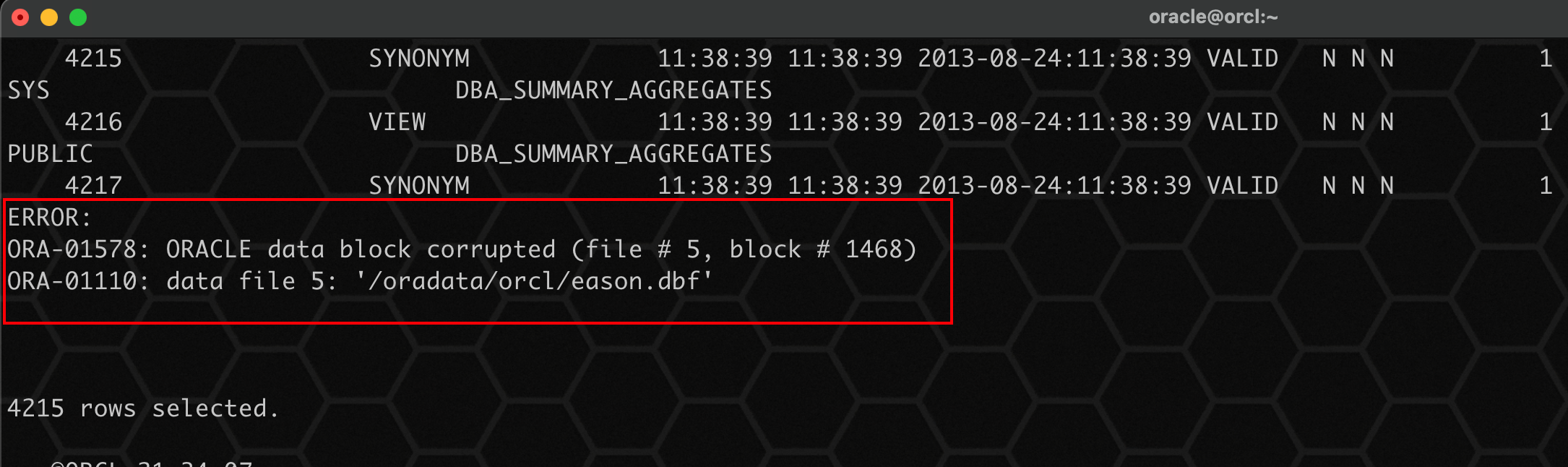
1、使用 dbv 检查当前文件的坏块:
dbv file=/oradata/orcl/eason.dbf blocksize=8192;
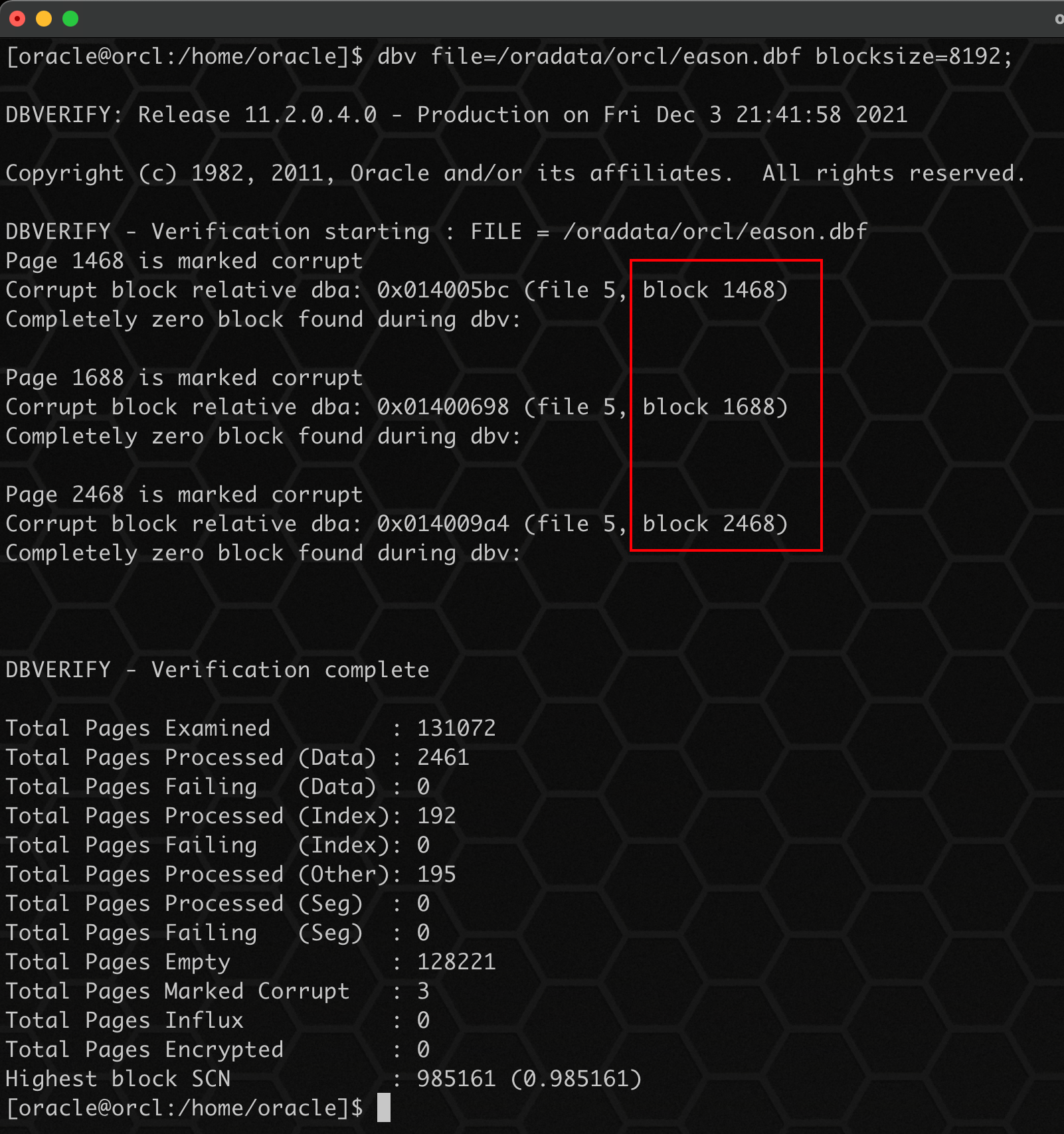
使用 dbv检查,同样发现了坏块!
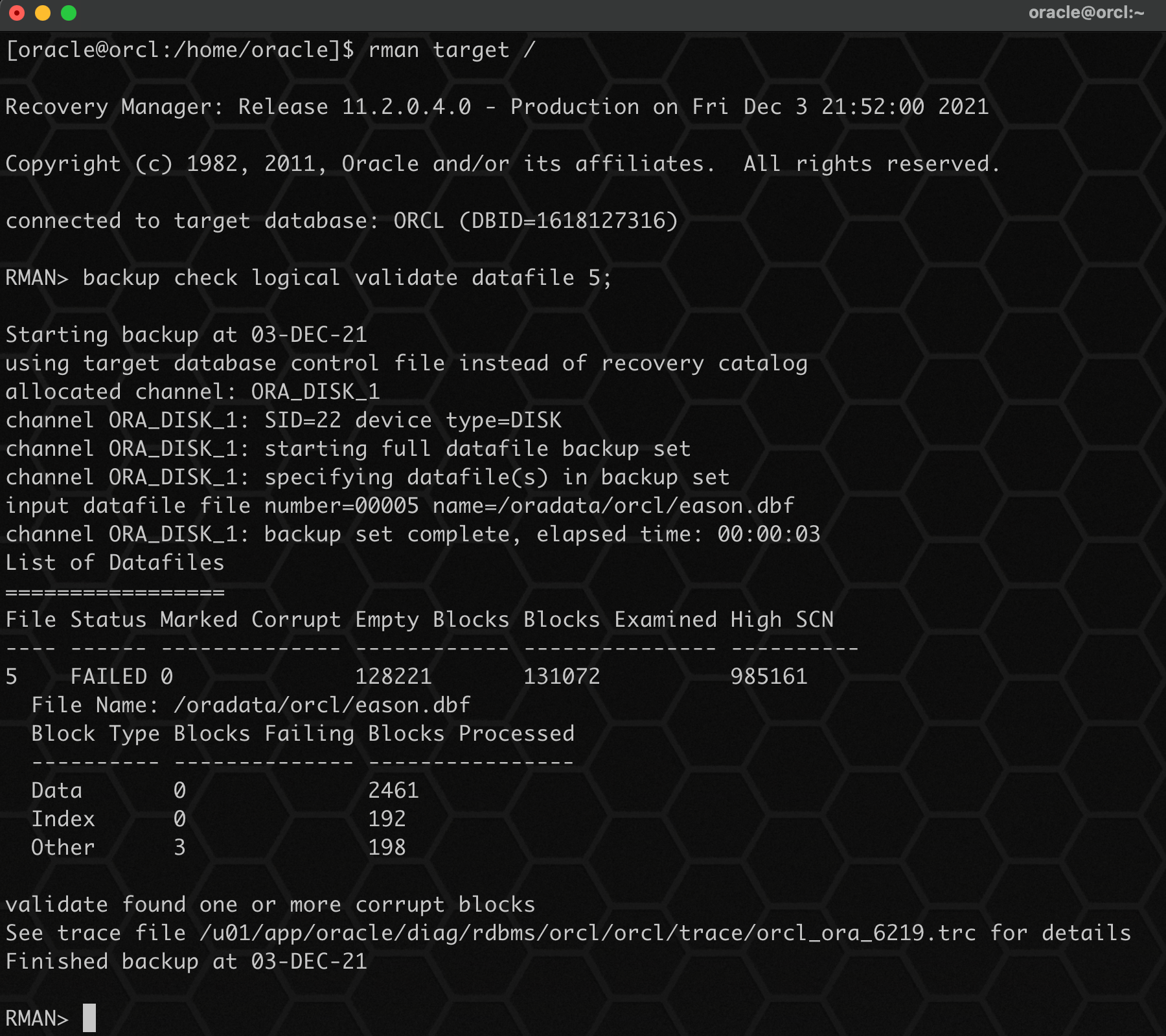
2、使用 rman 检查数据库坏块:
## 检查对应的数据文件
backup check logical validate datafile 5;
## 检查当前数据库
backup validate check logical database;
结合 v$database_block_corruption 视图查看,更加方便:
select * from v$database_block_corruption;

使用 rman 检查后,同样发现了坏块!
3、通过数据库的告警日志也可以发现报错:
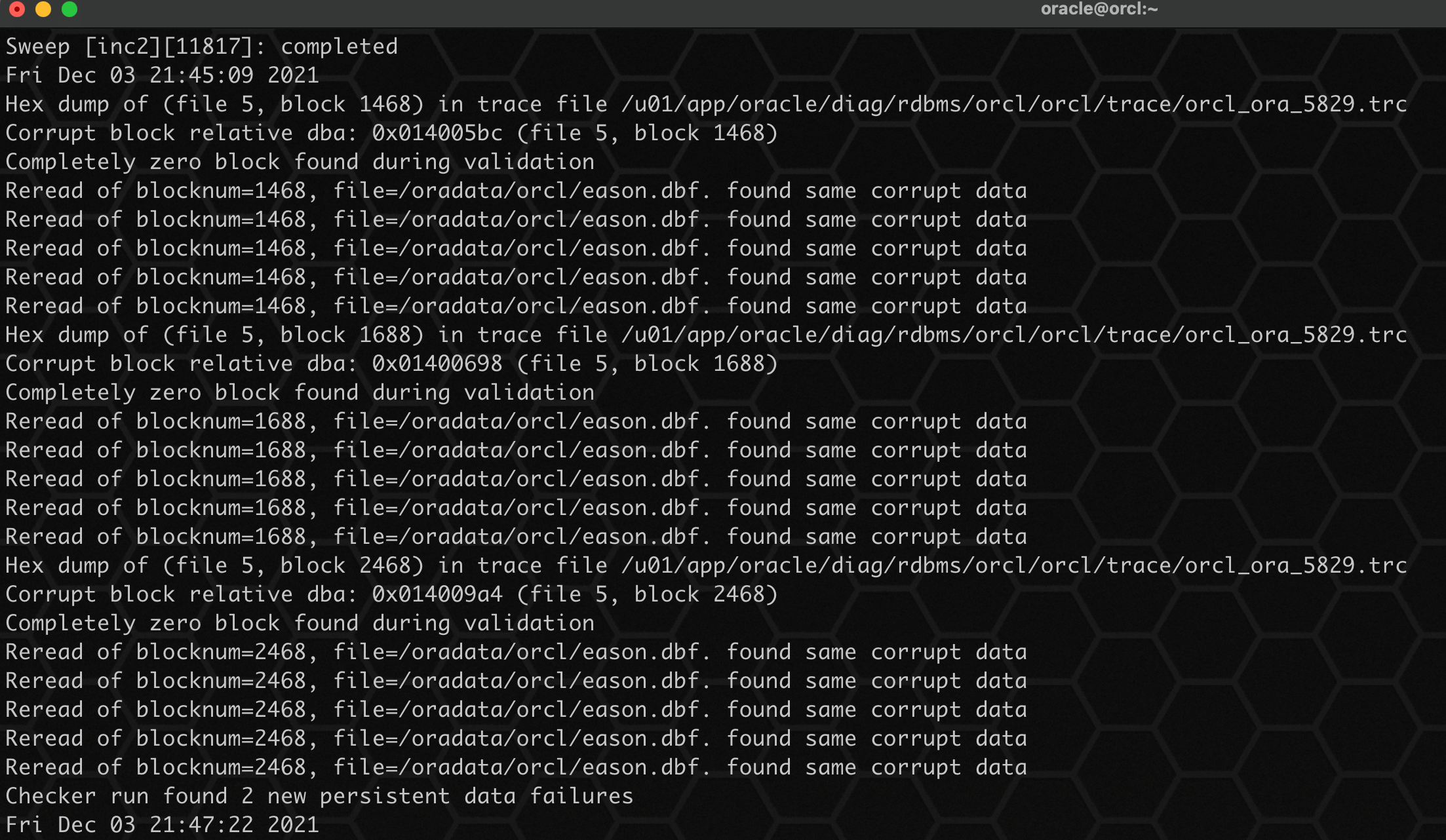
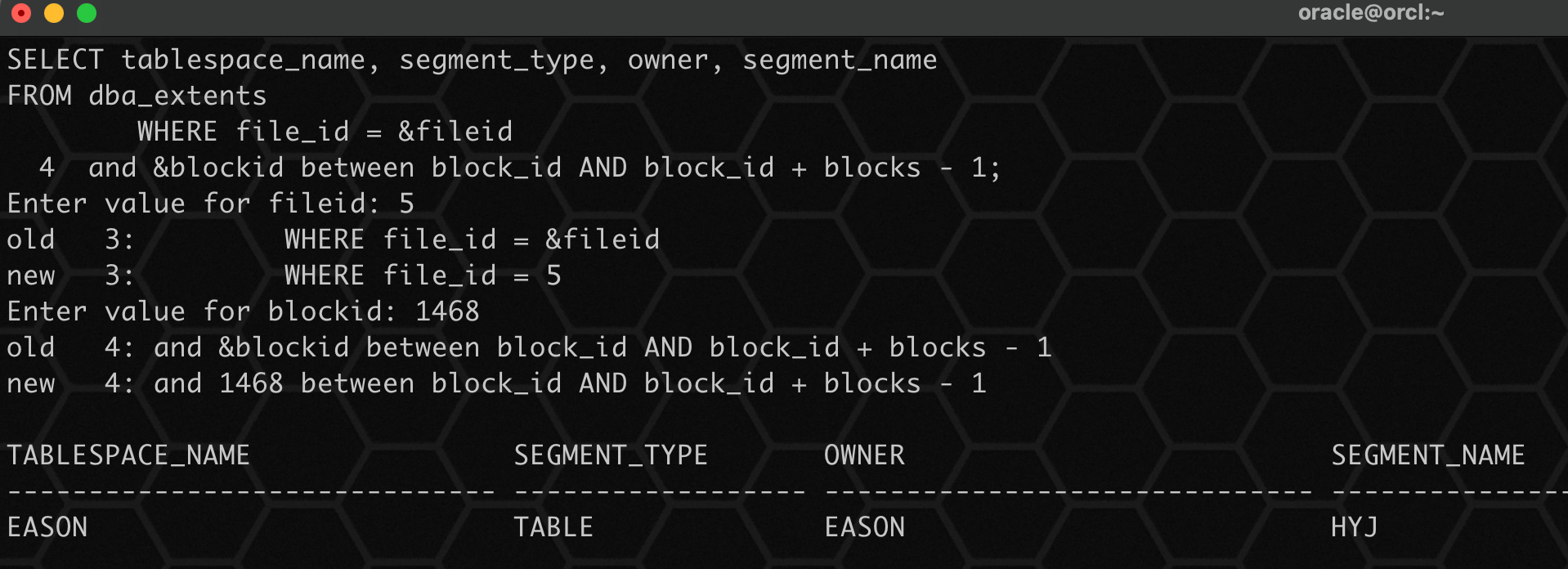
4、通过报错信息快照查找对应的坏表,依次填写数据文件 id 5 和 坏块 id 1468:
select tablespace_name, segment_type, owner, segment_name
from dba_extents
where file_id = &fileid
and &blockid between block_id and block_id blocks - 1;
实验环境准备完毕,下面开始实战!
今天,我打算使用上述介绍的 2 种方式来演示!
1、rman 修复
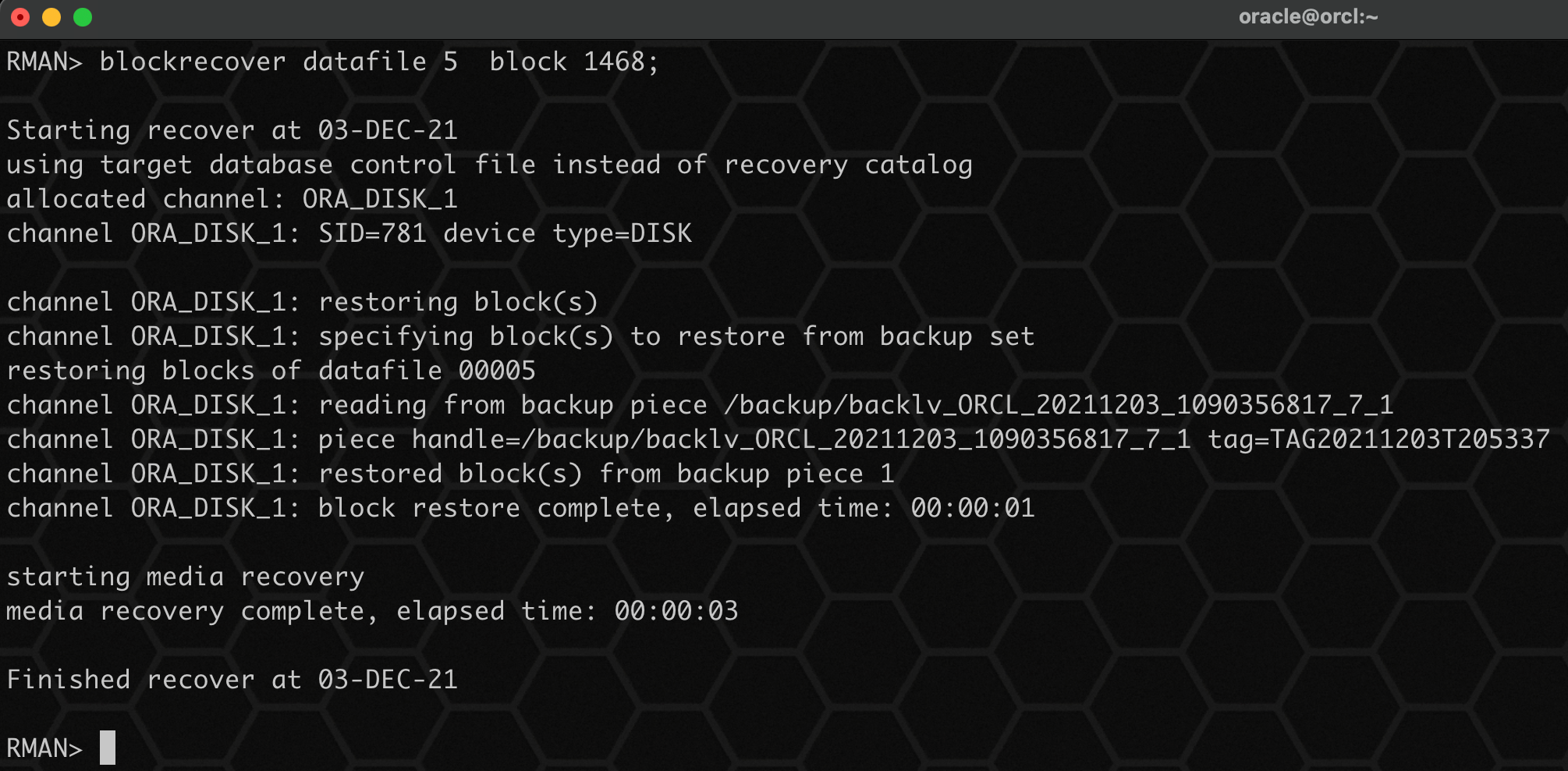
由于我们之前已经备份了,因此直接使用备份来恢复坏块:
blockrecover datafile 5 block 1468;
blockrecover datafile 5 block 1688,2468;
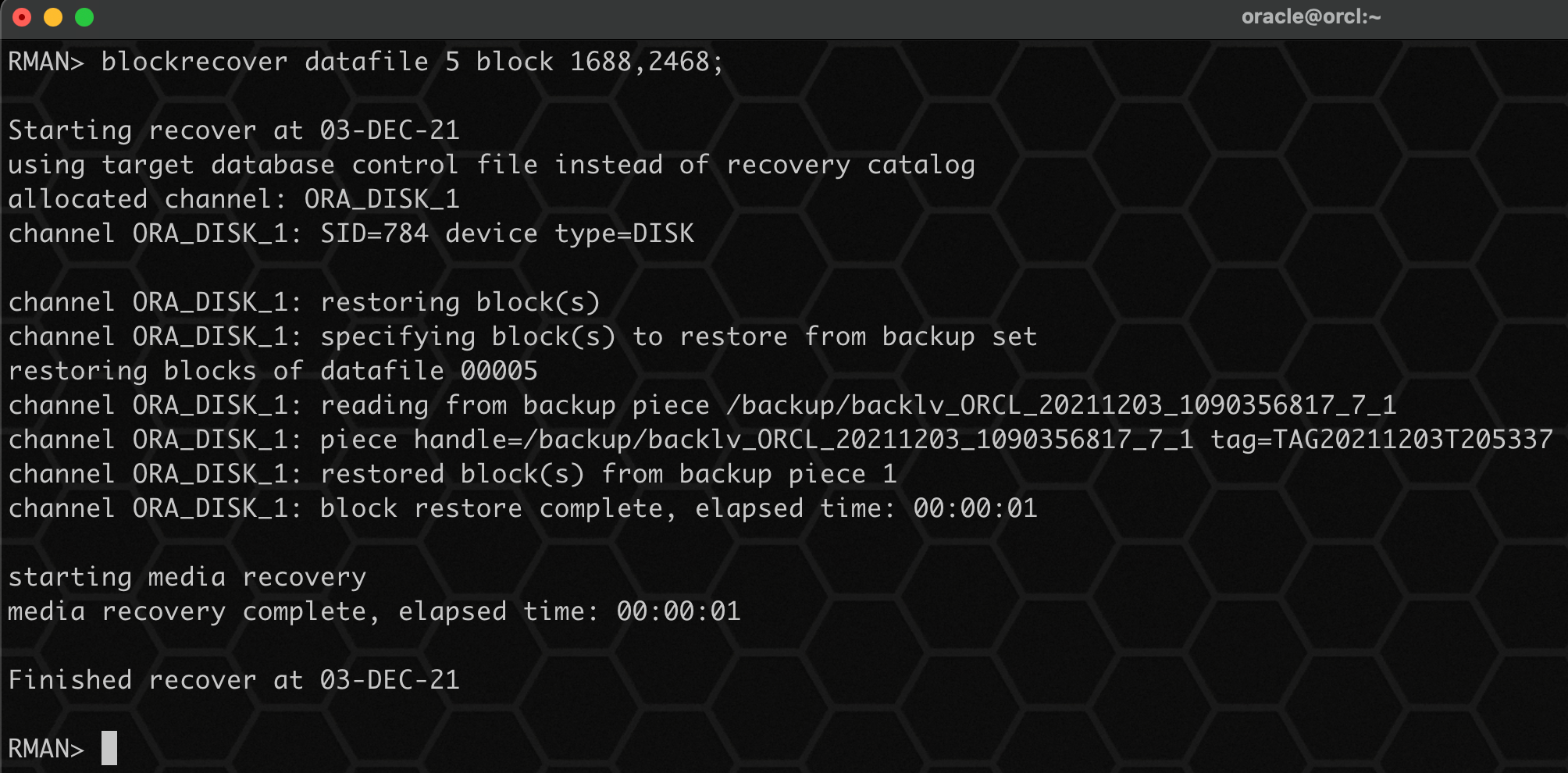
使用同样的方式,依次修复坏块 1688,2468,修复成功后,查询已恢复正常!
再次检查坏块情况:
backup validate check logical database;
select * from v$database_block_corruption;

坏块已经都被恢复,并且数据没有丢失!
2、dbms_repair 修复
首先,依然使用 dd 先模拟坏块:
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=3333 count=1
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=3368 count=1
dd if=/dev/zero of=/oradata/orcl/eason.dbf bs=8192 conv=notrunc seek=4000 count=1
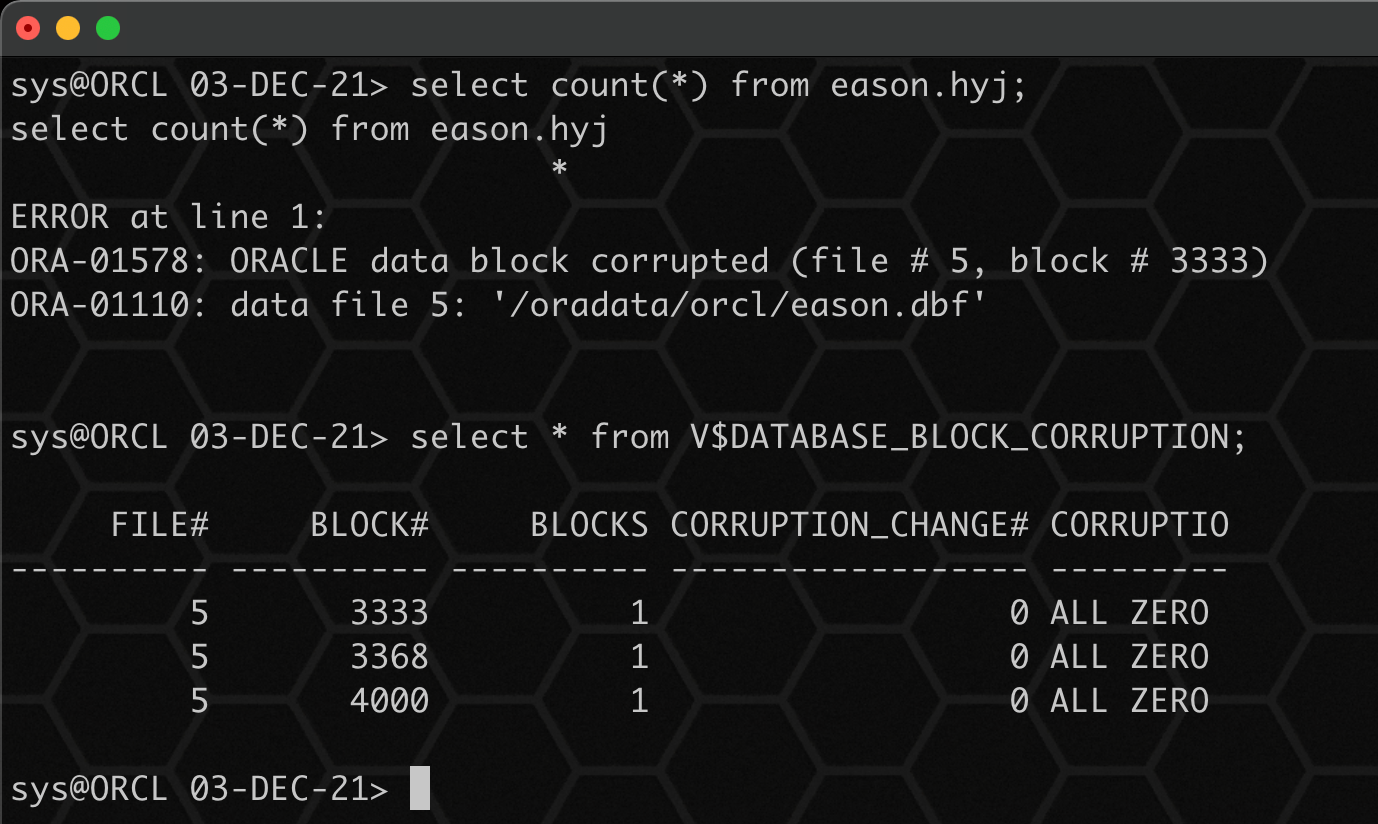
在没有备份的前提下,我们就无法做到无损修复坏块了,需要损失对应坏块的数据。
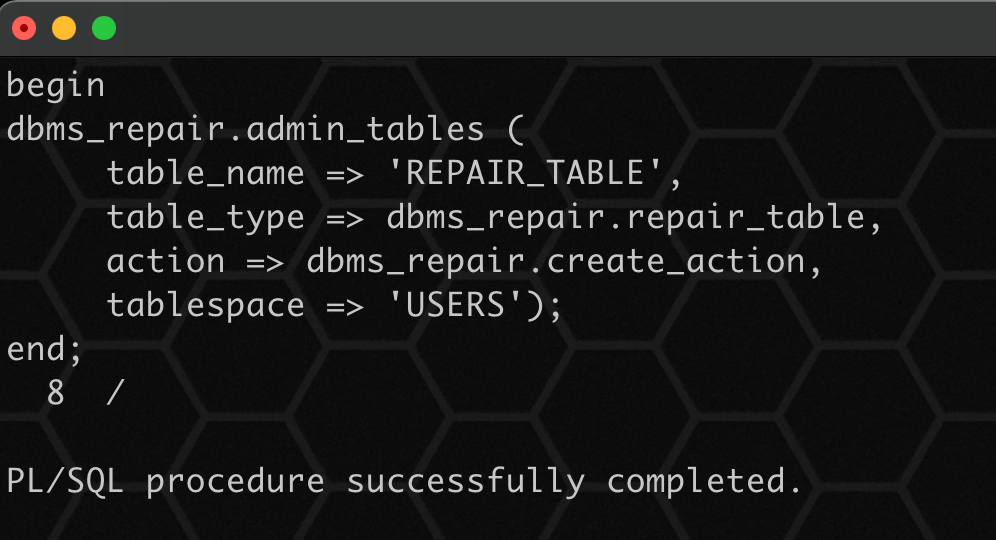
1、创建 repair 表,用于记录需要被修复的表:
begin
dbms_repair.admin_tables (
table_name => 'repair_table',
table_type => dbms_repair.repair_table,
action => dbms_repair.create_action,
tablespace => 'users');
end;
/
2、创建 orphan key 表,用于记录在表块损坏后那些孤立索引,也就是指向坏块的那些索引 :
begin
dbms_repair.admin_tables (
table_name => 'orphan_key_table',
table_type => dbms_repair.orphan_table,
action => dbms_repair.create_action,
tablespace => 'users');
end;
/

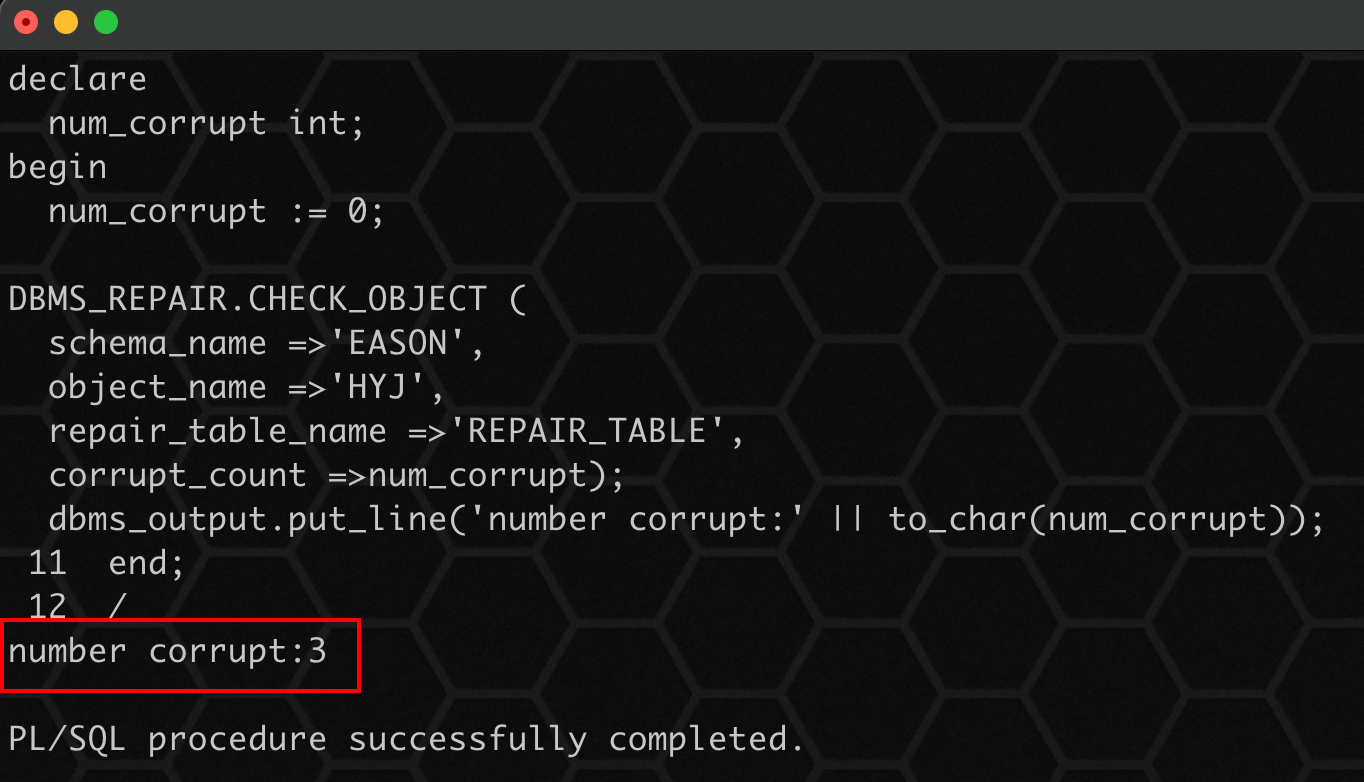
3、检查坏块,检测对象上受损的情形,并返回受损块数为 3:
declare
num_corrupt int;
begin
num_corrupt := 0;
dbms_repair.check_object (
schema_name =>'eason',
object_name =>'hyj',
repair_table_name =>'repair_table',
corrupt_count =>num_corrupt);
dbms_output.put_line('number corrupt:' || to_char(num_corrupt));
end;
/
4、查看受损的块信息:
select object_name, block_id, corrupt_type, marked_corrupt, repair_description from repair_table;

📢 注意: 这里 marked_corrupt 被标记为 true,应该是系统在执行 check_object 过程中自动完成了fix_corrupt_blocks。如果被标记为 false,需要再运行 fix_corrupt_blocks 来完成坏块的标记工作。
5、修复被损坏的数据块,这些被损坏的数据块是在执行了 check_object 之后生成的:
declare
cc number;
begin
dbms_repair.fix_corrupt_blocks(schema_name => 'eason',
object_name => 'hyj',
fix_count => cc);
dbms_output.put_line('number of blocks fixed: ' || to_char(cc));
end;
/
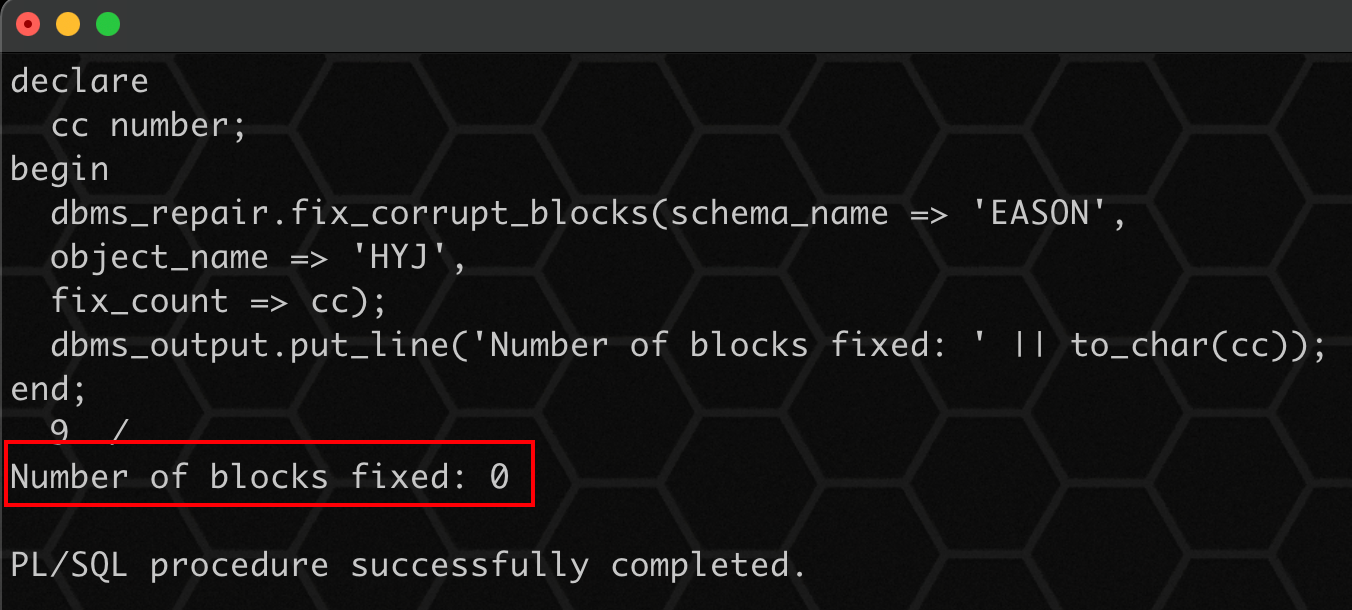
标记了 0 个坏块,说明 check_object 完成了标记工作。
6、使用 dump_orphan_keys 过程将那些指向坏块的索引键值填充到 orphan_key_table:
declare
cc number;
begin
dbms_repair.dump_orphan_keys
(
schema_name => 'eason',
object_name => 'i_hyj',
object_type => dbms_repair.index_object,
repair_table_name => 'repair_table',
orphan_table_name=> 'orphan_key_table',
key_count => cc
);
dbms_output.put_line('number of orphan keys: ' || to_char(cc));
end;
/
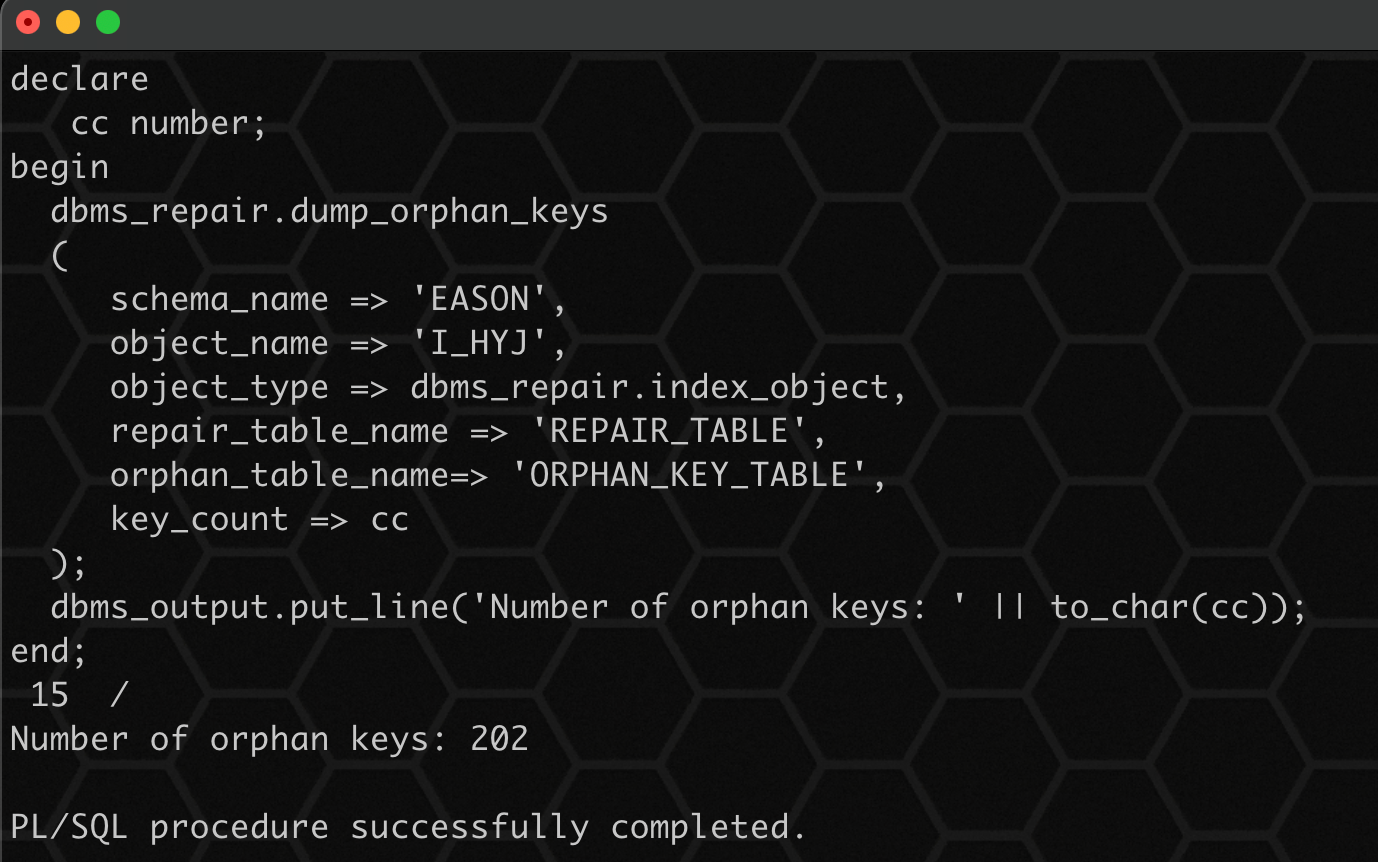
表明 202 条记录被损坏丢失!
📢 注意: 此处一定要注意 object_name 是索引名,而不是 table_name,这里 dump 的是损坏的索引信息.如果表有多个索引,需要为每个索引执行 dump_orphan_keys 操作。
7、验证对象是否可以查询,下面的结果显示依旧无法查询:
select count(*) from eason.hyj;
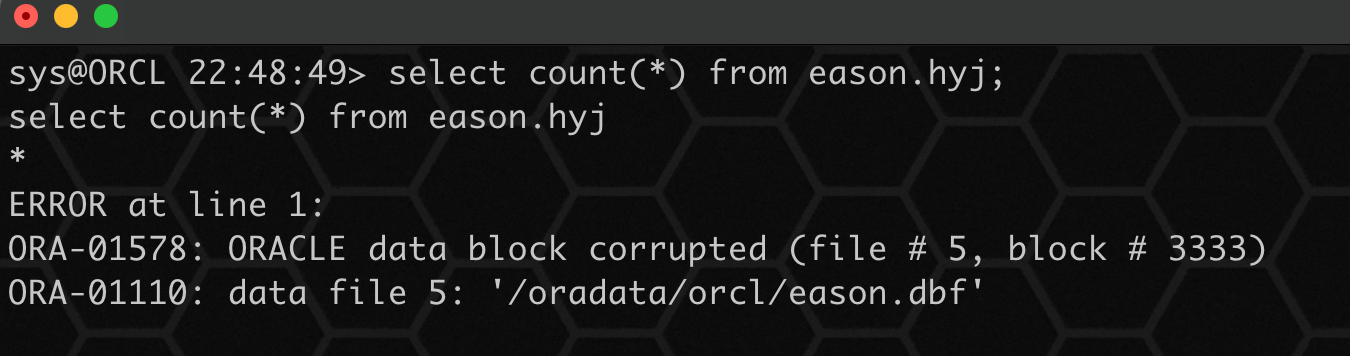
8、跳过坏块:
begin
dbms_repair.skip_corrupt_blocks (
schema_name => 'eason',
object_name => 'hyj',
object_type => dbms_repair.table_object,
flags => dbms_repair.skip_flag);
end;
/
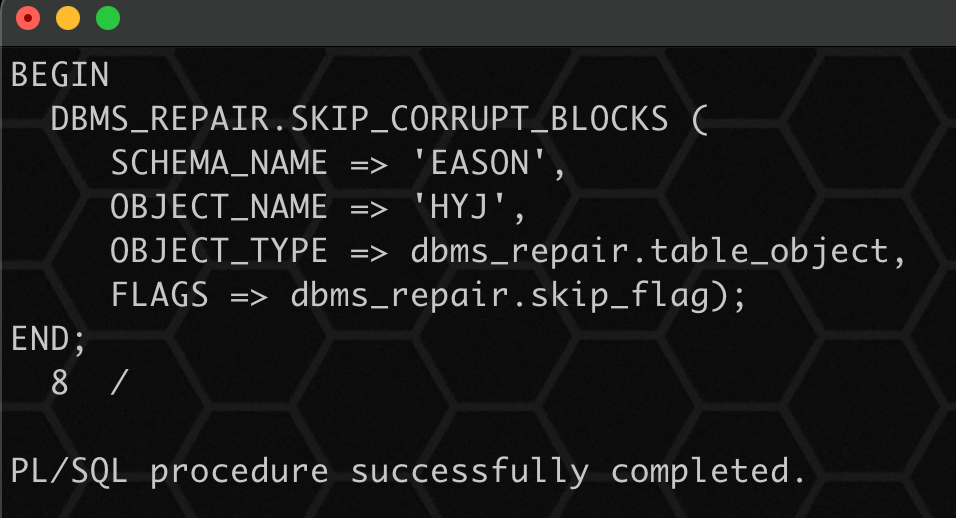
📢 注意: 丢失 202 条记录,丢失记录的 rowid 可以在 orphan_key_table 表中找到。
9、重建索引:
alter index eason.i_hyj rebuild;

10、验证结果
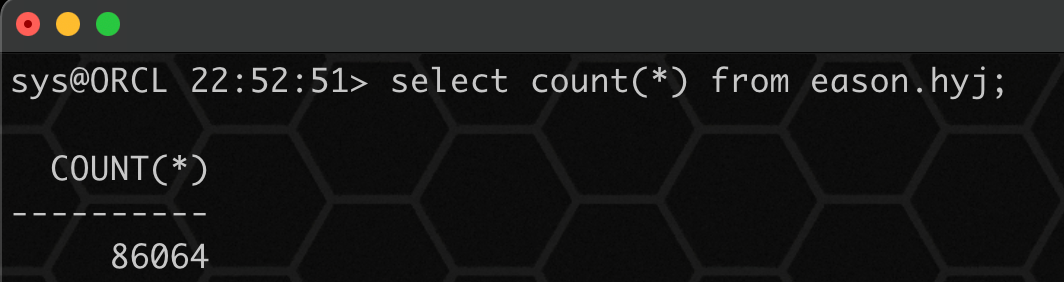
至此,表中数据可以顺利被访问!
由于坏块并没有消失,而是被标记跳过,因此还是可以查看坏块:
select * from v$database_block_corruption;
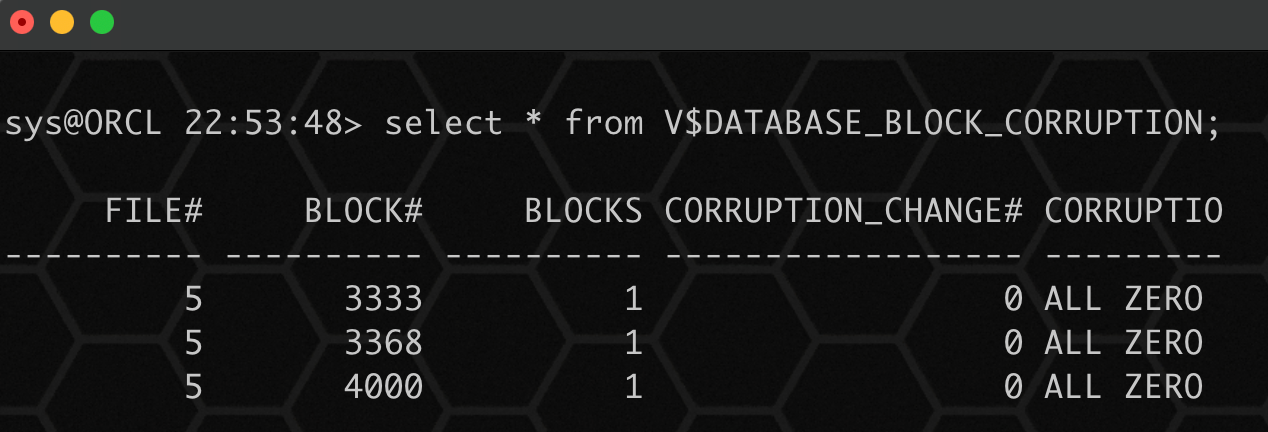
用这种方法可以找回部分数据,也可以找回建了索引的值,但是使用dbv再检查表空间的数据文件时,仍然会显示有损坏的数据块。
这时需要把表的数据全部导出,再重建表或者表空间,然后再把找回的数据导入数据库,推荐用 expdp/impdp 命令做,可以彻底消除 dbv 检查到的坏块。
备份大于一切,也是最后的防线,所以请大家一定要做好备份!886