

引入 | 图解那些分布式数据库中的dbms
开篇:想必大家都有一个疑问?何为分布式数据库?oltp,olap,htap?它又能够给我们带来什么?
背景:在数据库技术dbms领域,尤其是针对其中很多核心技术组成部分攻关的突破,国产化数据库一直都起着模范带头作用。许多国内互联网公司,包括现在很多成熟的技术框架,数据库都来自于国外。早期,依赖于核心技术的引进,在引进的基础上做上层应用,进而不断迭代。而现在核心技术自研,数据库自研等成了技术攻关的新浪潮。阿里曾一直提出“去ioe”的概念-其中ibm是服务器提供商,oracle是数据库软件提供商,emc则是存储设备提供商。
思考:
1、当使用k8、docker容器化编排技术受到限制,假若oracle、mysql数据存储等数据库软件不再向我们提供正常的服务?
2、在我们的项目工程中,若是没有了这些数据库技术去提供正常的服务,如何能够去及时地采取补救的措施,使得业务能够平滑过渡,做到让用户无感知体验?
3、从传统关系型数据库到非关系型数据库,nosql,newsql再到数据湖,以及兼顾olap跟oltp的各种分布式数据库-htap(混合事务/分析处理),在拥有自己的数据存储m6米乐安卓版下载的解决方案基础之上,现有技术框架体系是否能够较好适配,能否做到更好地兼容?
场景:在现有渠道产品上的适配,推进国产化数据库进程,包括信创自主可控等领域,都值得作为技术人的我们去深思......
诚然,技术多元化是一个趋势,多语言并存,多数据库适配,多环境兼容......
现状:,,架构
目前,在oracle中多个业务库中,数据规模已经非常庞大,mysql中多个业务库,其单表数据量都已超过千万级别,数据每天在不断的增长......
尤其,在许多老旧的项目中,oracle视图数据量非常大,dmp文件数百g,数据存储成本极其昂贵,这里也提供下大数据量的一些数据库导入导出方式(相比较工具导入导出或许速度更快一个数量级)
mysql:
备份数据库命令:
mysqldump -u root -p 数据库名 > /home/user/2021.12.26.sql;只需导出表结构:
mysqldump -u applyun -p -d bi > /home/applyun/bi.sql;数据库迁移导入:
mysql -u root -p 数据库名 < /home/user/2021.12.26.sql;oracle:
数据库迁移导入:
imp yd_dev_tmp/user@ip/orcl file=/home/oracle/xxx.dmp ignore=y full=y;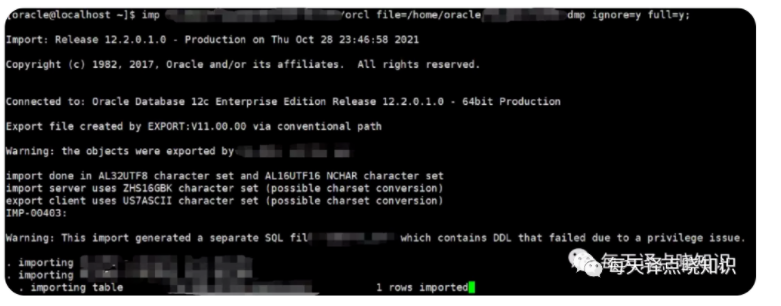
成功导入数据泵.dmp文件。(其中,可通过su - oracle进入oracle目录,dmp文件可上传到/home/oracle路径)
猜想:
当下的数据库技术体系,正如春秋时期百家争鸣的局面,已然无法像传统关系型数据库那样三足鼎立,各个大厂,尤其是互联网,根据其自身业务需求体系定制化了很多产品,像oceanbase,tidb,vertica,clickhouse,greenplum......
那么,拥有这么多的选择权,是不是意味着学习的成本会不断抬高,我们需要了解扩充的知识面更多?上述仅列举了正在项目中移植预研的几款dbms,更多详情请回顾->
构思:
当我们的业务系统发展到一定规模,不论是累计数据量,亦或用户并发量。早期,通过单体架构进行设计,应付自如,再大就是分库分表,解决数据库单点瓶颈(i/o)。
随着业务持续发展,单机有着明显的单点效应,并且单机的容量跟性能都是极其局限的。
进一步,对某些应用进行水平扩容,渐渐的,虽然各个应用服务器cpu都正常,但是你会发现还是有很多慢请求依然存在,究其缘由-单点数据库性能瓶颈?
更进一步,数据库集群-主从架构,大部分读操作可直接访问从库,减轻主库的负担,但依旧还是无法解决主库写的瓶颈?
接下来,就是上述提到的分库分表,分库分表可作水平拆分-对表进行进一步拆分,垂直拆分-不同功能表放置不同的库,按业务功能进行拆分。
然而,当相同的应用扩展越多,每个数据库的链接数,长久以往必会让数据库本身的资源再度成为瓶颈,简言之,资源隔离性依然不彻底->未形成单元化的雏形。

再谈经典,
google三驾马车,在分布式系统工程实践领域:
《google file system》、《google mapreduce》、
《google bigtable》在很大程度上奠定了业界大规模分布式存储系统的理论基础.
回到cap理论,想必在分布式领域中这个著名的定理都有所耳闻,即c为数据一致性,a 为服务可用性,p为服务对网络分区故障的容错性。
谈及cap,这里暂不详赘,各有各自不同深度层次的见解,但这里需要说明下的就是选择cp的分布式系统,并不代表可用性就完全没有了,比如像我们常用的中间件,为了增加可用性保障,往往提供了分片集群-复制的一些方案。
包括常说的base理论-对cap理论的延伸,核心思想-即使无法做到强一致性(strong consistency),但我们的应用可以采用适合的方式达能够到最终一致性(eventual consitency)。
从上述提到由单点现状->分布式架构演进构思的过程中,出现诸多不同阶段性痛点,想必这也是为什么那么多分布式数据库产品如雨后春笋般不断涌出?
-中国第一款自主研发的分布式数据库(简称ob)
企业级分布式关系数据库
a)数据强一致
b)高可靠
分区-副本机制
c)高性能
paxos协议,在数据强一致的情况下,具有极高的可用性及性能
d)在线扩展
当集群存储容量或是处理能力不足时,可以加入新的observer
e)高度兼容sql标准和主流关系数据库
f)低成本
cpu、操作系统、数据库
如何既兼顾处理tp场景的能力,又具备ap场景的分析能力?
想必htap架构希望打破tp和ap的边界,虽然存在很多技术难关需要攻克,一直在路上,期待oceanbase(ob)一直会有新的突破......
延伸思考:htap(混合事务/分析处理),相比oltp、olap能够给我们带来?oceanbase又是如何支持htap?
在高并发海量数据场景下,是否能让系统中诸多计算节点同时运行oltp类型的应用和复杂的olap类型的应用......
「 往期文章 」
