

一、前言
先看一个比较有意思的案例
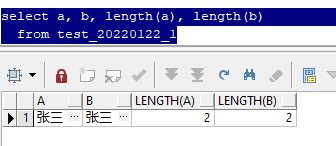
上面这个sql,查询了a和b两个字段,均为"张三"两个汉字,并且使用length函数检查,长度均为2。
但是,当你看到下面这几个sql的输出结果时,很有可能第一反应是:
"这特喵的怎么可能?"
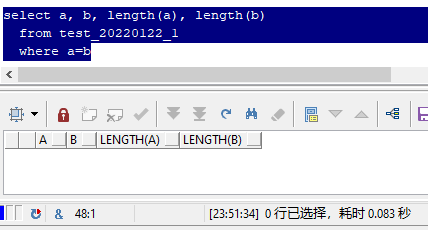
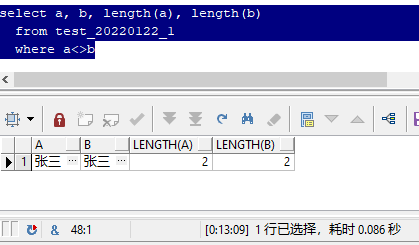
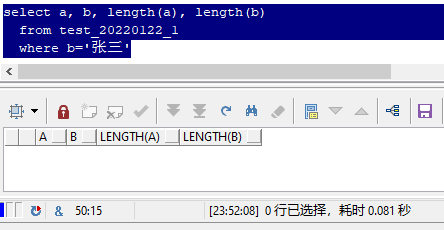
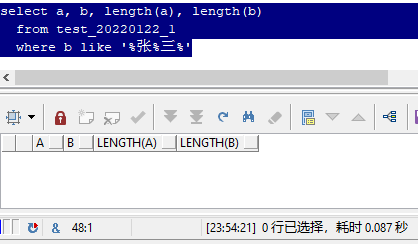
其实,你所看到的两个"张三",的确长得是一模一样,用显微镜去看也不可能看到区别。
但为什么a和b不相等呢?
这是因为组成他们的成分不一样,这个成分就是 字符集
二、什么是字符集?
简单来说,
字符(character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符集(character set)是多个字符的集合
众所周知,计算机系统底层是由二进制1和0组成的,而且这个1和0也不过是表示电信号的"通"和"断",根本就不存在任何字符。字符集其实可以理解为一个有索引的字典,根据指定的二进制数据,去查这个字典对应位置的字符是什么,然后从字符集里把这个字以选定的字体显示出来。
比如二进制数据"1011000010100001"(十六进制为"b0a1"),在gb2312字符集中,对应汉字"啊"。
就算是英文字母和数字,也同样也必须依赖字符集,比如二进制数据"1100001"(十六进制为"61"),表示小写字母"a",当然,目前几乎所有的字符集里,这个二进制数据都表示a。
所以,对于我们目前所有在用的计算机系统,如果要识别字符,必须使用这个字符的二进制数据去查某一个特定字符集,寻找对应的字符,如果找错了字符集,找到的可能就是乱码了。
三、oracle数据库的字符集
oracle数据库在安装时,会有个选项,选择数据库的字符集,这个大多数dba都知道,也不用多说。
但是目前很多人在通过网络上的文章去了解oracle字符集的时候,经常会被弄得一头雾水:
al32utf8是什么?为什么不是utf8?
环境变量里设置的simplified chinese_china.zhs16gbk是什么?为什么不直接设gbk?
在数据库里的各个视图里查到的字符集究竟是客户端的还是数据库的?
i.字符集代码
oracle中的字符集代码,并不等于目前通用的字符集名称。先来看看官方提供的
其实根据这个表格中的"description"可以了解到,目前这些通用的字符集名称都太长了,且毫无规则,不能作为代码使用;并且还存在一些特殊情况,比如"ja16euctilde"和"ja16euc"两种字符集,实际上都是"euc 24-bit japanese",只有波浪线不一样,就分成了两个字符集。
所以oracle必须自己再对这些字符集进行一次统一命名,因此有了"al32utf8"以及"zhs16gbk"这样的字符集代码
ii.nls_lang
在系统环境变量(或注册表)"nls_lang"中,经常会配置类似下面这样的值
simplified chinese_china.zhs16gbk
american_america.al32utf8
其实这个环境变量由3个部分组成
_.
即
语言_地区.字符集
只有最后一截才是真正表示字符集
所以"simplified chinese_china.zhs16gbk"表示:“简体中文”_“中国地区”.“16位gbk简体中文”
同理,"american_america.al32utf8"表示:“美式英语”_“美国地区”.“unicode12.1通用字符集utf-8编码方案”。
当然,在环境变量中,这3个并非全部必填,你甚至可以用 "_.al32utf8"表示使用数据库默认的语言和地区,但客户端使用你指定的字符集;用 "_america."只指定客户端地区,语言使用该地区的默认语言,字符集使用该地区默认语言对应的字符集。
---查询比利时地区的语言
declare
retval utl_i18n.string_array;
cnt integer;
begin
retval := utl_i18n.get_local_languages('belgium');
for i in 0..retval.count-1 loop
dbms_output.put_line(retval(i));
end loop;
end;
/
---查询法语的默认字符集
select utl_i18n.get_default_charset('french') from dual;
---从iso标准语言代码转换成oracle中的语言 和 地区
select utl_i18n.map_language_from_iso('en_us') ,
utl_i18n.map_territory_from_iso('en_us') from dual;
---将oracle语言 和 地区转换成标准iso标准语言代码
select utl_i18n.map_locale_to_iso('american','america') from dual;
实际用户场景中,一个地区可以不止有一种语言,一种字符集也可以表示多种语言文字。通过灵活配置这个环境变量,可以让数据库对各个地区的时区、语言、货币、文字等的兼容性更好。
但是,你可能又会问了:
不是都说要让数据库的环境变量和客户端的环境变量保持一致么?
对,没错,的确建议保持一致,但这并非绝对。目前多国家多语言的公司多得去了,在使用同一个数据库时,肯定会有不同的需要。
分三部分
a.语言
首先,对于语言,我们做个这样的测试:
- 数据库安装时,语言选择了"american",然后客户端环境变量的"nls_lang"设置成"simplified chinese_china.al32utf8",打开客户端软件,连接数据库后执行一段错误的sql
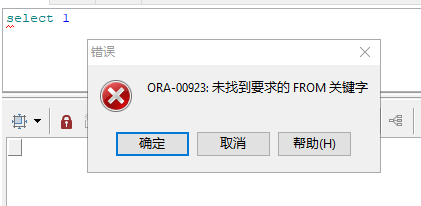
- 然后把客户端环境变量的"nls_lang"改成"american_china.al32utf8",并重新打开客户端软件,连接数据库后执行同样的sql
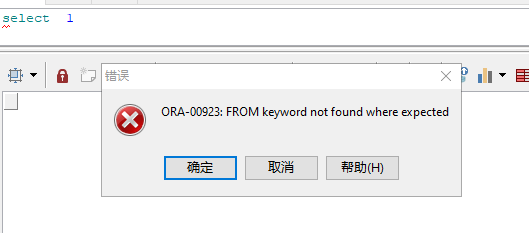
对,客户端环境变量的这个语言就是用来干这个的,用于在客户端显示不同语言的报错或者提示信息,你甚至可以设置成日语或者法语,这些系统提示信息在数据库内部本就是有记录多种语言的。另外,也可以通过数据库自带plsql包"utl_lms"将对应的系统提示信息转换成非客户端设置的语言。
declare
s varchar2(200);
i pls_integer;
begin
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'french', s);
dbms_output.put_line('法语 : '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'american', s);
dbms_output.put_line('美式英语 is: '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'simplified chinese', s);
dbms_output.put_line('简体中文 is: '||s);
end;
/
输出为:
法语 : type %d non pris en charge pour l’expression sql sur la colonne %s.
美式英语 : unsupported type %d for sql expression on column %s.
简体中文 : 不支持 sql 表达式类型 %d (位于 %s 列)。
当然,我们也得看目前的字符集是否支持当前语言,可参考官方文档
b.地区
对于地区,除了上面说过的,在没有设置语言的时候取地区的默认语言这个功能外,还影响时区、货币、日期格式,这个与本篇关系不大,就略过了。
c.字符集
接下来就是最后一个参数,字符集
我通过网络上的文章,以及自己在数据库中的摸索,得到以下这些sql,可以查询语言、地区、字符集
select * from nls_database_parameters where parameter in ('nls_territory','nls_language','nls_characterset');
select * from nls_instance_parameters where parameter in ('nls_territory','nls_language','nls_characterset');
select * from nls_session_parameters where parameter in ('nls_territory','nls_language','nls_characterset');
select * from v$parameter;
select * from v$nls_parameters;
select * from v$system_parameter where name like 'nls%';
select name,substr(value$, 1, 64) from x$props where name like 'nls%';
select userenv('language') from dual;
select sys_context('userenv','language') from dual;
但是,发现一个问题,这些sql分别可以让我们知道数据库和客户端中使用的语言及地区,但是对于字符集,要么没有,要么显示为数据库字符集,而客户端环境变量中设置的字符集通过任何一个sql都查不到!
这在oracle官方文档中也有对应的说明
select userenv (‘language’) from dual; gives the session’s
_ but the database character set not the client, so the value returned is not the client’s complete nls_lang setting!
select userenv (‘language’) from dual;得到当前会话的 语言_地区 以及 数据库字符集,不是客户端的字符集,所以它返回的值不是完整的客户端nls_lang设置!
先不讨论为什么oracle不提供客户端字符集在数据库中的查询方式,我们重点来看看,字符集不一样到底会产生哪些问题。
我创建了一张表,有两个字段,分别为行号、值。然后编写了4个文本文件,都是执行insert into 一条记录到这个表,行号分别为1、2、3、4,值都为"张三"。测试场景及结果整理如下
插入数据
| 行号 | 数据库语言 | 数据库字符集 | 客户端语言 | 客户端字符集 | 插入sql的文件编码 | 数据库内的十六进制数据 | 在plsql developer中的可见字符 |
|---|---|---|---|---|---|---|---|
| 1 | american | al32utf8 | simplified chinese | zhs16gbk | utf-8 | e5afaee78ab1e7ac81 | 寮犱笁 |
| 2 | american | al32utf8 | simplified chinese | zhs16gbk | ansi | e5bca0e4b889 | 张三 |
| 3 | american | al32utf8 | simplified chinese | al32utf8 | utf-8 | e5bca0e4b889 | 张三 |
| 4 | american | al32utf8 | simplified chinese | al32utf8 | ansi | d5c5c8fd | 张三 |
(实测,在plsql developer选项中启用了unicode时,客户端字符集不影响其数据显示)
用sqlplus查询数据
| 客户端字符集 | 行号 | 可见字符(chcp 936) | 可见字符(chcp 65001) |
|---|---|---|---|
| al32utf8 | 1 | 瀵姳绗 | 寮犱笁 |
| al32utf8 | 2 | 寮犱笁 | 张三 |
| al32utf8 | 3 | 寮犱笁 | 张三 |
| al32utf8 | 4 | 张三 | 张三 |
| 客户端字符集 | 行号 | 可见字符(chcp 936) | 可见字符(chcp 65001) |
|---|---|---|---|
| zhs16gbk | 1 | 寮犱笁 | 张三 |
| zhs16gbk | 2 | 张三 | |
| zhs16gbk | 3 | 张三 | |
| zhs16gbk | 4 | ?? |
根据上述测试,可以得到以下几点
- 在插入数据时,数据文件的字符集要保证和客户端字符集一致,可避免乱码(需要对应的文字在两个字符集中都存在),就算和数据库字符集不一致也没关系(比如第2行和第3行均正确且一致)
- 在插入数据时,客户端字符集和数据文件字符集不一致时,可能会造成乱码(第1行),也可能不乱码(第4行),但是否乱码只是"显示效果",它的值在某种意义上是错的
- 查询时,客户端字符集和数据库字符集保持一致,能提高正确显示文字的概率
- 查询时,代码页(chcp)和客户端字符集保持一致,能提高正确显示文字的概率
- 代码页(chcp)和数据文件编码是一种东西,也就是说,这个测试涉及到的只有3个变量,数据库字符集、客户端字符集、数据编码(受代码页或文件编码影响)
- 要想在最大程度上减少"乱码"概率的发生,需要数据库字符集、客户端字符集、数据编码三者都保持一致
- 如果无法保持三者一致,比如数据库字符集不可控时,也应该尽量让客户端字符集及数据编码保持一致
- 数据库字符集和客户端字符集不一致的情况下,比如数据库字符集为zhs16gbk,但客户端字符集为al32utf8,那么客户端插入数据时,可能部分文字无法进行转换(utf-8的字比gbk多),但反过来问题不大,只要确保访问同一个数据的所有客户端的字符集统一
三、在oracle中还原乱码
事前要确保字符集一致,可避免乱码,但如果事前没有保证字符集一致,导致产生了乱码,事后该如何挽救这批乱码的数据?
部分乱码可以通过以下方式进行还原
select utl_i18n.raw_to_char(utl_i18n.string_to_raw('寮犱笁', 'zhs16gbk'),
'al32utf8')
from dual;
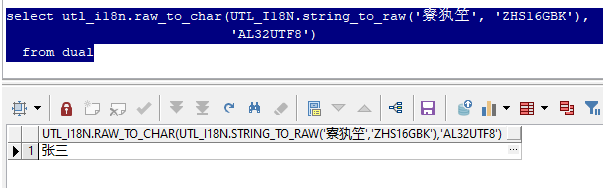
但以上仅仅是只以zhs16gbk及al32utf8来进行举例,实际场景不乏有日语、韩语、法语等等,要判断一个乱码到底是哪个字符集转哪个字符集出了问题,其实很难。
所以我开发了一个plsql包,穷举转换,输出一个表格,用户可肉眼排查乱码是怎么产生的(为减少数据输出条数,仅针对某一方有亚洲语言字符集参与的乱码)
create or replace package charset_util_pkg is
type convert_any_charset_type is record(
original_str varchar2(4000),
original_hex raw(32767),
to_str varchar2(4000),
to_hex raw(32767),
from_charset varchar2(50),
to_charset varchar2(50),
sql_text varchar2(200));
type convert_any_charset_table is table of convert_any_charset_type;
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
pipelined;
end charset_util_pkg;
/
create or replace package body charset_util_pkg is
charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('ja16euc',
--'ja16euctilde',
'ja16sjis',
--'ja16sjistilde',
'ko16mswin949',
'th8tisascii',
'vn8mswin1258',
'zhs16gbk',
'zht16hkscs',
--'zht16mswin950',
'zht32euc',
'blt8iso8859p13',
'blt8mswin1257',
'cl8iso8859p5',
'cl8mswin1251',
'ee8iso8859p2',
'el8iso8859p7',
'el8mswin1253',
'ee8mswin1250',
'ne8iso8859p10',
'nee8iso8859p4',
'we8iso8859p15',
'we8mswin1252',
'ar8iso8859p6',
'ar8mswin1256',
'iw8iso8859p8',
'iw8mswin1255',
'tr8mswin1254',
'we8iso8859p9',
'al32utf8');
asia_charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('ja16euc',
-- 'ja16euctilde',
'ja16sjis',
-- 'ja16sjistilde',
'ko16mswin949',
'th8tisascii',
'vn8mswin1258',
'zhs16gbk',
'zht16hkscs',
--'zht16mswin950',
'zht32euc');
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
pipelined is
to_str varchar2(4000);
begin
for rec in (select f.column_value from_charset,
t.column_value to_charset
from table(charsetlist) f, table(charsetlist) t
where f.column_value <> t.column_value
and (f.column_value in
(select column_value from table(asia_charsetlist)) or
t.column_value in
(select column_value from table(asia_charsetlist)))) loop
begin
to_str := utl_i18n.raw_to_char(utl_i18n.string_to_raw(original_str,
rec.from_charset),
rec.to_charset);
exception
when others then
begin
to_str := utl_i18n.raw_to_char(utl_i18n.string_to_raw(original_str ||
chr(0),
rec.from_charset),
rec.to_charset);
exception
when others then
to_str := 'convert error!';
end;
end;
if to_str in (rpad(chr(63), length(original_str), chr(63)),
rpad(utl_raw.cast_to_varchar2('c2bf'),
length(original_str),
utl_raw.cast_to_varchar2('c2bf'))) then
continue;
end if;
pipe row(convert_any_charset_type(original_str,
utl_raw.cast_to_raw(original_str),
to_str,
utl_raw.cast_to_raw(to_str),
rec.to_charset,
rec.from_charset,
'utl_i18n.raw_to_char(utl_i18n.string_to_raw(%s,''' ||
rec.from_charset || '''),''' ||
rec.to_charset || ''')'));
end loop;
end;
end charset_util_pkg;
/
select a.* from charset_util_pkg.convert_any_charset('寮犱笁') a;
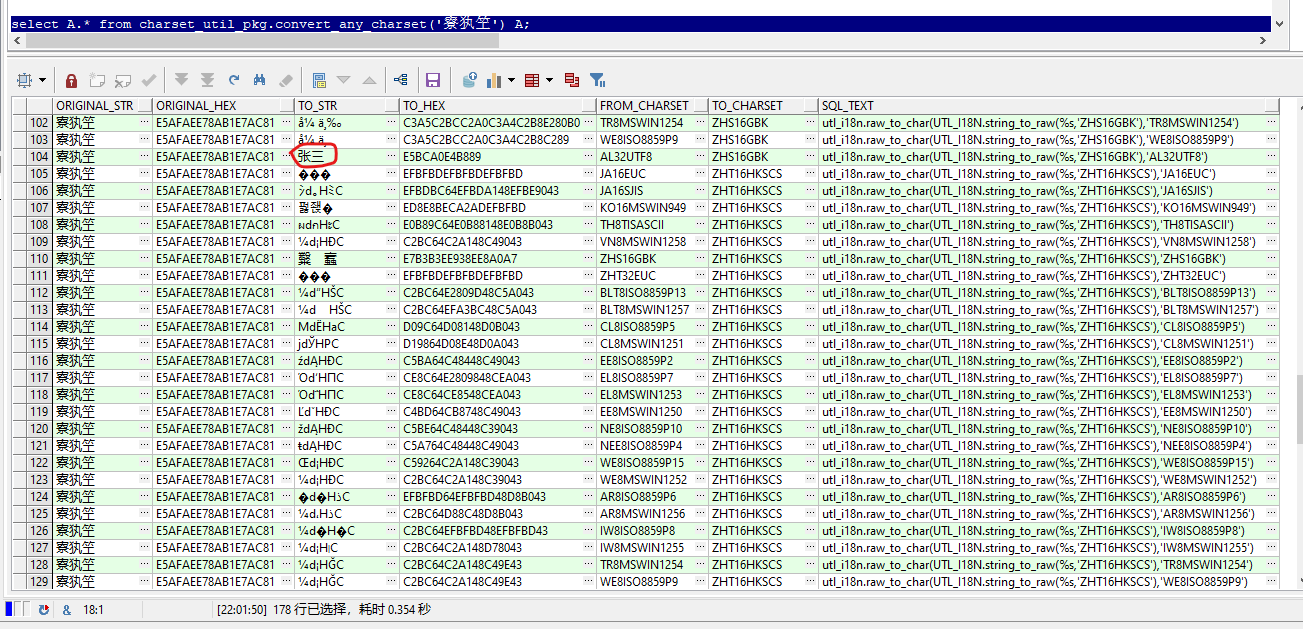
或者限定当前数据库字符集以减少条目
select a.*
from charset_util_pkg.convert_any_charset('寮犱笁') a
where from_charset =
(select value
from nls_database_parameters
where parameter = 'nls_characterset');
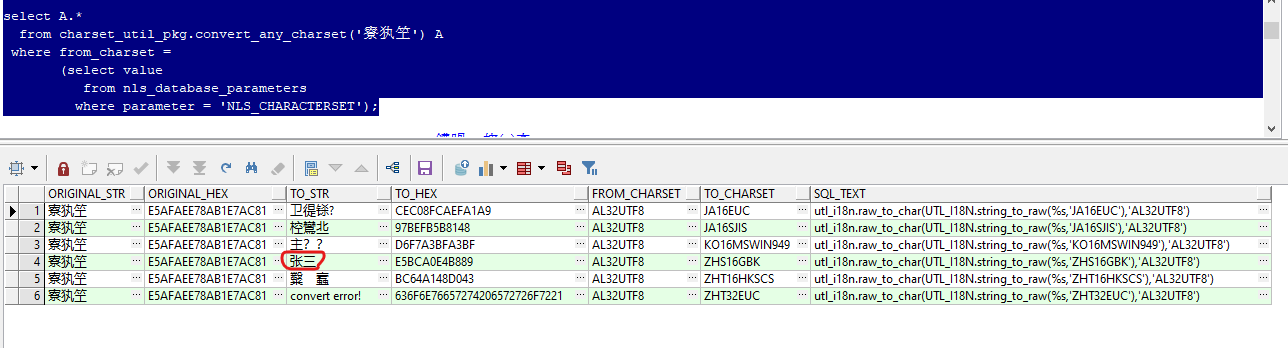
或者使用列作为传入参数
select a.*
from test_20220122_1 b,charset_util_pkg.convert_any_charset(b.b) a
where b.b='寮犱笁' and from_charset =
(select value
from nls_database_parameters
where parameter = 'nls_characterset');
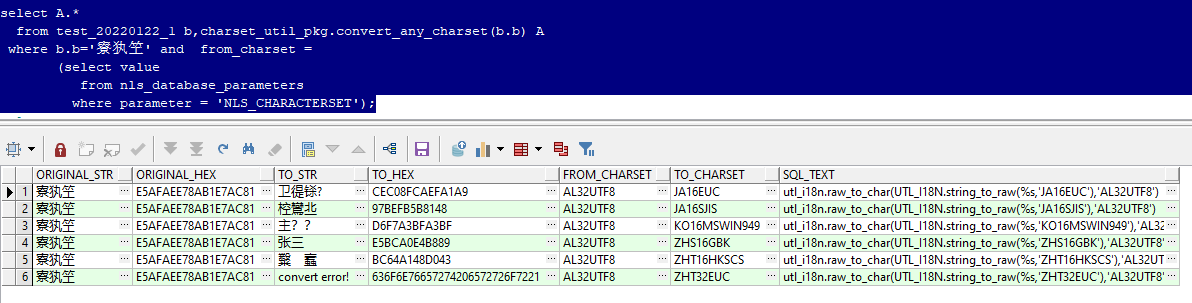
另外,还可以从结果中复制其对应的sql_text以快速获得正确的转换代码。
总结
经过以上研究可以得知,如果开发的应用项目乱码,其应用开发人员应该占首要责任,因为客户端字符集及数据编码都是由开发人员指定的,在一个只有应用输入数据的数据库中,乱码与数据库字符集的关系并不大(除非数据库安装时指定了一个偏门的字符集)。
如果在应用项目开发时不注意字符集的统一,就会出现各种奇怪的问题,比如不带条件能查到数据,复制那个值作为条件去查又查不到;还有各种奇怪的乱码。
回到开头的那个案例,其实a和b两个值就是上面这个测试中的第3行和第4行的值,虽然显示一样,但实际一个是utf8编码,一个是gbk编码。
附开头的测试数据及sql:
create table test_20220122_1 as
select utl_raw.cast_to_varchar2('e5bca0e4b889') a,
utl_raw.cast_to_varchar2('d5c5c8fd') b
from dual;
select a,
b,
length(a),
length(b),
lengthb(a),
lengthb(b),
utl_raw.cast_to_raw(a),
utl_raw.cast_to_raw(b)
from test_20220122_1;
注:以上仅针对oracle数据库,其他数据库的情况会有所区别
- 本文作者:
- 本文链接:
- 米乐app官网下载的版权声明: 本博客所有文章除特别声明外,均采用 许可协议。转载请注明出处!