

对于 oracle oracle adg 备库重启时有些人都会有一个小问题,那就是没有及时应用日志,导致主备库不同步。一般情况下主备库不同步的原因有:
主库 sys 密码改变未同步密码文件到备库
主库或者备库归档空间满无法归档
主库或者备库监听异常,无法通过网络连接到主备库
主库相关参数改变导致无法和备库正常同步
主备库 tnsnames sqlnet listener 等文件改变
备库未开启日志应用进程
备库磁盘空间不足等等其他原因。
而这些原因大多数都可以通过查看主备库的 alter 告警日志展现出来,或者在主库查看视图 v$archive_dest。
select dest_id, status, applied_scn,error from v$archive_dest where target='standby';
adg 备库停启维护步骤
下面来看一下adg 备库停启维护流程(以 11g 为例)。
1、停备库应用
如果备库有查询等的只读业务,最好可以先停止相关业务。
查看备库保护模式
select database_role,protection_mode,protection_level from v$database;
database_role protection_mode protection_level
---------------- -------------------- --------------------
physical standby maximum performance maximum performance
maximum performance:最大性能模式
默认的保护模式;在不影响主库性能的情况下,提供最高级别的保护模式。
maximum protection :最大保护模式
保证备库的内容和主库的内容完全一致,不能有丝毫的差别;保证当主库出现问题,不会有任何的数据丢失;为了达到这样的保护级别,redo data 必须同时写入主库的 online redo log和备库的 standby redo log;一旦备库的日志写入不成功,那么,主库 hang 住,超过某个时间长度,主库自动停止实例;
maximum availability:最大可用模式
介于最大保护和最大性能之间的一种模式:一般使用最大保护模式保护主库,一旦达不到最大保护模式的条件,转为最大性能模式;要求所有事务在提交前必须保障 redo 数据至少在一个 standby 数据库可用,不过与之不同的是,如果出现故障导入无法同时写入standby 数据库 redo log,primary 数据库并不会 shutdown,而是自动转为最大性能模式,等 standby 数据库恢复正常之后,它又会再自动转换成最大可用性模式。
2、先停监听,杀会话
lsnrctl status
lsnrctl stop
ps -ef | grep local=no | grep -v grep | awk '{print $2}' |wc -l
ps -ef | grep local=no | grep -v grep | awk '{print $2}' | xargs kill -9
ps -ef | grep local=no | grep -v grep | awk '{print $2}' |wc -l
3、adg备库检查、停备库
sqlplus / as sysdba
--查看同步情况
set linesize 150;
set pagesize 9999;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
select open_mode from v$database;
select process,status,sequence# from v$managed_standby;
主备库查看归档路径
column destination format a50
column process format a7
column id format 99
column mid format 99
select thread#, dest_id, destination, gvad.status, target, schedule, process, mountid mid
from gv$archive_dest gvad, gv$instance gvi
where gvad.inst_id = gvi.inst_id
and destination is not null
order by thread#, dest_id;
thread# dest_id destination status target schedule process mid
---------- ---------- -------------------------------------------------- --------- ------- -------- ------- ---
1 1 fra valid primary active arch 0
1 2 jieket4dg valid standby active lgwr 0
1 3 jiekeyun deferred standby pending lgwr 0
2 1 fra valid primary active arch 0
2 2 jieket4dg valid standby active lgwr 0
2 3 jiekeyun deferred standby pending lgwr 0
3 1 fra valid primary active arch 0
3 2 jieket4dg valid standby active lgwr 0
3 3 jiekeyun deferred standby pending lgwr 0
4 1 fra valid primary active arch 0
4 2 jieket4dg valid standby active lgwr 0
4 3 jiekeyun deferred standby pending lgwr 0
12 rows selected.
--备库查看
thread# dest_id destination status target schedule process mid
---------- ---------- -------------------------------------------------- --------- ------- -------- ------- ---
1 1 /data/jxrtt4dg/arch valid local active arch 0
1 2 jxr2p valid remote pending lgwr 0
1 32 /data/jxrtt4dg/arch valid local active rfs 0
关库
sqlplus / as sysdba
shutdown immediate;
exit;
--查看 alter 日志
tail -50f alert_jiekedb.log
4.主机关机维护,等待完毕后开机
shutdown -h now
注意:如果主机关机维护过程时间比较长,导致主库的归档日志已经被删除了而且也没有备份归档,则只能全量恢复或者增量恢复备库了,所以维护前需要调整归档删除策略来避免归档被删除。
5.启动 adg 备库
先查看是否已启动
su - oracle
ps -ef | grep smon
lsnrctl status
sqlplus / as sysdba
如果已启动,检查数据库启动到哪个阶段
col host_name for a30
select instance_name,host_name,version,startup_time,status from gv$instance;
如果没有启动,则先启动到 mount
sqlplus / as sysdba
startup mount
select open_mode from v$database;
检查 mrp0 进程是否开启
select process,status,sequence#,thread# from v$managed_standby where process='mrp0';
process status sequence# thread#
------- ------------ ---------- ----------
mrp0 applying_log 4764 4
检查 adg 同步情况
set linesize 150;
set pagesize 9999;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
如果没有开启则先开启 mrp0 进程,使用如下语句应用日志进程 mrp0
alter database recover managed standby database using current logfile disconnect;
再次查看等如下 value 值为0
set linesize 150;
set pagesize 9999;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
取消日志应用
alter database recover managed standby database cancel;
然后 open 数据库实例
alter database open;
select open_mode from v$database;
然后需要继续应用日志进程 mrp0
alter database recover managed standby database using current logfile disconnect;
--检查 mrp0 进程
select process,status,sequence#,thread# from v$managed_standby;
--查看日志应用时间,注意 apply lag 即可。
set linesize 150;
set pagesize 9999;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
select al.thrd "thread",
almax "last seq received",
lhmax "last seq applied"
from (select thread# thrd, max(sequence#) almax
from v$archived_log
where resetlogs_change# =
(select resetlogs_change# from v$database)
group by thread#) al,
(select thread# thrd, max(sequence#) lhmax
from v$log_history
where resetlogs_change# =
(select resetlogs_change# from v$database)
group by thread#) lh
where al.thrd = lh.thrd;
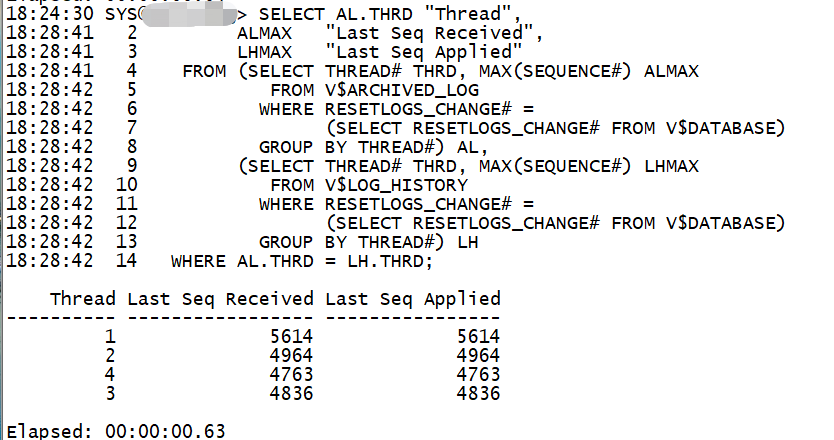
6、验证主备同步性
主库 切换日志检查备库日志是否会立即同步
alter system switch logfile;
alter system archive log current;
备库查看 alert 日志更新情况
tail -500f alert_jiekedb.log
备库基于 scn 增量恢复
备库由于前面提到的更改主库 sys 密码忘记同步密码文件到备库导致备库已经十多天不同步了,由于此库属于非生产库,没有备份更没有备份归档,恢复归档的方法这里就不能用了,故只能选择全库恢复或者基于 scn 增量恢复,这里选择增量恢复。关于 adg 备库恢复的前面也有一份手册,需要的可点此查看。
1、查看备库当前 scn
以备库当前 scn 为时间点,在主库上基于此 scn 做增量备份,然后恢复到备库,再应用当前日志即可正常同步备库。
sqlplus / as sysdba
select to_char(current_scn) from v$database;
to_char(current_scn)
----------------------------------------
11381638776
这里查到备库的 scn 之后,需要到主库查看基于此 scn 号之后是否有新增数据文件,新增的数据文件无法通过增量恢复,必须先恢复数据文件之后方可增量恢复。
2、主库备份控制文件传到备库恢复
alter database create standby controlfile as '/tmp/t4_standby.ctl';
scp /tmp/t4_standby.ctl 到备库 /tmp/t4_standby.ctl。
3、重启备库
shu immediate
startup nomount
4、备库 rman 恢复控制文件
rman target /
restore controlfile from '/tmp/t4_standby.ctl';
5、备库启动到 mount
rman> sql 'alter database mount';
6、主库基于 scn 增量备份 11381638776
run{
allocate channel c1 type disk;
allocate channel c2 type disk;
backup incremental from scn 11381638776 database format '/nfs/backup/incre_%u';
release channel c1;
release channel c2;
}
7、增量备份传到备库 /data/backup/ 并注册 catalog
scp -r /nfs/backup/incre* 到备库 /data/backup/
rman> catalog start with '/data/backup/';
8、recover 恢复备库
rman> recover database noredo;
starting recover at 2022-01-24 16:25:58
using channel ora_disk_1
rman-00571: ===========================================================
rman-00569: =============== error message stack follows ===============
rman-00571: ===========================================================
rman-03002: failure of recover command at 01/24/2022 16:25:59
rman-06094: datafile 26 must be restored
rman> recover database noredo;
starting recover at 2022-01-24 16:30:45
using channel ora_disk_1
rman-00571: ===========================================================
rman-00569: =============== error message stack follows ===============
rman-00571: ===========================================================
rman-03002: failure of recover command at 01/24/2022 16:30:45
rman-06094: datafile 26 must be restored
排查问题及解决
1、主库查看 基于 scn 后是否有新增文件
select file#,name from v$datafile where creation_change#> =11381638776;
sql> select file#,to_char(creation_time,'yyyy-mm-dd hh24:mi:ss' ) creation_time,status,last_time,name from v$datafile
where creation_change#>11381638776;
no rows selected
但是通过这个 sql 查不到,证明基于此 scn 没有新增数据文件。但前面 26 号却是实实在在得报错了,百思不得其解,大于 26 号文件的还有 27 、28 号文件。
查看 alter 日志
grep -a 4 "alter database datafile 27" alert_jie2p1.log
alter database datafile 27 resize 30g
completed: alter database datafile 27 resize 30g
thu dec 30 14:47:56 2021
alter database datafile 27 resize 32767m
completed: alter database datafile 27 resize 32767m
--添加 28 号数据文件记录。
alter tablespace jieke_data add datafile ' data' size 32767m
wed jan 05 19:46:36 2022
completed: alter tablespace jieke_data add datafile ' data' size 32767m
wed jan 05 19:47:52 2022
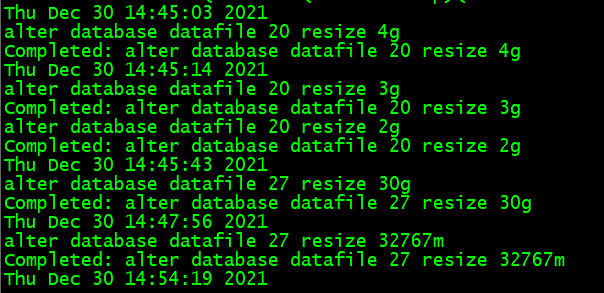
查看 alter 日志此三个数据文件也是在修改主库密码文件前添加的,所以不属于新增的数据文件。
查看这三个文件创建时间
col name for a69
select file#,name,creation_time from v$datafile where file#>=26;
file# name creation_time
---------- --------------------------------------------------------------------- -------------------
26 data/jie2p/datafile/t4_ccdb_data.313.1083605453 2021-09-18 17:31:09
27 data/jie2p/datafile/jieke_data.314.1087482763 2021-11-01 14:32:57
28 data/jie2p/datafile/jieke_data.323.1093203957 2022-01-05 19:46:35
查看生成的备库控制文件中确实存在如上的三个数据文件,说明控制文件恢复的也没有问题。
strings t4standby.ctl | grep jieke_data.323.1093203957
备库通过 report schema; 查看 size 大小为 0,“datafile name” 列的路径下没有数据文件,说明这三个文件存在问题。
rman> report schema;
rman-06139: warning: control file is not current for report schema
report of database schema for database with db_unique_name jieket4dg
list of permanent datafiles
===========================
file size(mb) tablespace rb segs datafile name
---- -------- -------------------- ------- ------------------------
1 30720 system *** /data/jieket4dg/datafile/system.260.1016468519
2 32704 sysaux *** /data/jieket4dg/datafile/sysaux.306.1016468763
3 10240 undotbs1 *** /data/jieket4dg/datafile/undotbs1.270.1016468699
4 3557 users *** /data/jieket4dg/datafile/users.264.1016468597
5 32704 jieke_data *** /data/jieket4dg/datafile/jieke_data.261.1016468517
6 20480 jieke_index *** /data/jieket4dg/datafile/jieke_index.262.1016468595
7 5120 jieke_dat *** /data/jieket4dg/datafile/jieke_dat.256.1016468521
8 1024 prod_yd_data *** /data/jieket4dg/datafile/prod_yd_data.257.1016468697
9 1024 prod_yd_index *** /data/jieket4dg/datafile/prod_yd_index.305.1016468765
10 5120 prod_mobiscf_data *** /data/jieket4dg/datafile/prod_mobiscf_data.269.1016468595
11 5120 prod_mobiscf_index *** /data/jieket4dg/datafile/prod_mobiscf_index.304.1016468767
12 5120 prod_dbsz_data *** /data/jieket4dg/datafile/prod_dbsz_data.295.1016468521
13 5120 prod_dbsz_index *** /data/jieket4dg/datafile/prod_dbsz_index.277.1016468701
14 29696 sysaux *** /data/jieket4dg/datafile/sysaux.265.1016468591
15 29696 sysaux *** /data/jieket4dg/datafile/sysaux.274.1016468701
16 10240 undotbs2 *** /data/jieket4dg/datafile/undotbs02.dbf
17 10240 undotbs3 *** /data/jieket4dg/datafile/undotbs03.dbf
18 10240 undotbs4 *** /data/jieket4dg/datafile/undotbs04.dbf
19 1400 prod_scfop_tbs *** /data/jieket4dg/datafile/prod_scfop_tbs.300.1037881143
20 2048 users *** /data/jieket4dg/datafile/users.307.1045325715
21 100 test_py_data *** /data/jieket4dg/datafile/test_py_data.308.1057426717
22 32767 jieke_data *** /data/jieket4dg/datafile/jieke_data.309.1067980347
23 500 itsm_auto_test1_data *** /data/jieket4dg/datafile/itsm_auto_test1_data.310.1072006145
24 500 itsm_auto_test2_data *** /data/jieket4dg/datafile/itsm_auto_test2_data.311.1072006461
25 1824 ogg_tbs *** /data/jieket4dg/datafile/ogg_tbs.312.1080748083
26 0 t4_ccdb_data *** /data/jieket4dg/datafile/t4_ccdb_data.313.1083605453
27 0 jieke_data *** /data/jieket4dg/datafile/jieke_data.314.1087482763
28 0 jieke_data *** /data/jieket4dg/datafile/jieke_data.323.1093203957
list of temporary files
=======================
file size(mb) tablespace maxsize(mb) tempfile name
---- -------- -------------------- ----------- --------------------
2 5120 temp 5120 /data/jieket4dg/tempfile/temp.273.1016480467
事后本想通过前面查询到的 scn 反查当时时间,但遗憾的是在主备库查询均报错了。这是由于最小的 scn 号也已经超过了此 scn,故无法进行相互转换了,如下所示:
sql> select to_char(scn_to_timestamp('11381638776'),'yyyy-mm-dd hh24:mi:ss') scndate from dual;
select to_char(scn_to_timestamp('11381638776'),'yyyy-mm-dd hh24:mi:ss') scndate from dual
*
error at line 1:
ora-08181: specified number is not a valid system change number
ora-06512: at "sys.scn_to_timestamp", line 1
sql> col min_scn for 99999999999999999999
sql> select min(scn) min_scn from sys.smon_scn_time;
min_scn
---------------------
11735387827
elapsed: 00:00:00.00
sql> select to_char(scn_to_timestamp(11735387827), 'yyyy-mm-dd hh24:mi:ss') scndate from dual;
scndate
-------------------
2022-02-03 00:25:10
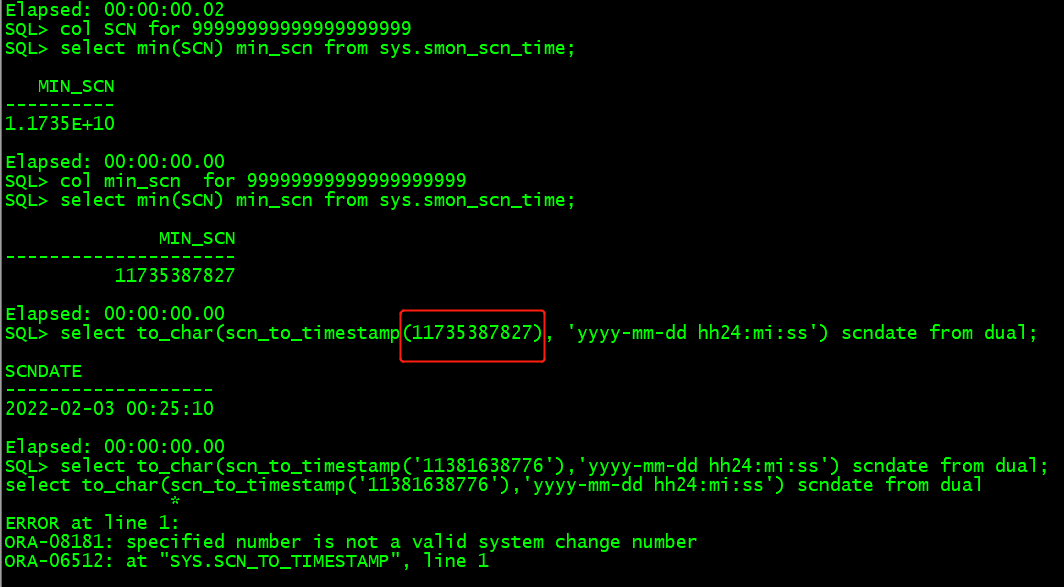
既然这三个数据文件有问题,那么就按照新增数据文件或者修改数据文件的方式去处理,则在主库备份这几个新增数据文件然后在备库恢复,在接着做增量恢复就行。
2、主库备份新增数据文件26 27 28
rman> run{
allocate channel c1 type disk;
2> 3> allocate channel c2 type disk;
4> backup datafile 26,27,28 format '/nfs/backup/incre_dbfile_%u';
5> release channel c1;
6> release channel c2;
}
7>
3、scp 传到备库恢复
scp /nfs/backup/incre_dbfile* 到备库 /data/backup/dbfile
rman target /
catalog start with '/data/backup/dbfile';
rman> run{
2> set newname for datafile 26 to '/data/jieket4dg/datafile/t4_ccdb_data.313.1083605453';
3> set newname for datafile 27 to '/data/jieket4dg/datafile/jieke_data.314.1087482763';
4> set newname for datafile 28 to '/data/jieket4dg/datafile/jieke_data.323.1093203957';
5> restore datafile 26,27,28;}
executing command: set newname
executing command: set newname
executing command: set newname
starting restore at 2022-01-24 17:44:42
using channel ora_disk_1
channel ora_disk_1: starting datafile backup set restore
channel ora_disk_1: specifying datafile(s) to restore from backup set
channel ora_disk_1: restoring datafile 00026 to /data/jieket4dg/datafile/t4_ccdb_data.313.1083605453
channel ora_disk_1: restoring datafile 00027 to /data/jieket4dg/datafile/jieke_data.314.1087482763
channel ora_disk_1: reading from backup piece /data/backup/dbfile/incre_dbfile_1p0k3nsi_1_1
channel ora_disk_1: piece handle=/data/backup/dbfile/incre_dbfile_1p0k3nsi_1_1 tag=tag20220124t170834
channel ora_disk_1: restored backup piece 1
channel ora_disk_1: restore complete, elapsed time: 00:05:35
channel ora_disk_1: starting datafile backup set restore
channel ora_disk_1: specifying datafile(s) to restore from backup set
channel ora_disk_1: restoring datafile 00028 to /data/jieket4dg/datafile/jieke_data.323.1093203957
channel ora_disk_1: reading from backup piece /data/backup/dbfile/incre_dbfile_1q0k3nsi_1_1
channel ora_disk_1: piece handle=/data/backup/dbfile/incre_dbfile_1q0k3nsi_1_1 tag=tag20220124t170834
channel ora_disk_1: restored backup piece 1
channel ora_disk_1: restore complete, elapsed time: 00:02:05
finished restore at 2022-01-24 17:52:23
rman> report schema;
rman-06139: warning: control file is not current for report schema
report of database schema for database with db_unique_name jieket4dg
list of permanent datafiles
===========================
file size(mb) tablespace rb segs datafile name
---- -------- -------------------- ------- ------------------------
1 30720 system *** /data/jieket4dg/datafile/system.260.1016468519
2 32704 sysaux *** /data/jieket4dg/datafile/sysaux.306.1016468763
3 10240 undotbs1 *** /data/jieket4dg/datafile/undotbs1.270.1016468699
4 3557 users *** /data/jieket4dg/datafile/users.264.1016468597
5 32704 jieke_data *** /data/jieket4dg/datafile/jieke_data.261.1016468517
6 20480 jieke_index *** /data/jieket4dg/datafile/jieke_index.262.1016468595
7 5120 jieke_dat *** /data/jieket4dg/datafile/jieke_dat.256.1016468521
8 1024 prod_yd_data *** /data/jieket4dg/datafile/prod_yd_data.257.1016468697
9 1024 prod_yd_index *** /data/jieket4dg/datafile/prod_yd_index.305.1016468765
10 5120 prod_mobiscf_data *** /data/jieket4dg/datafile/prod_mobiscf_data.269.1016468595
11 5120 prod_mobiscf_index *** /data/jieket4dg/datafile/prod_mobiscf_index.304.1016468767
12 5120 prod_dbsz_data *** /data/jieket4dg/datafile/prod_dbsz_data.295.1016468521
13 5120 prod_dbsz_index *** /data/jieket4dg/datafile/prod_dbsz_index.277.1016468701
14 29696 sysaux *** /data/jieket4dg/datafile/sysaux.265.1016468591
15 29696 sysaux *** /data/jieket4dg/datafile/sysaux.274.1016468701
16 10240 undotbs2 *** /data/jieket4dg/datafile/undotbs02.dbf
17 10240 undotbs3 *** /data/jieket4dg/datafile/undotbs03.dbf
18 10240 undotbs4 *** /data/jieket4dg/datafile/undotbs04.dbf
19 1400 prod_scfop_tbs *** /data/jieket4dg/datafile/prod_scfop_tbs.300.1037881143
20 2048 users *** /data/jieket4dg/datafile/users.307.1045325715
21 100 test_py_data *** /data/jieket4dg/datafile/test_py_data.308.1057426717
22 32767 jieke_data *** /data/jieket4dg/datafile/jieke_data.309.1067980347
23 500 itsm_auto_test1_data *** /data/jieket4dg/datafile/itsm_auto_test1_data.310.1072006145
24 500 itsm_auto_test2_data *** /data/jieket4dg/datafile/itsm_auto_test2_data.311.1072006461
25 1824 ogg_tbs *** /data/jieket4dg/datafile/ogg_tbs.312.1080748083
26 10240 t4_ccdb_data *** /data/jieket4dg/datafile/t4_ccdb_data.313.1083605453
27 32767 jieke_data *** /data/jieket4dg/datafile/jieke_data.314.1087482763
28 32767 jieke_data *** /data/jieket4dg/datafile/jieke_data.323.1093203957
list of temporary files
=======================
file size(mb) tablespace maxsize(mb) tempfile name
---- -------- -------------------- ----------- --------------------
2 5120 temp 5120 /data/jieket4dg/tempfile/temp.273.1016480467
4、恢复完数据文件重新注册 catalog 增量恢复备库
rman> catalog start with '/data/backup';
using target database control file instead of recovery catalog
searching for all files that match the pattern /data/backup
no files found to be unknown to the database
rman> list incarnation;
list of database incarnations
db key inc key db name db id status reset scn reset time
------- ------- -------- ---------------- --- ---------- ----------
1 1 jxr2p 3857716255 parent 1 2013-08-24 11:37:30
2 2 jxr2p 3857716255 parent 925702 2017-10-16 14:48:01
3 3 jxr2p 3857716255 current 671821825 2019-08-16 19:27:10
rman> recover database noredo;
starting recover at 2022-01-24 18:00:21
allocated channel: ora_disk_1
channel ora_disk_1: sid=572 device type=disk
channel ora_disk_1: starting incremental datafile backup set restore
channel ora_disk_1: specifying datafile(s) to restore from backup set
destination for restore of datafile 00001: /data/jieket4dg/datafile/system.260.1016468519
destination for restore of datafile 00006: /data/jieket4dg/datafile/jieke_index.262.1016468595
destination for restore of datafile 00011: /data/jieket4dg/datafile/prod_mobiscf_index.304.1016468767
destination for restore of datafile 00013: /data/jieket4dg/datafile/prod_dbsz_index.277.1016468701
destination for restore of datafile 00014: /data/jieket4dg/datafile/sysaux.265.1016468591
destination for restore of datafile 00017: /data/jieket4dg/datafile/undotbs03.dbf
destination for restore of datafile 00019: /data/jieket4dg/datafile/prod_scfop_tbs.300.1037881143
destination for restore of datafile 00020: /data/jieket4dg/datafile/users.307.1045325715
destination for restore of datafile 00021: /data/jieket4dg/datafile/test_py_data.308.1057426717
destination for restore of datafile 00023: /data/jieket4dg/datafile/itsm_auto_test1_data.310.1072006145
destination for restore of datafile 00024: /data/jieket4dg/datafile/itsm_auto_test2_data.311.1072006461
channel ora_disk_1: reading from backup piece /data/backup/incre_1m0k3ibg_1_1
channel ora_disk_1: piece handle=/data/backup/incre_1m0k3ibg_1_1 tag=tag20220124t153407
channel ora_disk_1: restored backup piece 1
channel ora_disk_1: restore complete, elapsed time: 00:04:35
channel ora_disk_1: starting incremental datafile backup set restore
channel ora_disk_1: specifying datafile(s) to restore from backup set
destination for restore of datafile 00002: /data/jieket4dg/datafile/sysaux.306.1016468763
destination for restore of datafile 00003: /data/jieket4dg/datafile/undotbs1.270.1016468699
destination for restore of datafile 00004: /data/jieket4dg/datafile/users.264.1016468597
destination for restore of datafile 00005: /data/jieket4dg/datafile/jieke_data.261.1016468517
destination for restore of datafile 00007: /data/jieket4dg/datafile/jieke_dat.256.1016468521
destination for restore of datafile 00008: /data/jieket4dg/datafile/prod_yd_data.257.1016468697
destination for restore of datafile 00009: /data/jieket4dg/datafile/prod_yd_index.305.1016468765
destination for restore of datafile 00010: /data/jieket4dg/datafile/prod_mobiscf_data.269.1016468595
destination for restore of datafile 00012: /data/jieket4dg/datafile/prod_dbsz_data.295.1016468521
destination for restore of datafile 00015: /data/jieket4dg/datafile/sysaux.274.1016468701
destination for restore of datafile 00016: /data/jieket4dg/datafile/undotbs02.dbf
destination for restore of datafile 00018: /data/jieket4dg/datafile/undotbs04.dbf
destination for restore of datafile 00022: /data/jieket4dg/datafile/jieke_data.309.1067980347
destination for restore of datafile 00025: /data/jieket4dg/datafile/ogg_tbs.312.1080748083
channel ora_disk_1: reading from backup piece /data/backup/incre_1n0k3ibh_1_1
channel ora_disk_1: piece handle=/data/backup/incre_1n0k3ibh_1_1 tag=tag20220124t153407
channel ora_disk_1: restored backup piece 1
channel ora_disk_1: restore complete, elapsed time: 00:05:35
finished recover at 2022-01-24 18:10:32
rman>
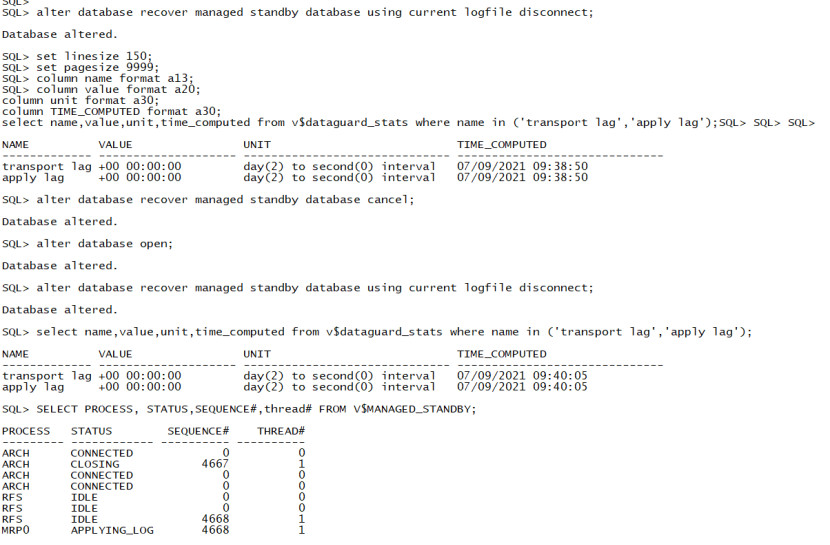
5、开库并启动 mrp0 应用日志
alter database open;
alter database recover managed standby database using current logfile disconnect from session;
set linesize 150;
set pagesize 9999;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
6、adg 其他常用 sql
--1.查询主备库的同步情况
set linesize 150;
set pagesize 20;
column name format a13;
column value format a20;
column unit format a30;
column time_computed format a30;
select name,value,unit,time_computed from v$dataguard_stats where name in ('transport lag','apply lag');
--备库查询
alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
select thread#,count(first_time) from v$archived_log where applied='no' group by thread#;
select thread#,min(first_time) from v$archived_log where applied='no' group by thread#;
select thread#,min(sequence#) from v$archived_log where applied='no' group by thread#;
select backup_count from v$archived_log where thread#=&1 and sequence#=&2;
--2.查询备库的进程状态
select process, status,sequence#,thread# from v$managed_standby;
select message_num,error_code,timestamp,message from v$dataguard_status;
--3.查询备库的角色
set linesize 160;
column dbname format a8;
column dbuname format a10;
column cftype format a8;
column open_mode format a25;
column database_role format a18;
select name dbname,db_unique_name dbuname,controlfile_type cftype,database_role,open_mode from v$database;
--4.查询备库的日志应用模式
select recovery_mode from v$archive_dest_status where dest_id=1;
recovery_mode
---------------------------------------------------------------------
managed real time applys
--5.开启日志应用进程:
--应用stanby 实时同步
sql> alter database recover managed standby database using current logfile disconnect;
alter database recover managed standby database using current logfile disconnect from session;
--6.取消日志应用
alter database recover managed standby database cancel;
set lines 320
col message for a88
col timestamp for a20
select error_code, severity, message,
to_char(timestamp, 'dd-mon-rr hh24:mi:ss') timestamp
from v$dataguard_status
where callout='yes'
and timestamp > sysdate-1;
select thread#,sequence#, first_time, next_time, applied from v$archived_log order by 3;
select name,database_role,switchover_status from v$database;
select sequence#, first_time, next_time, applied from v$archived_log order by sequence#;
col type for a15
set lines 220
set pages 330
col item for a20
col units for a15
select to_char(start_time, 'dd-mon-rr hh24:mi:ss') start_time, type,
item, units, sofar, total, timestamp
from v$recovery_progress;
--查看当前归档日志应用情况
select a.thread#, b.max_available, a.max_applied, b.max_available-a.max_applied
from
(select thread#, max(sequence#) max_applied
from gv$archived_log
where applied='yes'
group by thread# ) a,
(select thread#, max(sequence#) max_available
from gv$archived_log
group by thread# ) b
where a.thread#=b.thread#;
select name,value,datum_time from v$dataguard_stats;
全文完,希望可以帮到正在阅读的你~~~
————————————————————————————
公众号:jiekexu dba之路
墨天轮:https://www.modb.pro/u/4347
csdn :https://blog.csdn.net/jiekexu
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————
