一、基础环境
操作系统:red hat enterprise linux server release 7.6 (maipo)
数据库:oracle 12.1.0.2 rac
二、问题描述
2022年11月18日一套业务系统主机因硬件故障发生重启,主机重启后数据库节点1无法正常启动,节点2可以正常对外提供服务。节点1css进程无法启动到real time,关闭安全加固相关的titanagent 服务后,重启操作系统,可以正常启动集群和数据库。
三、分析过程
1、检查主机重启后集群状态
--------------------------------------------------------------------------------
name target state server state_details
--------------------------------------------------------------------------------
cluster resources
--------------------------------------------------------------------------------
ora.asm
1 online offline
ora.cluster_interconnect.haip
1 online offline
ora.crf
1 online online nadb01
ora.crsd
1 online offline
ora.cssd
1 online offline starting
ora.cssdmonitor
1 online online nadb01
ora.ctssd
1 online offline
ora.diskmon
1 offline offline
ora.evmd
1 online offline
ora.gipcd
1 online online nadb01
ora.gpnpd
1 online online nadb01
ora.mdnsd
1 online online nadb01
cssd进程启动异常。
2、检查数据库集群日志
[gpnpd(231513)]crs-2328:gpnpd started on node zadb03.
2022-11-18 10:56:09.210:
[cssd(231620)]crs-1713:cssd daemon is started in clustered mode
2022-11-18 10:56:09.219:
[cssd(231620)]crs-1656:the css daemon is terminating due to a fatal error; details at (:csssc00011:) in /u01/app/11.2.0.4/grid/log/newdb01/cssd/ocssd.log
2022-11-18 10:56:11.034:
[ohasd(229354)]crs-2767:resource state recovery not attempted for 'ora.diskmon' as its target state is offline
从日志看]crs-1656:the css daemon is terminating due to a fatal error; details at (:csssc00011:) in /u01/app/12.1.0.2/grid/log/newdb01/cssd/ocssd.log
检查 ocssd日志
2022-11-18 10:56:09.210: [ cssd][3219912512]clssscmain: starting css daemon, version 11.2.0.4.0, in (clustered) mode with uniqueness value 1668740169
2022-11-18 10:56:09.210: [ cssd][3219912512]clssscmain: environment is production
2022-11-18 10:56:09.210: [ cssd][3219912512]clssscmain: core file size limit extended
2022-11-18 10:56:09.212: [ cssd][3219912512]clssscmain: gipcha down 0
2022-11-18 10:56:09.213: [ cssd][3219912512]clssscgetparameterolr: olr fetch for parameter logsize (8) failed with rc 21
2022-11-18 10:56:09.213: [ cssd][3219912512]clssscextendlimits: the current soft limit for file descriptors is 65536, hard limit is 65536
2022-11-18 10:56:09.213: [ cssd][3219912512]clssscextendlimits: the current soft limit for locked memory is 4294967295, hard limit is 4294967295
2022-11-18 10:56:09.213: [ cssd][3219912512]clssscgetparameterolr: olr fetch for parameter priority (15) failed with rc 21
2022-11-18 10:56:09.213: [ cssd][3219912512]clssscsetprivenv: setting priority to 4
2022-11-18 10:56:09.219: [ cssd][3219912512]clssscsetprivenv: unable to set priority to 4
2022-11-18 10:56:09.219: [ cssd][3219912512]slos: cat=-2, opn=scls_set_priority_realtime, dep=1, loc=setsched
unable to escalate to real time
从ocss日志中可以看到ocssd进程启动时无法得到较高的优先级,无法启动到real time。
linux: gi ocssd fails to start after cgroups setting change (doc id 1577784.1) 描述与此现象高度相似
deployed puppet which created a new cgroup-configuration by default.
ls /cgroups/cpu.rt_*
/cgroups/cpu.rt_period_us /cgroups/cpu.rt_runtime_us
cat /cgroups/cpu.rt_*
1000000
950000
cat /cgroups/sysdefault/cpu.rt_*
1000000
0 ====>> 0
solution
option 1: restore the default value and reboot the node:
cat /etc/cgconfig.conf
mount {
memory = /cgroups;
cpu = /cgroups;
}
group lu-adm {
cpu {
cpu.shares = 50;
}
memory {
memory.memsw.limit_in_bytes = 500m;
memory.limit_in_bytes = 200m;
}
}
group sysdefault {
cpu {
cpu.shares = 1024;
cpu.rt_period_us = 1000000;
cpu.rt_runtime_us = 950000; ====>> changed from 0 back to default
}
}
workaround is to clear cgroup setting through 'cgclear' after consulting sysadmin.
cgroup-configuration file changed in rhel 6 and later versions
rhel 6 cd /sys/fs/cgroup/cpuacct/user.slice
cat cpu.rt_period_us
rhel 7 path i.e file location : ls /sys/fs/cgroup/cpu/cpu.rt_*
the file is not availble in all os -- check with the os vendor for details.
3、检查操作系统相关配置和服务
[root@ ~]# cat /etc/cgconfig.conf
cat: /etc/cgconfig.conf: no such file or directory
没有cgconfig.conf 文件
[root@ ~]# ls /sys/fs/cgroup/cpu/cpu.rt_*
/sys/fs/cgroup/cpu/cpu.rt_period_us /sys/fs/cgroup/cpu/cpu.rt_runtime_us
[root@ ~]#
[root@ ~]# cat /sys/fs/cgroup/cpu/cpu.rt_period_us
1000000
[root@ ~]# cat /sys/fs/cgroup/cpu/cpu.rt_runtime_us
950000
[root@~]#
cpu.rt_period_us和cpu.rt_runtime_us设置的就是推荐值950000
该文档《linux: gi ocssd fails to start after cgroups setting change (doc id 1577784.1)》的m6米乐安卓版下载的解决方案不适用。
4、reahat官方关于cpu的相关设置说明
how to configure a rhel 7 or rhel 8 system to be able to run programs requiring real-time scheduling
当cpuaccounting参数enabled时,将不能创建real-time进程。排查system.conf配置文件发现并没有开启cpuaccounting参数

5、检查操作系统cpu accounting、cpuquots等
[root@ ~]# grep defaultcpuaccounting /etc/systemd/system.conf
#defaultcpuaccounting=no
但是在titanagent.service服务文件中发现配置了cpuquota=50%
[root@~]# cat /usr/lib/systemd/system/titanagent.service
[unit]
description=titanagent
after=network.target
[service]
user=root
cpuquota=50%
type=forking
pidfile=/var/run/titanagent.pid
execstartpre=/bin/bash -c “/titan/agent/titanagent -s”
execstart=/bin/bash -c “/titan/agent/titanagent -d -b /etc/titanagent”
execstop=/bin/bash -c “/titan/agent/titanagent -s”
execreload=/bin/bash -c “/titan/agent/titanagent -d -b /etc/titanagent”
privatetmp=no
restart=always
restartsec=60s
timeoutsec=20s
timeoutstopsec=30s
[install]
wantedby=multi-user.target
cpuquota参数会隐性开启cpuaccounting
6、禁用titanagent.service后,重启主机集群启动正常
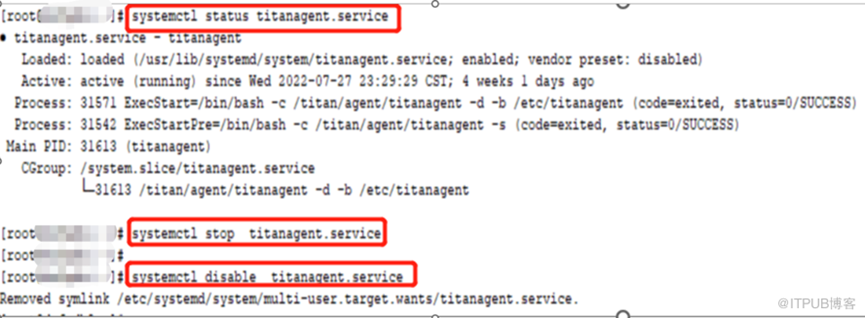
-the end-