本案例中的问题sql发生在当前主流的oracle:11g环境。不排除随着后续版本的升级可能会有一定细微的差异表现。但问题的主要现象及优化思路,是大同小异的。
本案例内容来源于客户应用部门,急需要对某一功能进行上线。将sql提交到我这里做审核。分析过程中总结出很多典型的优化方法和技巧,故有了此文章。
上线功能是一系列多条sql,本条sql是其中相对耗时的sql之一。
下面列出sql语句:
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tccp,
tcc,
tcm,
tcp,
tpl
where tccp.case_id = tcc.case_id
and tccp.policy_id = tcm.policy_id
and tccp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and tccp.audit_conclusion is not null
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >=
(select add_months(max(t.apply_date), -12)
from tcm t
where t.agent_id = tcm.agent_id)
and tcm.agent_id = '387932438';
通过文本,大家可以思考几分钟,这条sql有哪些问题,可以从哪里去调整。
。。。
下面分析执行效率:

相同执行计划,由于传入值的不同,消耗资源存在一定差异,但总体偏慢。执行时间接近1秒、59w逻辑读开销。
列出执行计划如下:
多次执行在消除了物理读的情况下,还需要0.87秒才能完成查询。可以看到效率是比较低的。主要耗时就发生在内层框出的两部分。
- 两次tcm表的索引扫描并回表;
- 关联tccp表并回表的部分。
这条查询返回77行数据,得到汇总的count值。但中间却要访问想多多的数据量。可以理解为查询代价是偏大的。针对上述耗时部分,需要想办法去优化他。
通过上一章节。基本明确了主要的耗时步骤发生在两次tcm表和一次tccp表的访问过程中。思考下通过何种思路来优化。
首先tcm表是主要的过滤条件。且sql通过该列索引访问效率并不差。范围扫描0.02秒。主要慢在回表部分。tccp表现也近似。因此考虑下是否通过调整索引设计来避免回表,达到优化的目的。
考虑到当前表体积较大,索引数量比较多。且为系统中比较核心的业务表之一。因此初步想法是先不通过调整索引来尝试优化。通过如下手段逐步优化sql的各个耗时部分:
3.1 去掉一次表访问:
首先sql中两次访问tcm表,且主要的过滤条件都通过agent_id列。因此考虑能否去掉一次表访问。也就是子查询中的部分是多余的
(select add_months(max(t.apply_date), -12)
from tcm t
where t.agent_id = tcm.agent_id);
该段代码的目的是为了获取相同agent_id的最大值并减去1年的日期条件。为了实现该查询,可以考虑在外层tcm访问时同步获取该1年内的日期值。
select max(apply_date) over(), -12)
from tcm t
where t.agent_id = '387932438'
即:在外层tcm表访问时通过窗户函数来同步获得最大日期列。
调整sql语句为如下代码:
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tccp,
tcc,
(select policy_id, add_months(max(apply_date) over(), -12) apply_date
from tcm t
where t.agent_id = '387932438') tcm,
tcp,
tpl
where tccp.case_id = tcc.case_id
and tccp.policy_id = tcm.policy_id
and tccp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and tccp.audit_conclusion is not null
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >= tcm.apply_date;
调整后执行计划如下:
调整后,省去了一次tcm的访问,降低了部分逻辑读及执行时间。有一定的提升,继续分析其余部分。
3.2 利用cte提升回表效率:
第二部分的耗时开销来自于tccp表的索引回表部分。tcm与tccp关联后仅返回299行记录。但回表步骤的开销却比较高。

仅返回299行记录,但回表次数却与索引访问次数一致,达到了159k次。这里看到采用了最老式的回表方式。即:关联一行索引列完成一次回表。
这里介绍下其余回表方式:
table prefetch是,索引扫描表的过程中,如果产生物理i/o,预取接下来要读取的block,
提前放到buffer cache里一种功能。
batching i/o是, 索引扫描表的过程中,如果要产生物理i/o,先积攒起来到一定量以后,一次性的读取block的一种功能。
两个功能都是为了避免,每条记录都产生不必要的i/o call。
下面单独测试三种不同回表方式的性能差异:
为了便于观察差异,将驱动表建立覆盖索引。
1.传统回表:
select /* optimizer_features_enable('10.2.0.3') no_nlj_prefetch(tccp) */
count(tccp.audit_conclusion)
from (select policy_id from tcm t where t.agent_id = '387932438') tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null;
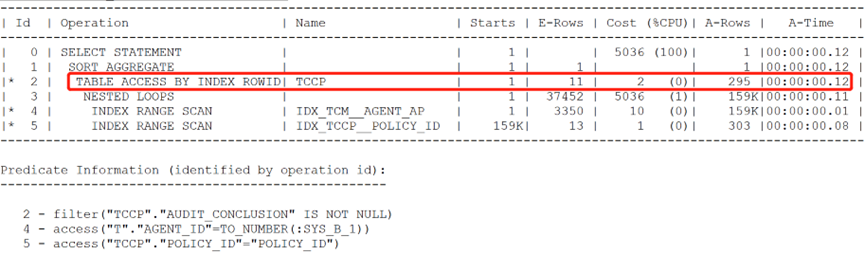
- nlj_prefetch回表:
select /* nlj_prefetch(tccp) */
count(tccp.audit_conclusion)
from (select policy_id from tcm t where t.agent_id = '387932438') tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null;
- nlj_batching回表:
select /* nlj_batching(tccp) */
count(tccp.audit_conclusion)
from (select policy_id from tcm t where t.agent_id = '387932438') tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null;
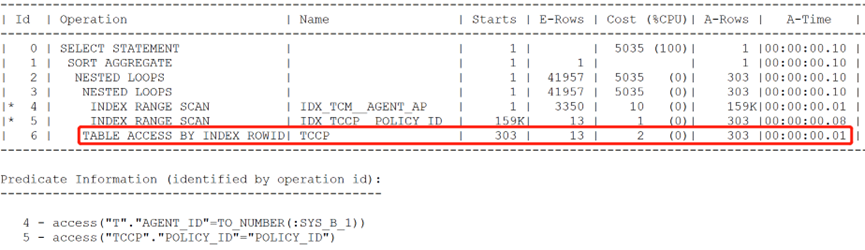
三种回表方式的时间成本分别为:0.14秒、0.01秒、0.01秒。即后两种回表方式都是很高效的。有效降低回表的次数。无论如何添加相应提示,均无法走出相应的回表效果。这里分析原因为关联tccp表时,还要通过回表步骤返回其余的case_id、item_id列在与其余的表做关联有关。因此优化器拒绝了上述预取或批量回表的方式。造成了回表这里的耗时较高。
为了利用批量回表的特性,将sql语句继续改写,让tcm与tccp关联后通过cte写法再与外层表关联:
with temp as
(select /* materialize */
tcm.apply_date, tccp.case_id, tccp.item_id
from (select policy_id,
add_months(max(apply_date) over(), -12) apply_date
from tcm t
where t.agent_id = '387932438') tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null)
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tcc,
temp,
tcp,
tpl
where temp.case_id = tcc.case_id
and temp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >= tccp.apply_date;
调整后的执行计划:

顺利采用了批量回表特性,执行时间又缩短了一部分。优化到此,主要的耗时步骤都解决了,只剩下tcm的回表问题。当前执行时间在0.5秒左右。此时与应用人员确认,是否满足要求。
答案是否定的,要求业务环境的多条sql平均执行时间在2秒内返回结果。而本条sql仅是其中的一环。因此还需要进一步优化。
3.3 创建索引:
前期的想法不调整大表tcm的索引,看来是不行的。为了满足业务响应时间,索引该建也得建啊。
但如何建索引:
agent_id是过滤列、policy_id是回表列、apply_date是为了取最大值。考虑是将过滤列在前,其次是取最大值的apply_date、最后是回表列。
create index idx_tcm__agent_ap on tcm(agent_id,apply_date,policy_id);
创建索引后,分别测试一下原始sql和上一步骤改写好的sql。
原始sql执行计划如下:
索引建立的很合适,两次tcm表均通过索引得到比较好的访问效率。矛盾集中在了tccp上面。
改写好的sql测试:
创建索引后看到,不论是原始sql,还是改写好的sql,执行时间都很短了。说明关键的索引还是很有必要的。
继续分析,是否还有优化空间?
3.4 传入等值条件:
针对3.3中的优化效果,尽管省去了一次tcm的访问。但由于是把tcm作为一个单独的view去访问,在构造生成的时候,还是会消耗不小的代价的。

而原始sql两次索引访问tcm的代价并不高。因此这里考虑,将tcm这部分还原回原始sql访问两次的写法:
这里看到代码中是隐含着tcm的agent_id=t表的agent_id的。
手动传入实际的agent值。索引的建立正好满足能直接获取到相应最大值的情况。因此期望能否利用索引的index range scan (min/max)特性。
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tccp,
tcc,
tcm,
tcp,
tpl
where tccp.case_id = tcc.case_id
and tccp.policy_id = tcm.policy_id
and tccp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and tccp.audit_conclusion is not null
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >=
(select add_months(max(t.apply_date), -12)
from tcm t
where t.agent_id = '387932438')
and tcm.agent_id = '387932438';
调整后资源消耗及时间有了进一步的下降。
3.5 传入条件与cte结合:
将3.4步骤中传入条件的写法与cte结合起来。
with temp as
(select /* materialize */
tccp.case_id, tccp.item_id
from (select policy_id from tcm t where t.agent_id = '387932438') tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null)
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tcc,
temp,
tcp,
tpl
where temp.case_id = tcc.case_id
and temp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >=
(select add_months(max(t.apply_date), -12)
from tcm t
where t.agent_id = '387932438');
调整后的执行计划如下:
优化到此,主要的耗时步骤均有了较大改善。sql执行仅需要0.11秒。与应用人员确认,已经满足业务的时效性要求。可以认为优化完成了。
但仔细想一下,如果还想进一步提升,是否还有办法呢?
3.6 利用物化视图:
答案是有的。观察上面优化好的执行计划,可以看到主要的耗时步骤还是框出的tcm与tccp关联产生(cte部分)。这部分经测试传入不同的条件,其关联后的结果都是相对较小的(tccp表较小)。因此只是关联的中间结果大导致耗时较长。
且这里两表直接关联代码简单,可以建立实时刷新的物化视图,避免访问较大的中间结果集。且该条sql在业务环节中不只出现一次。还有其余步骤有类似的代码结构。建立物化视图后有多个部分都可以从中受益。
建立物化视图:把查询条件agent_id列展示出来,用于在外层语句中过滤。
create materialized view tcm_tcp build immediate refresh force on commit as
select tcm.agent_id, tccp.case_id, tccp.item_id
from tcm,
tccp
where tccp.policy_id = tcm.policy_id
and tccp.audit_conclusion is not null;
建立物化视图日志,当基表有数据变动时,实时刷新物化视图数据。
create materialized view log on tcm with rowid including new values ;
create materialized view log on tccp with rowid including new values ;
创建过滤条件agent列索引。
create index idx_tcm_tcp_agent on tcm_tcp(agent_id);
最后改写代码从物化视图中查询:
select count(distinct tcc.case_id) agpolicytwoclaimnum
from tcm_tcp,
tcc,
tcp,
tpl
where tcm_tcp.case_id = tcc.case_id
and tcm_tcp.item_id = tcp.item_id
and tcp.product_id = tpl.product_id
and (tpl.ill_rate > 0)
and tpl.period_type = '3'
and months_between(tcc.accident_time, tcp.validate_date) <= 24
and tcc.finish_time >=
(select add_months(max(t.apply_date), -12)
from tcm t
where t.agent_id = '387932438')
and tcm_tcp.agent_id = '387932438';
经过上述改造,调整后的执行计划如下:
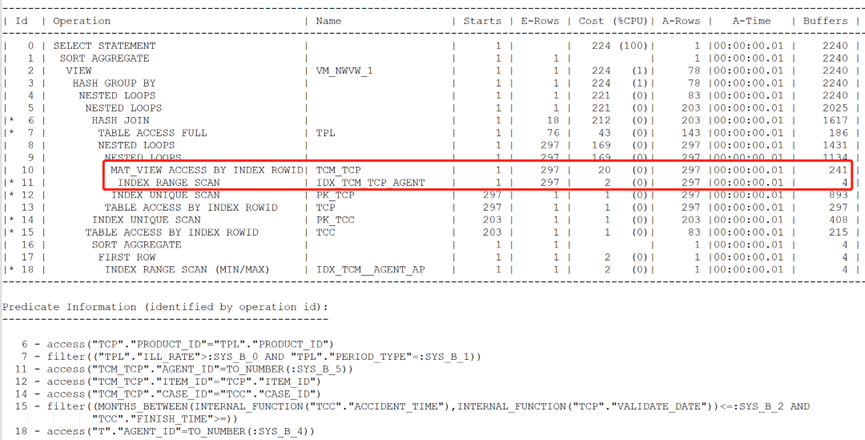
查询在0.01秒完成,整段代码中没有访问任何大量的中间结果集。从这里也能看出,访问的中间结果少,查询必然高效。优化到此已到极致。
本案例中,利用了多种优化技术:
降低表的重复访问;
利用cte提升回表效率;
利用索引提升访问效率;
利用物化视图降低中间结果。
每一种方式,都是直接作用在耗时步骤上面,可以最有效的提升sql访问效率。