

一、数据库报错
业务同事反应进行操作时报错 ora-30036:无法按8扩展段(在还原表空间 ’undotbs2‘ 中)
赶紧登录数据库一看,数据库undo2(32g)表空间爆满无法正常显示,undo1(31g)表空间使用率96%,而其中的sysaux(31g)表空间达到了91%
首先对两个undo表空间进行扩容,紧急避险
然后是赶紧生成awr报告和ash报告,分别是晚上 22:30 - 23:00 、 23:30 - 24:00
1、关注负载和等待事件
elapsed: 30.10 (mins)
db time: 433.76 (mins)
433.76/30.10=14倍负载
enq: tm - contention
enq: iv - contention
问题sql语句
sql ordered by elapsed time
可以看到有三个较为明显错误的sql语句
1、执行时间超长且从未结束的存储过程
declare job binary_integer := :job; next_date date := :mydate; broken boolean := false; begin 存储过程名; :mydate := next_date; if broken then :b := 1; else :b := 0; end if; end;
2、执行次数最多的系统表插入语句(多嘴说一句,如果一个awr报告出现了系统语句排在top sql语句里,多少有些问题,注意挖掘)sys.wri$_optstat_histhead_history
insert into sys.wri$_optstat_histhead_history (obj#, intcol#, savtime, flags, null_cnt, minimum, maximum, distcnt, density, lowval, hival, avgcln, sample_distcnt, sample_size, timestamp#, colname) select h.obj#, h.intcol#, :3, bitand(h.spare2, 7) 8 decode(h.cache_cnt, 0, 0, 64), h.null_cnt, h.minimum, h.maximum, h.distcnt, h.density, h.lowval, h.hival, h.avgcln, h.spare1, h.sample_size, h.timestamp#, :4 from sys.hist_head$ h where h.obj# = :1 and h.intcol# = :2
3、执行时间超长的一个业务sql语句
这个就不写出来来了
其中 sql ordered by cpu time 排序第二的有还有它
declare job binary_integer := :job; next_date date := :mydate; broken boolean := false; begin 存储过程名; :mydate := next_date; if broken then :b := 1; else :b := 0; end if; end;
%total占比是 20.17
sql ordered by get s排序第一的有还有它
declare job binary_integer := :job; next_date date := :mydate; broken boolean := false; begin 存储过程名; :mydate := next_date; if broken then :b := 1; else :b := 0; end if; end;
%total占比是 26.86
由此可以确认的是,数据库爆发故障和它必不可少
事后也确认,这个是一个数据库的统计信息存储过程,一共十个用户,每个用户都有,同一时间在白天启动
为什么统计信息的存储过程会导致undo1、undo2、sysaux表空间会相继撑爆
1、首先确认为什么统计信息会导致数据库undo表空间被撑爆
通过这个语句查询占据undo表空间的sql语句信息
select s.sid,
s.serial#,
s.sql_id,
v.usn,
segment_name,
r.status,
v.rssize / 1024 / 1024 mb
from dba_rollback_segs r,
gv$rollstat v,
gv$transaction t,
gv$session s
where r.segment_id = v.usn
and v.usn = t.xidusn
and t.addr = s.taddr order by segment_name;
你可以发现的是这个sql语句占据的undo表空间大小是 130m,也提及到了 sql_id,可以通过它继续查询,这个只是我截出来最大的
再通过gv$sql来查询语句
select * from gv$sql where sql_id = 'd0xmnp08rhfbg';
insert into sys.wri$_optstat_histhead_history (obj#,intcol#,savtime,flags, null_cnt,minimum,maximum,distcnt,density,lowval,hival,avgcln,sample_distcnt, sample_size,timestamp#,colname) select h.obj#, h.intcol#, :3, bitand(h.spare2,7) 8 decode(h.cache_cnt,0,0,64), h.null_cnt, h.minimum, h.maximum, h.distcnt, h.density, h.lowval, h.hival, h.avgcln, h.spare1, h.sample_size, h.timestamp#, :4 from sys.hist_head$ h where h.obj# = :1 and h.intcol# = :2
2、为什么会撑爆sysaux表空间
用这个语句查询sysaux表空间占用排名较为靠前占用模块
select occupant_name "占用者名",
space_usage_kbytes / 1024 / 1024 "space used (gb)",
schema_name "模式名",
move_procedure "移动过程"
from gv$sysaux_occupants
where space_usage_kbytes > 1048576 --1g
order by "space used (gb)" desc;
sm/awr排第一,表示awr信息占用过大
sm/opstat排第一,表示优化器统计信息占用过大
通过后续的多次执行这个sql语句,sm/opstat在不间断的增长,有一次确认了就是统计信息的问题。
那么为什么收集统计信息会让sysaux表空间撑爆?
sm/opstat用于储存历史统计信息,而这些信息是存于sysaux表空间的,如果日常人工所做的分析统计数据不断地增长,而不把历史上的旧的数据删除的话,syayux迟早会爆满。默认情况下,系统会为 sm/optstat保留31天的记录。
查询了 sys.wri$_optstat_histhead_history 系统里时间最早为 2023/1/25 0:02:10,截止到今日为1月31号可以发现的是obj#(表对象名称)收集次数有些多得离谱,确认收集统计信息存储过程判断方式绝对有问题,因为每个表的收集次数相差太多,而且多得离谱。
select distinct obj#,count(*) from sys.wri$_optstat_histhead_history group by obj#;
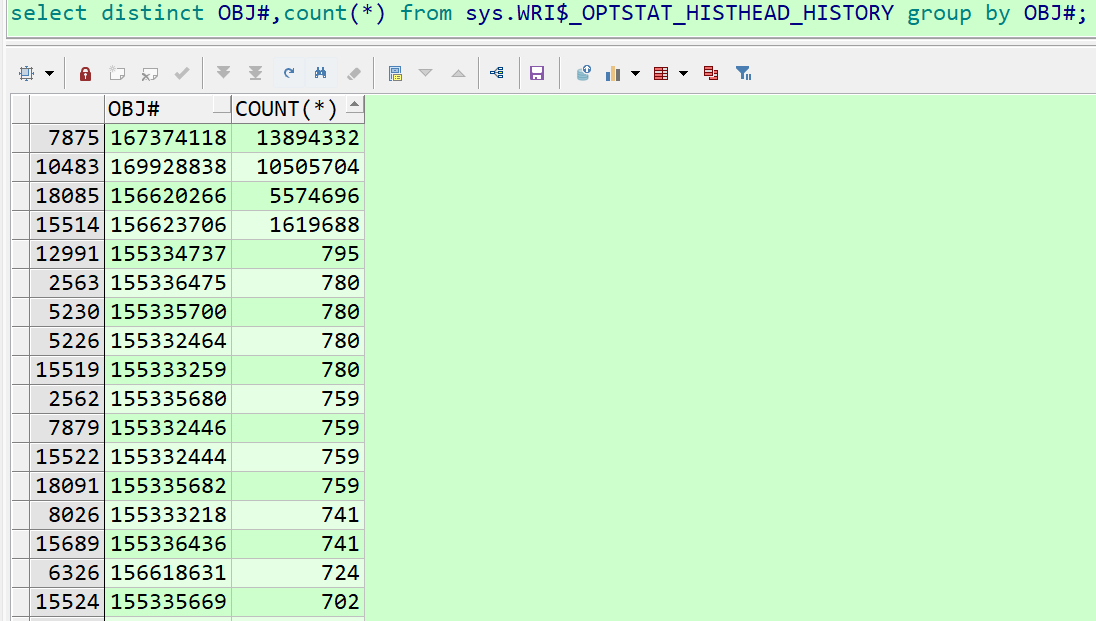
总共次数
select count(*) from sys.wri$_optstat_histhead_history;
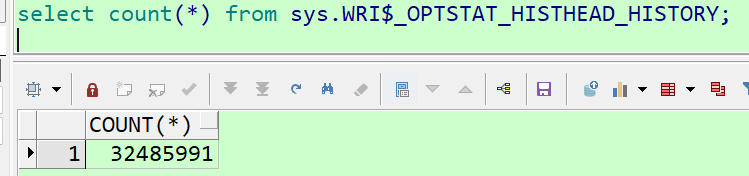
我将收集统计信息按照执行时间前后进行了对比,32139906/493100=65倍
2023/1/25 0:02:10
select count(*) from sys.wri$_optstat_histhead_history where to_char(timestamp#,'yyyymmdd') >= 20230130 ;
32139906
select count(*) from sys.wri$_optstat_histhead_history where to_char(timestamp#,'yyyymmdd') < 20230130 ;
493100
3、归档为什么会撑爆?
首先确认归档暴增的这个时间段(切换次数)
select to_char(first_time, 'yyyy-mm-dd') day,
to_char(sum(decode(to_char(first_time, 'hh24'), '00', 1, 0)), '999') "00",
to_char(sum(decode(to_char(first_time, 'hh24'), '01', 1, 0)), '999') "01",
to_char(sum(decode(to_char(first_time, 'hh24'), '02', 1, 0)), '999') "02",
to_char(sum(decode(to_char(first_time, 'hh24'), '03', 1, 0)), '999') "03",
to_char(sum(decode(to_char(first_time, 'hh24'), '04', 1, 0)), '999') "04",
to_char(sum(decode(to_char(first_time, 'hh24'), '05', 1, 0)), '999') "05",
to_char(sum(decode(to_char(first_time, 'hh24'), '06', 1, 0)), '999') "06",
to_char(sum(decode(to_char(first_time, 'hh24'), '07', 1, 0)), '999') "07",
to_char(sum(decode(to_char(first_time, 'hh24'), '08', 1, 0)), '999') "08",
to_char(sum(decode(to_char(first_time, 'hh24'), '09', 1, 0)), '999') "09",
to_char(sum(decode(to_char(first_time, 'hh24'), '10', 1, 0)), '999') "10",
to_char(sum(decode(to_char(first_time, 'hh24'), '11', 1, 0)), '999') "11",
to_char(sum(decode(to_char(first_time, 'hh24'), '12', 1, 0)), '999') "12",
to_char(sum(decode(to_char(first_time, 'hh24'), '13', 1, 0)), '999') "13",
to_char(sum(decode(to_char(first_time, 'hh24'), '14', 1, 0)), '999') "14",
to_char(sum(decode(to_char(first_time, 'hh24'), '15', 1, 0)), '999') "15",
to_char(sum(decode(to_char(first_time, 'hh24'), '16', 1, 0)), '999') "16",
to_char(sum(decode(to_char(first_time, 'hh24'), '17', 1, 0)), '999') "17",
to_char(sum(decode(to_char(first_time, 'hh24'), '18', 1, 0)), '999') "18",
to_char(sum(decode(to_char(first_time, 'hh24'), '19', 1, 0)), '999') "19",
to_char(sum(decode(to_char(first_time, 'hh24'), '20', 1, 0)), '999') "20",
to_char(sum(decode(to_char(first_time, 'hh24'), '21', 1, 0)), '999') "21",
to_char(sum(decode(to_char(first_time, 'hh24'), '22', 1, 0)), '999') "22",
to_char(sum(decode(to_char(first_time, 'hh24'), '23', 1, 0)), '999') "23"
from v$log_history
group by to_char(first_time, 'yyyy-mm-dd')
order by 1 desc;
1月31号下午3点开始
这个是确认暴增的数据量大小
with redo_data as (
select instance_number,
to_date(to_char(redo_date,'dd-mon-yy-hh24:mi'), 'dd-mon-yy-hh24:mi') redo_dt,
trunc(redo_size/(1024 * 1024 * 1024),2) redo_size_gb
from (
select dbid, instance_number, redo_date, redo_size , startup_time from (
select sysst.dbid,sysst.instance_number, begin_interval_time redo_date, startup_time,
value -
lag (value) over
( partition by sysst.dbid, sysst.instance_number, startup_time
order by begin_interval_time ,sysst.instance_number
) redo_size
from sys.wrh$_sysstat sysst , dba_hist_snapshot snaps
where sysst.stat_id =
( select stat_id from sys.wrh$_stat_name where stat_name='redo size' )
and snaps.snap_id = sysst.snap_id
and snaps.dbid =sysst.dbid
and sysst.instance_number = snaps.instance_number
and snaps.begin_interval_time> sysdate-30
order by snaps.snap_id )
)
)
select instance_number, redo_dt, redo_size_gb,
sum (redo_size_gb) over (partition by trunc(redo_dt)) total_daily,
trunc(sum (redo_size_gb) over (partition by trunc(redo_dt))/24,2) hourly_rate
from redo_data
order by redo_dt, instance_number;

大概就是这样,因为当时没截图,后来也爆发归档暴增的问题,这个凑活看看
查看归档暴增的数据库对象,为什么我要取这个时间段,因为数据库本身在凌晨没有业务,而且也过了备份的时间段,按理说不会有太大增长量。
select to_char(begin_interval_time, 'yyyy-mm-dd hh24') snap_time,
dhso.object_name,
sum(db_block_changes_delta) block_changed
from dba_hist_seg_stat dhss,
dba_hist_seg_stat_obj dhso,
dba_hist_snapshot dhs
where dhs.snap_id = dhss.snap_id
and dhs.instance_number = dhss.instance_number
and dhss.obj# = dhso.obj#
and dhss.dataobj# = dhso.dataobj#
and begin_interval_time between to_date('2023-02-01 03:00',
'yyyy-mm-dd hh24:mi')
and
to_date('2023-02-01 05:00', 'yyyy-mm-dd hh24:mi')
group by to_char(begin_interval_time, 'yyyy-mm-dd hh24'),
dhso.object_name
having sum(db_block_changes_delta) > 0
order by sum(db_block_changes_delta) desc;
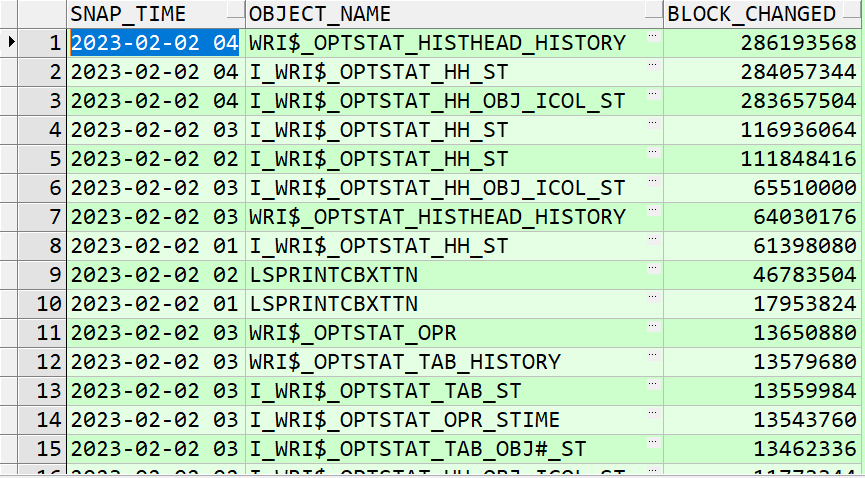
1、迅速将undo表空间扩容
alter tablespace undotbs1 add datafile ' data' size 31g;
alter tablespace undotbs2 add datafile ' data' size 31g;
2、缩短 undo_retention 参数的保留时间改为一个小时,不需要强留太长时间,迅速覆盖
alter system set undo_retention=3600 scope=both sid='*';
3、关闭删除统计信息的定时任务和进程(这点我犯了傻,我关了定时任务,但是没杀存储过程进程,导致一直拖拖拉拉的持续报警)
select job,log_user,priv_user,schema_user,what from dba_jobs where what = '存储过程名称;'
4、先关闭再停止
begin
dbms_job.broken(28, true, sysdate);
commit;
end;
/
declare
begin
dbms_job.remove(job => 28);
commit;
end;
5、删除存储过程
drop procedure 用户名.存储过程名;
如果删除卡住,说明还在运行,趁这个机会去查杀存储过程的会话
1、查询正在运行的存储过程
select *
from gv$db_object_cache
where locks > 0
and pins > 0
and type = 'procedure';
2、如果有很多存储过程就用这个来处理,进行查询
select t.* from gv$access t where t.object='存储过程名';
3、通过查出来的sid,再去找 sid和serial#
select sid,serial# from gv$session where sid='6666';
4、查杀语句
alter system kill session 'sid,serial#,@节点' immediate;
下边就是立即杀掉节点1的会话
alter system kill session '111,2222,@1' immediate;
四、知识点
1、为什么收集统计信息会导致sysaux表空间爆满
每次收集新的统计信息会即时使用,而旧的统计信息会储存在sysaux的sys.wri$_optstat_histgrm_history和中sys.wri$_optstat_histhead_history
结论:也就是说旧的统计信息为了做一份备份,删除与否不影响正在使用的统计信息正常使用,如果过于频繁的收集统计信息会造成服务器和数据库高负载和撑大sysaux表空间
而且这个表空间满了就无法正常生成awr和ash报告
2、undo为什么会爆满
数据库为了能够让使用者可以进行回退和闪回,会把所有的增删改记录记录到undo表空间里,如果设置的保留时间未到,而且增删改还在拼命增长,就会撑爆undo表空间
如果undo表空间撑爆,就没法让数据库日志先行的规则执行,导致任何操作都会卡住
3、归档爆满
当业务和统计信息混在一块而且统计信息的频率极高时,业务的增删改和数据库本身的增删改,就会导致这个结果
4、怎么能够确保一个正常频率不对数据库产生较大后果的收集手段
官方说是2g以上
业务方面可以查询表碎片大的表,这代表着大量的插入和删除
开发来确认哪些表用的多
一个月一次或者两次即可
5、为什么数据库停止操作以后还会撑爆归档
停止定时任务和停止存储过程是两码事,切记!
五、反思
1、别人说没问题的就是没问题吗?
2、在不确认任何新增存储过程的威力时,能大批量和同一时间执行吗?
3、头疼治头脚疼治脚,不进行深究,当鸵鸟,能让事情自动变好吗?
4、复盘是成长最快的方式,好记性不如烂笔头
5、无论如何优先保障数据库的正常运行,然后再去排查问题或者追责,在这个事情当中,应该迅速扩容undo和sysaux表空间62g,归档设置两个小时删除一次,而不是头疼后续收缩资源