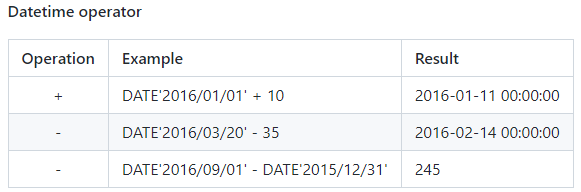以下只列出每个函数的部分内容,详细信息请参考 orafce 的文档:
bitand
bitand,返回两个数值型数值在按位进行 and 运算后的结果。
postgresql 也自带了这个函数,orafce 对这个函数做了改进。
-- 未安装 orafce
postgres=# \df bitand
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
pg_catalog | bitand | bit | bit, bit | func
(1 row)
-- 安装 orafce
postgres=# \df bitand
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
pg_catalog | bitand | bit | bit, bit | func
public | bitand | bigint | bigint, bigint | func
(2 rows)
postgres=# select bitand(5,3) from dual;
bitand
--------
1
(1 row)
双曲函数
从 postgresql 12 版本就已经支持以下三个双曲函数(hyperbolic functions),双曲正弦(sinh),双曲余弦(cosh),双曲正切(tanh)
详情参考 postgresql 的官方文档:
postgres=# select sinh(1.414) from dual;
sinh
--------------------
1.9346016882495571
(1 row)
postgres=# select cosh(2.236) from dual;
cosh
-------------------
4.731359100024696
(1 row)
postgres=# select tanh(3) from dual;
tanh
--------------------
0.9950547536867306
(1 row)
btrim
btrim,从字符串的开头和结尾删除指定的字符。oracle 数据库不存在 btrim。
postgresql 也自带了这个函数,orafce 对这个函数做了改进,orafce 对 btrim 函数的更改对比:
-- 未安装 orafce
postgres=# \df btrim
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ --------------------- ------
pg_catalog | btrim | bytea | bytea, bytea | func
pg_catalog | btrim | text | text | func
pg_catalog | btrim | text | text, text | func
(3 rows)
-- 安装 orafce
postgres=# \df btrim
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ ---------------------- ------
oracle | btrim | text | character | func
oracle | btrim | text | character, character | func
oracle | btrim | text | character, nvarchar2 | func
oracle | btrim | text | character, text | func
oracle | btrim | text | character, varchar2 | func
oracle | btrim | text | nvarchar2 | func
oracle | btrim | text | nvarchar2, character | func
oracle | btrim | text | nvarchar2, nvarchar2 | func
oracle | btrim | text | nvarchar2, text | func
oracle | btrim | text | nvarchar2, varchar2 | func
oracle | btrim | text | text | func
oracle | btrim | text | text, character | func
oracle | btrim | text | text, nvarchar2 | func
oracle | btrim | text | text, text | func
oracle | btrim | text | text, varchar2 | func
oracle | btrim | text | varchar2 | func
oracle | btrim | text | varchar2, character | func
oracle | btrim | text | varchar2, nvarchar2 | func
oracle | btrim | text | varchar2, text | func
oracle | btrim | text | varchar2, varchar2 | func
pg_catalog | btrim | bytea | bytea, bytea | func
(21 rows)
使用 postgresql 自带的 btrim 函数处理的字符串如果是 char 类型,则会删除行尾空格,然后删除修剪字符。
在以下示例中,将返回从 “aabcaba” 两端删除 “a” 的字符串。
-- 使用 postgresql 自带的 btrim 函数,先删除行尾空格,然后删除修剪字符
postgres=# create table tt (id int,name char(10));
postgres=# insert into tt values (3,'aabcaba');
insert 0 1
postgres=# select name, btrim(name,'a') from tt where id=3;
name | btrim
------------ -------
aabcaba | bcab
(1 row)
-- 使用 orafce 的 length 函数,不会删除行尾空格
postgres=# select name, btrim(name,'a') from tt where id=3;
name | btrim
------------ ----------
aabcaba | bcaba
(1 row)
instr
instr,返回字符串中子字符串的位置。
postgres=# \df instr
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ ------------------------------------------------- ------
pg_catalog | instr | integer | str text, patt text | func
pg_catalog | instr | integer | str text, patt text, start integer | func
pg_catalog | instr | integer | str text, patt text, start integer, nth integer | func
(3 rows)
在以下示例中,在字符串 “abcacbcaac” 中找到字符 “bc” ,并返回这些字符的位置。
postgres=# select instr('abcacbcaac','bc') from dual;
instr
-------
2
(1 row)
postgres=# select instr('abcacbcaac','bc',-1,2) from dual;
instr
-------
2
(1 row)
length
length,以字符个数返回字符串的长度。
postgresql 也自带了这个函数,但是使用 postgresql 自带的 length 函数处理的字符串是 char 类型,则长度中不包含行尾空格。
-- 未安装 orafce
postgres=# \df length
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
pg_catalog | length | integer | bit | func
pg_catalog | length | integer | bytea | func
pg_catalog | length | integer | bytea, name | func
pg_catalog | length | integer | character | func
pg_catalog | length | double precision | lseg | func
pg_catalog | length | double precision | path | func
pg_catalog | length | integer | text | func
pg_catalog | length | integer | tsvector | func
(8 rows)
-- 安装 orafce
postgres=# \df length
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
oracle | length | integer | character | func
pg_catalog | length | integer | bit | func
pg_catalog | length | integer | bytea | func
pg_catalog | length | integer | bytea, name | func
pg_catalog | length | double precision | lseg | func
pg_catalog | length | double precision | path | func
pg_catalog | length | integer | text | func
pg_catalog | length | integer | tsvector | func
(8 rows)
在以下示例中,将返回表 tt 中 name 列(使用 char(10) 定义)中的字符数。
-- 使用 postgresql 自带的 length 函数,char(10) 返回 4 ,不包含行尾空格
postgres=# create table tt (id int,name char(10));
create table
postgres=# insert into tt values (1,'aaaa');
insert 0 1
postgres=# select name, length(name) from tt where id=1;
name | length
------------ --------
aaaa | 4
(1 row)
-- 在 oracle 中的 length 函数,char(10) 返回 10 ,包含行尾空格
sql> create table tt (id int,name char(10));
sql> insert into tt values (1,'aaaa');
sql> select name, length(name) from tt where id=1;
name length(name)
---------- ------------
aaaa 10
-- 使用 orafce 的 length 函数,char(10) 返回 10 ,包含行尾空格,与 oracle 相符合
postgres=# create table tt (id int,name char(10));
create table
postgres=# insert into tt values (1,'aaaa');
insert 0 1
postgres=# select name, length(name) from tt where id=1;
name | length
------------ --------
aaaa | 10
(1 row)
lengthb
lengthb,以字节数返回字符串的长度。
lengthb 函数处理的字符串是 char 类型,则长度中会包含行尾空格。
postgres=# \df lengthb
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ --------------------- ------
pg_catalog | lengthb | integer | varchar2 | func
(1 row)
在以下示例中,将返回表 tt 中列 name(使用 char(10) 定义)中的字节数。注意,在第二个 select 语句中,每个汉字的长度为 3 个字节,两个汉字总共 6 个字节,其中 8 个行尾空格增加了 8 个字节,这给出了 14 个字节的结果。
drop table tt;
create table tt (id int,name char(10));
insert into tt values (1,'aaaaa');
insert into tt values (3,'中国');
postgres=# select name, lengthb(name) from tt where id = 1;
name | lengthb
------------ ---------
aaaaa | 10
(1 row)
postgres=# select name, lengthb(name) from tt where id = 3;
name | lengthb
-------------- ---------
中国 | 14
(1 row)
--但是 oracle 统计中文还是 10 个字节
sql> select name, lengthb(name) from tt where id = 3;
name lengthb(name)
---------- -------------
中国 10
sql> select lengthb('中国') from dual;
lengthb('??????')
-----------------
6
对于中文的字节数统计有点迷糊,如果应用程序代码中存在 lengthb ,需要额外关注一下。
lpad
lpad,在字符串的左边填充指定长度的字符串
postgresql 也自带了这个函数,但是使用 postgresql 自带的 lpad 函数处理的字符串如果是 char 类型,则删除行尾空格,然后将填充字符添加到字符串中。
-- 未安装 orafce
postgres=# \df lpad
list of functions
schema | name | result data type | argument data types | type
------------ ------ ------------------ --------------------- ------
pg_catalog | lpad | text | text, integer | func
pg_catalog | lpad | text | text, integer, text | func
(2 rows)
-- 安装 orafce
postgres=# \df lpad
list of functions
schema | name | result data type | argument data types | type
-------- ------ ------------------ ------------------------------- ------
oracle | lpad | text | bigint, integer, integer | func
oracle | lpad | text | character, integer | func
oracle | lpad | text | character, integer, character | func
oracle | lpad | text | character, integer, nvarchar2 | func
oracle | lpad | text | character, integer, text | func
oracle | lpad | text | character, integer, varchar2 | func
oracle | lpad | text | integer, integer, integer | func
oracle | lpad | text | numeric, integer, integer | func
oracle | lpad | text | nvarchar2, integer | func
oracle | lpad | text | nvarchar2, integer, character | func
oracle | lpad | text | nvarchar2, integer, nvarchar2 | func
oracle | lpad | text | nvarchar2, integer, text | func
oracle | lpad | text | nvarchar2, integer, varchar2 | func
oracle | lpad | text | smallint, integer, integer | func
oracle | lpad | text | text, integer | func
oracle | lpad | text | text, integer, character | func
oracle | lpad | text | text, integer, nvarchar2 | func
oracle | lpad | text | text, integer, text | func
oracle | lpad | text | text, integer, varchar2 | func
oracle | lpad | text | varchar2, integer | func
oracle | lpad | text | varchar2, integer, character | func
oracle | lpad | text | varchar2, integer, nvarchar2 | func
oracle | lpad | text | varchar2, integer, text | func
oracle | lpad | text | varchar2, integer, varchar2 | func
(24 rows)
在下面的示例中,返回一个 20 个字符的字符串,该字符串是通过在 ‘abc’ 的左边填充 ‘a’ 而形成的。
drop table tt;
create table tt (id int,name char(10));
insert into tt values (1,'abc');
-- 使用 postgresql 自带的 lpad 函数,会先删除行尾空格,再填充字符
postgres=# select name, lpad(name,20,'a') from tt;
name | lpad
------------ ----------------------
abc | aaaaaaaaaaaaaaaaaabc
(1 row)
-- 在 oracle 中的 lpad 函数,不会删除行尾空格
sql> select name, lpad(name,20,'a') from tt;
name lpad(name,20,'a')
---------- ----------------------------------------
abc aaaaaaaaaaabc
-- 使用 orafce 的 lpad 函数,也不会删除行尾空格,与 oracle 相符合
postgres=# select name, lpad(name,20,'a') from tt;
name | lpad
------------ ----------------------
abc | aaaaaaaaaaabc
(1 row)
rpad
rpad,在字符串的右边填充指定长度的字符串,与 lpad 类似
ltrim
ltrim,从字符串的开头删除指定的字符。
postgresql 也自带了这个函数,但是使用 postgresql 自带的 ltrim 函数处理的字符串如果是 char 类型,则先删除行尾空格,然后删除修剪字符。
-- 未安装 orafce
postgres=# \df ltrim
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ --------------------- ------
pg_catalog | ltrim | text | text | func
pg_catalog | ltrim | text | text, text | func
(2 rows)
-- 安装 orafce
postgres=# \df ltrim
list of functions
schema | name | result data type | argument data types | type
-------- ------- ------------------ ---------------------- ------
oracle | ltrim | text | character | func
oracle | ltrim | text | character, character | func
oracle | ltrim | text | character, nvarchar2 | func
oracle | ltrim | text | character, text | func
oracle | ltrim | text | character, varchar2 | func
oracle | ltrim | text | nvarchar2 | func
oracle | ltrim | text | nvarchar2, character | func
oracle | ltrim | text | nvarchar2, nvarchar2 | func
oracle | ltrim | text | nvarchar2, text | func
oracle | ltrim | text | nvarchar2, varchar2 | func
oracle | ltrim | text | text | func
oracle | ltrim | text | text, character | func
oracle | ltrim | text | text, nvarchar2 | func
oracle | ltrim | text | text, text | func
oracle | ltrim | text | text, varchar2 | func
oracle | ltrim | text | varchar2 | func
oracle | ltrim | text | varchar2, character | func
oracle | ltrim | text | varchar2, nvarchar2 | func
oracle | ltrim | text | varchar2, text | func
oracle | ltrim | text | varchar2, varchar2 | func
(20 rows)
在下面的示例中,将返回从 “aabcab” 开头删除 “ab” 的字符串。
drop table tt;
create table tt (id int,name char(10));
insert into tt values (1,'aabcab');
-- 使用 postgresql 自带的 ltrim 函数,会先删除行尾空格,再删除修剪字符
postgres=# select name, ltrim(name,'ab'), length(ltrim(name,'ab')) from tt;
name | ltrim | length
------------ ------- --------
aabcab | cab | 3
(1 row)
-- 在 oracle 中的 ltrim 函数,不会删除行尾空格
sql> select name, ltrim(name,'ab'), length(ltrim(name,'ab')) from tt;
name ltrim(name length(ltrim(name,'ab'))
---------- ---------- ------------------------
aabcab cab 7
-- 使用 orafce 的 ltrim 函数,也不会删除行尾空格,与 oracle 相符合
postgres=# select name, ltrim(name,'ab'), length(ltrim(name,'ab')) from tt;
name | ltrim | length
------------ --------- --------
aabcab | cab | 7
(1 row)
rtrim
rtrim,从字符串的末尾删除指定的字符,与 ltrim 类似
nlssort
nlssort,用于在与默认语言环境不同的语言环境 (collate) 的整理顺序中进行比较和排序。
postgres=# \df nlssort
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ --------------------- ------
pg_catalog | nlssort | bytea | text | func
pg_catalog | nlssort | bytea | text, text | func
(2 rows)
示例:
drop table tt;
create table tt (id int,name varchar2(10));
insert into tt values (1001,'aabcabbc'),(2001,'abcdef'),(3001,'aacbaab');
postgres=# select id, name from tt order by nlssort(name,'da_dk.utf8');
id | name
------ ----------
2001 | abcdef
1001 | aabcabbc
3001 | aacbaab
(3 rows)
postgres=# select id, name from tt order by nlssort(name,'en_us.utf8');
id | name
------ ----------
1001 | aabcabbc
3001 | aacbaab
2001 | abcdef
(3 rows)
-- 可以使用 select 语句设置 set_nls_sort 语言环境
postgres=# select set_nls_sort('da_dk.utf8');
postgres=# select id, name from tt order by nlssort(name);
id | name
------ ----------
2001 | abcdef
1001 | aabcabbc
3001 | aacbaab
(3 rows)
postgres=# select set_nls_sort('en_us.utf8');
postgres=# select id, name from tt order by nlssort(name);
id | name
------ ----------
1001 | aabcabbc
3001 | aacbaab
2001 | abcdef
(3 rows)
regexp_count
regexp_count,在字符串中搜索正则表达式,并返回匹配的个数。
postgres=# \df regexp_count
list of functions
schema | name | result data type | argument data types | type
-------- -------------- ------------------ --------------------------- ------
oracle | regexp_count | integer | text, text | func
oracle | regexp_count | integer | text, text, integer | func
oracle | regexp_count | integer | text, text, integer, text | func
(3 rows)
示例:
postgres=# select regexp_count('a'||chr(10)||'d', 'a.d') from dual;
regexp_count
--------------
0
(1 row)
postgres=# select regexp_count('a'||chr(10)||'d', 'a.d', 1, 'm') from dual;
regexp_count
--------------
0
(1 row)
postgres=# select regexp_count('a'||chr(10)||'d', 'a.d', 1, 'n') from dual;
regexp_count
--------------
1
(1 row)
postgres=# select regexp_count('a'||chr(10)||'d', '^d$', 1, 'm') from dual;
regexp_count
--------------
1
(1 row)
regexp_instr
regexp_instr,返回模式匹配所在的字符串中的开始或结束位置。
postgres=# \df regexp_instr
list of functions
schema | name | result data type | argument data types | type
-------- -------------- ------------------ ------------------------------------------------------ ------
oracle | regexp_instr | integer | text, text | func
oracle | regexp_instr | integer | text, text, integer | func
oracle | regexp_instr | integer | text, text, integer, integer | func
oracle | regexp_instr | integer | text, text, integer, integer, integer | func
oracle | regexp_instr | integer | text, text, integer, integer, integer, text | func
oracle | regexp_instr | integer | text, text, integer, integer, integer, text, integer | func
(6 rows)
示例:
postgres=# select regexp_instr('1234567890', '(123)(4(56)(78))') from dual;
regexp_instr
--------------
1
(1 row)
postgres=# select regexp_instr('1234567890', '(4(56)(78))', 3) from dual;
regexp_instr
--------------
4
(1 row)
postgres=# select regexp_instr('199 oretax prayers, riffles stream, ca', '[s|r|p][[:alpha:]]{6}', 3, 2, 1) from dual;
regexp_instr
--------------
28
(1 row)
-- 以下这个返回的结果是错误的,版本 orafce 3.18
postgres=# select regexp_instr('123 123456 1234567, 1234567 1234567 12', '[^ ] ', 1, 6) from dual;
regexp_instr
--------------
1
(1 row)
sql> select regexp_instr('123 123456 1234567, 1234567 1234567 12', '[^ ] ', 1, 6) from dual;
regexp_instr('1231234561234567,1234567123456712','[^] ',1,6)
------------------------------------------------------------
37
此问题已解决,详见:
create or replace function public.regexp_instr(text, text, integer, integer)
returns integer
language plpgsql
strict
as $function$
declare
v_pos integer;
v_pattern text;
r record;
start_pos integer default 1;
new_start integer;
begin
if $3 < 1 then
raise exception 'argument ''position'' must be a number greater than 0';
end if;
if $4 < 1 then
raise exception 'argument ''occurence'' must be a number greater than 0';
end if;
-- without subexpression specified, assume 0 which mean that the first
-- position for the substring matching the whole pattern is returned.
-- we need to enclose the pattern between parentheses.
v_pattern := '(' || $2 || ')';
-- oracle default behavior is newline-sensitive,
-- postgresql not, so force 'p' modifier to affect
-- newline-sensitivity but not ^ and $ search.
$1 := substr($1, $3);
start_pos := $3;
for r in select (regexp_matches($1, v_pattern, 'pg'))[1]
loop
v_pos := position(r.regexp_matches in $1);
if $4 = 1 then
return v_pos start_pos - 1;
else
$4 := $4 - 1;
end if;
new_start := v_pos length(r.regexp_matches);
$1 := substr($1, new_start);
start_pos := start_pos new_start - 1;
end loop;
return 0;
end;
$function$
;
postgres=# select regexp_instr('123 123456 1234567, 1234567 1234567 12', '[^ ] ', 1, 6) from dual;
regexp_instr
--------------
37
(1 row)
regexp_like
regexp_like,返回一个布尔值,用于确定字符串是否匹配正则表达式
postgres=# \df regexp_like
list of functions
schema | name | result data type | argument data types | type
-------- ------------- ------------------ --------------------- ------
oracle | regexp_like | boolean | text, text | func
oracle | regexp_like | boolean | text, text, text | func
(2 rows)
示例:
postgres=# select regexp_like('a'||chr(10)||'d', 'a.d', 'm') from dual;
regexp_like
-------------
f
(1 row)
postgres=# select regexp_like('a'||chr(10)||'d', 'a.d', 'n') from dual;
regexp_like
-------------
t
(1 row)
regexp_substr
regexp_substr,返回与函数调用中指定的模式匹配的字符串。
postgres=# \df regexp_substr
list of functions
schema | name | result data type | argument data types | type
-------- --------------- ------------------ --------------------------------------------- ------
oracle | regexp_substr | text | text, text | func
oracle | regexp_substr | text | text, text, integer | func
oracle | regexp_substr | text | text, text, integer, integer | func
oracle | regexp_substr | text | text, text, integer, integer, text | func
oracle | regexp_substr | text | text, text, integer, integer, text, integer | func
(5 rows)
示例:
postgres=# select regexp_substr('number of your street, zipcode town, fr', ',[^,] ') from dual;
regexp_substr
----------------
, zipcode town
(1 row)
postgres=# select regexp_substr('number of your street, zipcode town, fr', ',[^,] ', 24) from dual;
regexp_substr
---------------
, fr
(1 row)
postgres=# select regexp_substr('number of your street, zipcode town, fr', ',[^,] ', 1, 2) from dual;
regexp_substr
---------------
, fr
(1 row)
postgres=# select regexp_substr('1234567890 1234567890', '(123)(4(56)(78))', 1, 1, 'i', 0) from dual;
regexp_substr
---------------
12345678
(1 row)
regexp_replace
regexp_replace,返回与函数调用中指定的模式匹配的字符串。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df regexp_replace
list of functions
schema | name | result data type | argument data types | type
------------ ---------------- ------------------ ------------------------ ------
pg_catalog | regexp_replace | text | text, text, text | func
pg_catalog | regexp_replace | text | text, text, text, text | func
(2 rows)
-- 安装 orafce
postgres=# \df regexp_replace
list of functions
schema | name | result data type | argument data types | type
------------ ---------------- ------------------ ------------------------------------------ ------
oracle | regexp_replace | text | text, text, text | func
oracle | regexp_replace | text | text, text, text, integer | func
oracle | regexp_replace | text | text, text, text, integer, integer | func
oracle | regexp_replace | text | text, text, text, integer, integer, text | func
pg_catalog | regexp_replace | text | text, text, text, text | func
(5 rows)
示例:
postgres=# select regexp_replace('512.123.4567 612.123.4567', '([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})', '(\1) \2-\3') from dual;
regexp_replace
-------------------------------
(512) 123-4567 (612) 123-4567
(1 row)
postgres=# select oracle.regexp_replace('number your street, zipcode town, fr', '( ){2,}', ' ', 9);
regexp_replace
----------------------------------------
number your street, zipcode town, fr
(1 row)
postgres=# select oracle.regexp_replace('number your street, zipcode town, fr', '( ){2,}', ' ', 9, 2);
regexp_replace
---------------------------------------------
number your street, zipcode town, fr
(1 row)
substr
substr,在字符串的提取指定位置和长度的一部分字符。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df substr
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ ------------------------- ------
pg_catalog | substr | bytea | bytea, integer | func
pg_catalog | substr | bytea | bytea, integer, integer | func
pg_catalog | substr | text | text, integer | func
pg_catalog | substr | text | text, integer, integer | func
(4 rows)
-- 安装 orafce
postgres=# \df substr
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ -------------------------------------- ------
oracle | substr | text | character varying, numeric | func
oracle | substr | text | character varying, numeric, numeric | func
oracle | substr | text | numeric, numeric | func
oracle | substr | text | numeric, numeric, numeric | func
oracle | substr | text | str text, start integer | func
oracle | substr | text | str text, start integer, len integer | func
pg_catalog | substr | bytea | bytea, integer | func
pg_catalog | substr | bytea | bytea, integer, integer | func
(8 rows)
示例:
postgres=# select substr('abcdefg',3,4) "substring" from dual;
substring
-----------
cdef
(1 row)
postgres=# select substr('abcdefg',-5,4) "substring" from dual;
substring
-----------
cdef
(1 row)
substrb
substrb,在字符串的提取指定位置和长度的一部分字符。
postgres=# \df substrb
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ ---------------------------- ------
pg_catalog | substrb | varchar2 | varchar2, integer | func
pg_catalog | substrb | varchar2 | varchar2, integer, integer | func
(2 rows)
示例:
postgres=# select substrb('aaabbbccc',4,3) from dual;
substrb
---------
bbb
(1 row)
-- 以下这个返回的结果应该是错误的
postgres=# select substrb('aaabbbccc',-2,6) from dual;
substrb
---------
aaa
(1 row)
sql> select substrb('aaabbbccc',-2,6) from dual;
su
--
cc
问题已解决,详见:https://www.modb.pro/db/389172
add_months
add_months,返回加月份的日期
postgres=# \df add_months
list of functions
schema | name | result data type | argument data types | type
------------ ------------ ----------------------------- ------------------------------------ ------
oracle | add_months | timestamp without time zone | timestamp with time zone, integer | func
pg_catalog | add_months | pg_catalog.date | day pg_catalog.date, value integer | func
(2 rows)
下面的示例显示了在 2016 年 5 月 1 日上加 3 个月的结果。
postgres=# select add_months(to_date('2016/05/01','yyyy/mm/dd'),3) from dual;
add_months
---------------------
2016-08-01 00:00:00
(1 row)
dbtimezone
dbtimezone,返回数据库时区
postgres=# \df dbtimezone
list of functions
schema | name | result data type | argument data types | type
-------- ------------ ------------------ --------------------- ------
oracle | dbtimezone | text | | func
(1 row)
示例:
postgres=# select dbtimezone() from dual;
dbtimezone
------------
prc
(1 row)
-- oracle,加括号会报错误,但这个函数在程序上一般用不上
sql> select dbtimezone() from dual;
select dbtimezone() from dual
*
error at line 1:
ora-00923: from keyword not found where expected
sql> select dbtimezone from dual;
dbtime
------
00:00
sessiontimezone
sessiontimezone,返回会话的时区。
postgres=# \df sessiontimezone
list of functions
schema | name | result data type | argument data types | type
-------- ----------------- ------------------ --------------------- ------
oracle | sessiontimezone | text | | func
(1 row)
在以下示例中,将返回会话的时区。
postgres=# select sessiontimezone() from dual;
sessiontimezone
-----------------
prc
(1 row)
-- oracle,加括号会报错误,但这个函数在程序上一般用不上
sql> select sessiontimezone() from dual;
select sessiontimezone() from dual
*
error at line 1:
ora-00923: from keyword not found where expected
sql> select sessiontimezone from dual;
sessiontimezone
---------------------------------------------------------------------------
08:00
last_day
last_day,返回指定日期所在月份的最后一天
postgres=# \df last_day
list of functions
schema | name | result data type | argument data types | type
------------ ---------- ----------------------------- -------------------------- ------
oracle | last_day | timestamp without time zone | timestamp with time zone | func
pg_catalog | last_day | pg_catalog.date | value pg_catalog.date | func
(2 rows)
在下面的示例中,返回 “2016 年 2 月 1 日” 的最后日期:
postgres=# select last_day(to_date('2016/02/01','yyyy/mm/dd')) from dual;
last_day
---------------------
2016-02-29 00:00:00
(1 row)
months_between
months_between,返回两个日期之间的月数
postgres=# \df months_between
list of functions
schema | name | result data type | argument data types | type
------------ ---------------- ------------------ ---------------------------------------------------- ------
oracle | months_between | numeric | timestamp with time zone, timestamp with time zone | func
pg_catalog | months_between | numeric | date1 pg_catalog.date, date2 pg_catalog.date | func
(2 rows)
在以下示例中,将返回 “2016 年 3 月 15 日” 和 “2015 年 11 月 15 日” 之间的月份差。
postgres=# select months_between(to_date('2016/03/15','yyyy/mm/dd'), to_date('2015/11/15','yyyy/mm/dd')) from dual;
months_between
----------------
4
(1 row)
next_day
next_day,返回指定日期之后一周内特定日期的日期。
postgres=# \df next_day
list of functions
schema | name | result data type | argument data types | type
------------ ---------- ----------------------------- ---------------------------------------- ------
oracle | next_day | timestamp without time zone | timestamp with time zone, integer | func
oracle | next_day | timestamp without time zone | timestamp with time zone, text | func
pg_catalog | next_day | pg_catalog.date | value pg_catalog.date, weekday integer | func
pg_catalog | next_day | pg_catalog.date | value pg_catalog.date, weekday text | func
(4 rows)
在下面的示例中,返回 “2016 年 5 月 1 日” 之后的第一个星期五的日期。
postgres=# select next_day(to_date('2016/05/01','yyyy/mm/dd'), 'friday') from dual;
next_day
---------------------
2016-05-06 00:00:00
(1 row)
postgres=# select next_day(to_date('2016/05/01','yyyy/mm/dd'), 6) from dual;
next_day
---------------------
2016-05-06 00:00:00
(1 row)
round and trunc
round,对日期进行四舍五入。trunc,截断日期,截取时不进行四舍五入。
postgresql 也自带了这两个函数,但是不能操作日期类型,orafce 对这两个函数做个改进。
-- 未安装 orafce
postgres=# \df round
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ --------------------- ------
pg_catalog | round | double precision | double precision | func
pg_catalog | round | numeric | numeric | func
pg_catalog | round | numeric | numeric, integer | func
(3 rows)
postgres=# \df trunc
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ --------------------- ------
pg_catalog | trunc | double precision | double precision | func
pg_catalog | trunc | macaddr | macaddr | func
pg_catalog | trunc | macaddr8 | macaddr8 | func
pg_catalog | trunc | numeric | numeric | func
pg_catalog | trunc | numeric | numeric, integer | func
(5 rows)
-- 安装 orafce
postgres=# \df round
list of functions
schema | name | result data type | argument data types | type
------------ ------- ----------------------------- --------------------------------------------- ------
oracle | round | numeric | double precision, integer | func
oracle | round | numeric | real, integer | func
pg_catalog | round | double precision | double precision | func
pg_catalog | round | numeric | numeric | func
pg_catalog | round | numeric | numeric, integer | func
pg_catalog | round | pg_catalog.date | value pg_catalog.date | func
pg_catalog | round | pg_catalog.date | value pg_catalog.date, fmt text | func
pg_catalog | round | timestamp without time zone | value timestamp without time zone | func
pg_catalog | round | timestamp without time zone | value timestamp without time zone, fmt text | func
pg_catalog | round | timestamp with time zone | value timestamp with time zone | func
pg_catalog | round | timestamp with time zone | value timestamp with time zone, fmt text | func
(11 rows)
postgres=# \df trunc
list of functions
schema | name | result data type | argument data types | type
------------ ------- ----------------------------- --------------------------------------------- ------
oracle | trunc | numeric | double precision, integer | func
oracle | trunc | numeric | real, integer | func
pg_catalog | trunc | double precision | double precision | func
pg_catalog | trunc | macaddr | macaddr | func
pg_catalog | trunc | macaddr8 | macaddr8 | func
pg_catalog | trunc | numeric | numeric | func
pg_catalog | trunc | numeric | numeric, integer | func
pg_catalog | trunc | pg_catalog.date | value pg_catalog.date | func
pg_catalog | trunc | pg_catalog.date | value pg_catalog.date, fmt text | func
pg_catalog | trunc | timestamp without time zone | value timestamp without time zone | func
pg_catalog | trunc | timestamp without time zone | value timestamp without time zone, fmt text | func
pg_catalog | trunc | timestamp with time zone | value timestamp with time zone | func
pg_catalog | trunc | timestamp with time zone | value timestamp with time zone, fmt text | func
(13 rows)
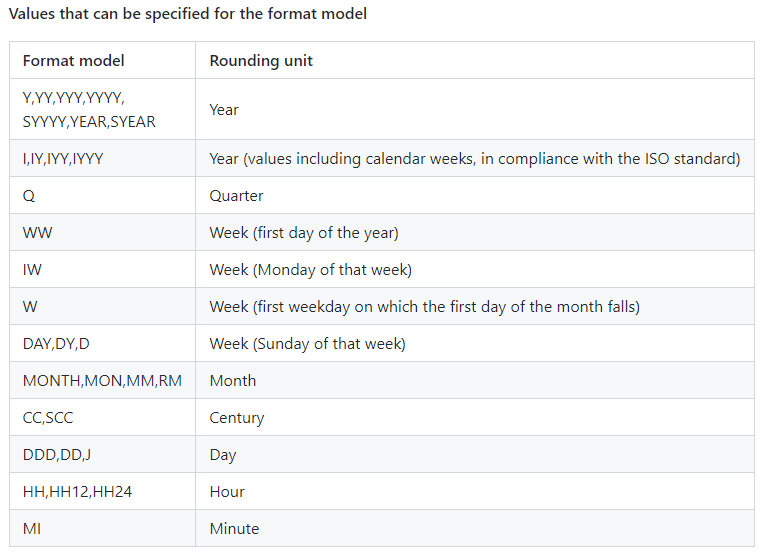
在下面的示例中,返回 “2016 年 6 月 20 日 18:00:00” 按星期几进行四舍五入的结果。
postgres=# select round(to_date('2016/06/20 18:00:00','yyyy/mm/dd hh24:mi:ss'),'day') from dual;
round
---------------------
2016-06-19 00:00:00
(1 row)
在下面的示例中,返回按天截断的 “2016 年 8 月 10 日 15:30:00” 的结果。
postgres=# select trunc(to_date('2016/08/10 15:30:00','yyyy/mm/dd hh24:mi:ss'),'day') from dual;
trunc
---------------------
2016-08-07 00:00:00
(1 row)
sysdate
sysdate,返回系统日期。
postgres=# \df sysdate
list of functions
schema | name | result data type | argument data types | type
-------- --------- ------------------ --------------------- ------
oracle | sysdate | date | | func
(1 row)
在以下示例中,将返回系统日期。
postgres=# select sysdate() from dual;
sysdate
---------------------
2022-04-01 21:54:40
(1 row)
postgres=# select sysdate from dual;
error: column "sysdate" does not exist
line 1: select sysdate from dual;
-- 问题:sysdate需要加括号(),而 oracle 不带括号()
sql> select sysdate from dual;
sysdate
-------------------
2022-04-01 21:55:03
使用 sysdate 作为默认值建表
postgres=# create table channels (
postgres(# updatetimestamp date default (sysdate),
postgres(# createtimestamp date default (sysdate)
postgres(# );
error: cannot use column reference in default expression
line 2: updatetimestamp date default (sysdate),
^
postgres=# create table channels2 (
postgres(# updatetimestamp date default (sysdate()),
postgres(# createtimestamp date default (sysdate())
postgres(# );
create table
题外话,oracle 的 sysdate 函数与 postgresql 的哪个时间函数最类似
postgres=# select pg_sleep(5),clock_timestamp() from generate_series(1,2);
pg_sleep | clock_timestamp
---------- -------------------------------
| 2022-03-31 16:59:43.000442 08
| 2022-03-31 16:59:48.00597 08
(2 rows)
postgres=# select pg_sleep(5),now() from generate_series(1,2);
pg_sleep | now
---------- -------------------------------
| 2022-03-31 17:00:05.911341 08
| 2022-03-31 17:00:05.911341 08
(2 rows)
postgres=# select pg_sleep(5),transaction_timestamp() from generate_series(1,2);
pg_sleep | transaction_timestamp
---------- -------------------------------
| 2022-03-31 17:00:42.874299 08
| 2022-03-31 17:00:42.874299 08
(2 rows)
postgres=# select pg_sleep(5),current_timestamp from generate_series(1,2);
pg_sleep | current_timestamp
---------- -------------------------------
| 2022-03-31 17:01:55.394196 08
| 2022-03-31 17:01:55.394196 08
(2 rows)
postgres=# select pg_sleep(5),statement_timestamp() from generate_series(1,2);
pg_sleep | statement_timestamp
---------- -------------------------------
| 2022-03-31 17:02:24.156702 08
| 2022-03-31 17:02:24.156702 08
(2 rows)
postgres=# select pg_sleep(5),oracle.sysdate() from generate_series(1,2);
pg_sleep | sysdate
---------- ---------------------
| 2022-03-31 09:15:25
| 2022-03-31 09:15:25
(2 rows)
只有 clock_timestamp()函数在单个事务中返回不同的时间信息。
oracle 中的 sysdate 不带 timezone,oracle 的 sysdate 从 sql 开始时取值,整个 sql 执行期间不变。
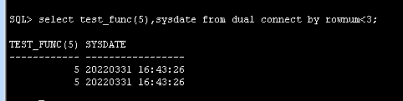
test_func 每次 sleep 5秒,在oracle sysdate返回相同的结果
to_char
to_char,将值转换为字符串。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df to_char
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ ----------------------------------- ------
pg_catalog | to_char | text | bigint, text | func
pg_catalog | to_char | text | double precision, text | func
pg_catalog | to_char | text | integer, text | func
pg_catalog | to_char | text | interval, text | func
pg_catalog | to_char | text | numeric, text | func
pg_catalog | to_char | text | real, text | func
pg_catalog | to_char | text | timestamp without time zone, text | func
pg_catalog | to_char | text | timestamp with time zone, text | func
(8 rows)
-- 安装 orafce
postgres=# \df to_char
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ ----------------------------------- ------
oracle | to_char | text | timestamp without time zone | func
pg_catalog | to_char | text | bigint, text | func
pg_catalog | to_char | text | double precision, text | func
pg_catalog | to_char | text | integer, text | func
pg_catalog | to_char | text | interval, text | func
pg_catalog | to_char | text | num bigint | func
pg_catalog | to_char | text | num double precision | func
pg_catalog | to_char | text | numeric, text | func
pg_catalog | to_char | text | num integer | func
pg_catalog | to_char | text | num numeric | func
pg_catalog | to_char | text | num real | func
pg_catalog | to_char | text | num smallint | func
pg_catalog | to_char | text | real, text | func
pg_catalog | to_char | text | timestamp without time zone, text | func
pg_catalog | to_char | text | timestamp with time zone, text | func
(15 rows)
示例:
postgres=# select to_char(123.45) from dual;
to_char
---------
123.45
(1 row)
-- 转换日期格式
postgres=# select * from test_range;
id | create_time
---- ---------------------
1 | 2022-04-01 10:08:18
(1 row)
postgres=# select to_char(create_time,'yyyy/mm/dd hh24:mi:ss') from test_range;
to_char
---------------------
2022/04/01 10:08:18
(1 row)
-- 可以使用 orafce.nls_date_format 变量设置日期/时间格式
postgres=# set orafce.nls_date_format = 'yyyy/mm/dd hh24:mi:ss';
set
postgres=# select to_char(create_time) from test_range;
to_char
---------------------
2022/04/01 10:08:18
(1 row)
postgres=# set orafce.nls_date_format = 'yyyy-mm-dd hh24:mi:ss';
set
postgres=# select to_char(create_time) from test_range;
to_char
---------------------
2022-04-01 10:08:18
(1 row)
to_date
to_date,根据指定格式将字符串转换为日期。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df to_date
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ --------------------- ------
pg_catalog | to_date | date | text, text | func
(1 row)
-- 安装 orafce
postgres=# \df to_date
list of functions
schema | name | result data type | argument data types | type
-------- --------- ------------------ --------------------- ------
oracle | to_date | date | text | func
oracle | to_date | date | text, text | func
(2 rows)
在以下示例中,字符串 “2016/12/31” 被转换为日期并返回
postgres=# select to_date('2016/12/31','yyyy/mm/dd') from dual;
to_date
---------------------
2016-12-31 00:00:00
(1 row)
-- 问题:orafce.nls_date_format 似乎对 to_date 不起作用
postgres=# set orafce.nls_date_format = 'yyyy/mm/dd hh24:mi:ss';
set
postgres=# select to_date('2016/12/31','yyyy/mm/dd') from dual;
to_date
---------------------
2016-12-31 00:00:00
(1 row)
to_number
to_number,根据指定格式将值转换为数字。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df to_number
list of functions
schema | name | result data type | argument data types | type
------------ ----------- ------------------ --------------------- ------
pg_catalog | to_number | numeric | text, text | func
(1 row)
-- 安装 orafce
postgres=# \df to_number
list of functions
schema | name | result data type | argument data types | type
------------ ----------- ------------------ --------------------- ------
pg_catalog | to_number | numeric | numeric | func
pg_catalog | to_number | numeric | numeric, numeric | func
pg_catalog | to_number | numeric | str text | func
pg_catalog | to_number | numeric | text, text | func
(4 rows)
示例:
-- 数字文字 "-130.5" 被转换为数值并返回。
postgres=# select to_number(-130.5) from dual;
to_number
-----------
-130.5
(1 row)
postgres=# select to_number('-130.5') from dual;
to_number
-----------
-130.5
(1 row)
-- 转换 varchar2
postgres=# \d tt2
table "public.tt2"
column | type | collation | nullable | default
-------- ---------------- ----------- ---------- ---------
id | varchar2(100) | | |
name | nvarchar2(100) | | |
ctime | date | | |
postgres=# select id, to_number(id) from tt2 where id = '3003963447';
id | to_number
------------ ------------
3003963447 | 3003963447
to_multi_byte
to_multi_byte,将单字节字符串转换为多字节字符串,也是将半角字符转换为全角字符。
postgres=# \df to_multi_byte
list of functions
schema | name | result data type | argument data types | type
-------- --------------- ------------------ --------------------- ------
public | to_multi_byte | text | str text | func
(1 row)
在以下示例中,“abc123” 被转换为全角字符并返回。
postgres=# select to_multi_byte('abc123') from dual;
to_multi_byte
---------------
abc123
(1 row)
to_single_byte
to_single_byte,将多字节字符串转换为单字节字符串,也是将全角字符转换为半角字符。
postgres=# \df to_single_byte
list of functions
schema | name | result data type | argument data types | type
-------- ---------------- ------------------ --------------------- ------
public | to_single_byte | text | str text | func
(1 row)
在以下示例中,“abc123” 被转换为半角字符并返回。
postgres=# select to_single_byte('abc123') from dual;
to_single_byte
----------------
abc123
(1 row)
decode
decode,比较值,如果它们匹配,则返回相应的值。
postgresql 也自带了这个函数,orafce 对这个函数做个改进。
-- 未安装 orafce
postgres=# \df decode
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
pg_catalog | decode | bytea | text, text | func
(1 row)
-- 安装 orafce
postgres=# \df decode
list of functions
schema | name | result data type | argument data types | type
------------ -------- ----------------------------- -------------------------------------------------------------------------------------------------------------------------------------------------------------------- ------
pg_catalog | decode | bytea | text, text | func
public | decode | bigint | anyelement, anyelement, bigint | func
public | decode | bigint | anyelement, anyelement, bigint, anyelement, bigint | func
public | decode | bigint | anyelement, anyelement, bigint, anyelement, bigint, anyelement, bigint | func
public | decode | bigint | anyelement, anyelement, bigint, anyelement, bigint, anyelement, bigint, bigint | func
public | decode | bigint | anyelement, anyelement, bigint, anyelement, bigint, bigint | func
public | decode | bigint | anyelement, anyelement, bigint, bigint | func
public | decode | character | anyelement, anyelement, character | func
public | decode | character | anyelement, anyelement, character, anyelement, character | func
public | decode | character | anyelement, anyelement, character, anyelement, character, anyelement, character | func
public | decode | character | anyelement, anyelement, character, anyelement, character, anyelement, character, character | func
public | decode | character | anyelement, anyelement, character, anyelement, character, character | func
public | decode | character | anyelement, anyelement, character, character | func
public | decode | integer | anyelement, anyelement, integer | func
public | decode | integer | anyelement, anyelement, integer, anyelement, integer | func
public | decode | integer | anyelement, anyelement, integer, anyelement, integer, anyelement, integer | func
public | decode | integer | anyelement, anyelement, integer, anyelement, integer, anyelement, integer, integer | func
public | decode | integer | anyelement, anyelement, integer, anyelement, integer, integer | func
public | decode | integer | anyelement, anyelement, integer, integer | func
public | decode | numeric | anyelement, anyelement, numeric | func
public | decode | numeric | anyelement, anyelement, numeric, anyelement, numeric | func
public | decode | numeric | anyelement, anyelement, numeric, anyelement, numeric, anyelement, numeric | func
public | decode | numeric | anyelement, anyelement, numeric, anyelement, numeric, anyelement, numeric, numeric | func
public | decode | numeric | anyelement, anyelement, numeric, anyelement, numeric, numeric | func
public | decode | numeric | anyelement, anyelement, numeric, numeric | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date, anyelement, pg_catalog.date | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date, anyelement, pg_catalog.date, anyelement, pg_catalog.date | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date, anyelement, pg_catalog.date, anyelement, pg_catalog.date, pg_catalog.date | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date, anyelement, pg_catalog.date, pg_catalog.date | func
public | decode | pg_catalog.date | anyelement, anyelement, pg_catalog.date, pg_catalog.date | func
public | decode | text | anyelement, anyelement, text | func
public | decode | text | anyelement, anyelement, text, anyelement, text | func
public | decode | text | anyelement, anyelement, text, anyelement, text, anyelement, text | func
public | decode | text | anyelement, anyelement, text, anyelement, text, anyelement, text, text | func
public | decode | text | anyelement, anyelement, text, anyelement, text, text | func
public | decode | text | anyelement, anyelement, text, text | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone, anyelement, timestamp without time zone | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone, anyelement, timestamp without time zone, anyelement, timestamp without time zone | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone, anyelement, timestamp without time zone, anyelement, timestamp without time zone, timestamp without time zone | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone, anyelement, timestamp without time zone, timestamp without time zone | func
public | decode | timestamp without time zone | anyelement, anyelement, timestamp without time zone, timestamp without time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone, anyelement, timestamp with time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone, anyelement, timestamp with time zone, anyelement, timestamp with time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone, anyelement, timestamp with time zone, anyelement, timestamp with time zone, timestamp with time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone, anyelement, timestamp with time zone, timestamp with time zone | func
public | decode | timestamp with time zone | anyelement, anyelement, timestamp with time zone, timestamp with time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone, anyelement, time without time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone, anyelement, time without time zone, anyelement, time without time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone, anyelement, time without time zone, anyelement, time without time zone, time without time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone, anyelement, time without time zone, time without time zone | func
public | decode | time without time zone | anyelement, anyelement, time without time zone, time without time zone | func
(55 rows)
- decode 将要转换的值与搜索值一一进行比较。如果值匹配,则返回相应的结果值。如果没有匹配的值,则返回已指定的默认值。如果未指定默认值,则返回 null 值。
- 如果多次指定相同的搜索值,则返回的结果值是为第一次出现的搜索值列出的值。
- 以下数据类型可用于结果值和默认值:
char
varchar
varchar2
nchar
nchar varying
nvarchar2
text
integer
bigint
numeric
date
time without time zone
timestamp without time zone
timestamp with time zone - decode 可以转换的数据类型组合(总结)
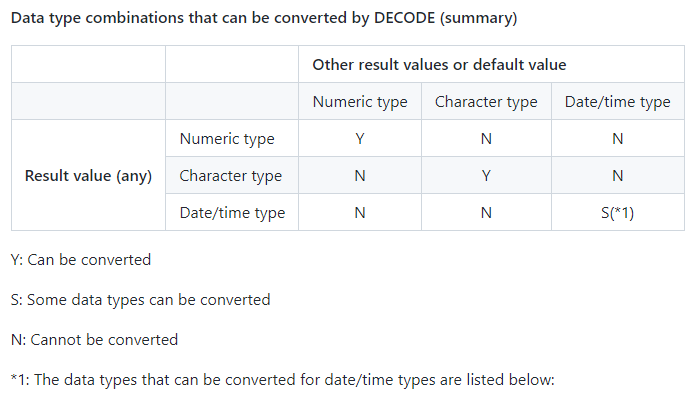
- 可通过 decode 转换的结果值和默认值日期/时间数据类型
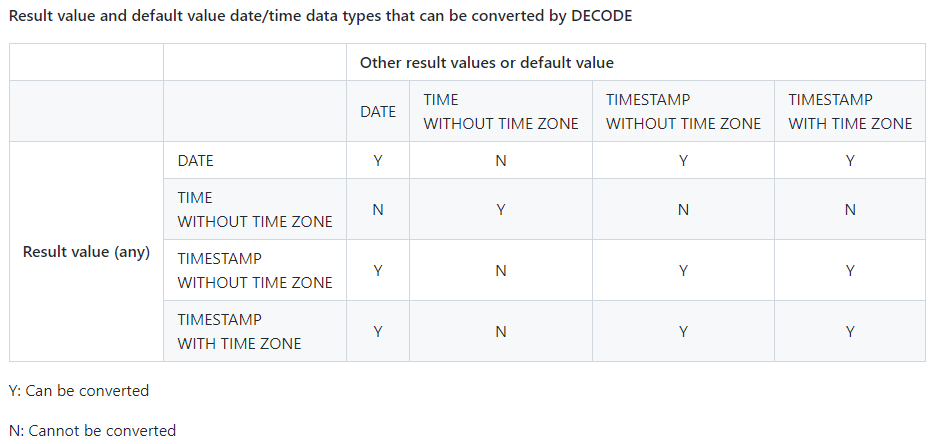
在以下示例中,比较表 t1 中 col3 的值并将其转换为不同的值。如果 col3 值与搜索值 1 匹配,则返回的结果值为 “one”。如果 col3 值不匹配任何搜索值 1、2 或 3,则返回默认值 “other number”。
drop table tt;
create table tt (col1 int,col3 int);
insert into tt values (1001,1),(2001,2),(3001,3),(4001,4);
select col1,
decode(col3, 1, 'one',
2, 'two',
3, 'three',
'other number') "num-word"
from tt;
col1 | num-word
------ --------------
1001 | one
2001 | two
3001 | three
4001 | other number
(4 rows)
greatest and least
greatest 和 least 函数从任意数量的表达式列表中选择最大值或最小值。表达式必须都可以转换为通用数据类型,这将是结果的类型
这两个函数与 postgresql 自带的行为相同,只是不是仅在所有参数为 null 时才返回 null ,而是在其中一个参数为 null 时返回 null ,就像在 oracle 中一样。
postgres=# \df greatest
list of functions
schema | name | result data type | argument data types | type
-------- ---------- ----------------------------- --------------------------------------------------------------------------------------- ------
oracle | greatest | anynonarray | anynonarray, variadic anyarray | func
oracle | greatest | bigint | bigint, bigint | func
oracle | greatest | bigint | bigint, bigint, bigint | func
oracle | greatest | character | character, character | func
oracle | greatest | character | character, character, character | func
oracle | greatest | integer | integer, integer | func
oracle | greatest | integer | integer, integer, integer | func
oracle | greatest | numeric | numeric, numeric | func
oracle | greatest | numeric | numeric, numeric, numeric | func
oracle | greatest | pg_catalog.date | pg_catalog.date, pg_catalog.date | func
oracle | greatest | pg_catalog.date | pg_catalog.date, pg_catalog.date, pg_catalog.date | func
oracle | greatest | smallint | smallint, smallint | func
oracle | greatest | smallint | smallint, smallint, smallint | func
oracle | greatest | text | text, text | func
oracle | greatest | text | text, text, text | func
oracle | greatest | timestamp without time zone | timestamp without time zone, timestamp without time zone | func
oracle | greatest | timestamp without time zone | timestamp without time zone, timestamp without time zone, timestamp without time zone | func
oracle | greatest | timestamp with time zone | timestamp with time zone, timestamp with time zone | func
oracle | greatest | timestamp with time zone | timestamp with time zone, timestamp with time zone, timestamp with time zone | func
oracle | greatest | time without time zone | time without time zone, time without time zone | func
oracle | greatest | time without time zone | time without time zone, time without time zone, time without time zone | func
(21 rows)
postgres=# \df least
list of functions
schema | name | result data type | argument data types | type
-------- ------- ----------------------------- --------------------------------------------------------------------------------------- ------
oracle | least | anynonarray | anynonarray, variadic anyarray | func
oracle | least | bigint | bigint, bigint | func
oracle | least | bigint | bigint, bigint, bigint | func
oracle | least | character | character, character | func
oracle | least | character | character, character, character | func
oracle | least | integer | integer, integer | func
oracle | least | integer | integer, integer, integer | func
oracle | least | numeric | numeric, numeric | func
oracle | least | numeric | numeric, numeric, numeric | func
oracle | least | pg_catalog.date | pg_catalog.date, pg_catalog.date | func
oracle | least | pg_catalog.date | pg_catalog.date, pg_catalog.date, pg_catalog.date | func
oracle | least | smallint | smallint, smallint | func
oracle | least | smallint | smallint, smallint, smallint | func
oracle | least | text | text, text | func
oracle | least | text | text, text, text | func
oracle | least | timestamp without time zone | timestamp without time zone, timestamp without time zone | func
oracle | least | timestamp without time zone | timestamp without time zone, timestamp without time zone, timestamp without time zone | func
oracle | least | timestamp with time zone | timestamp with time zone, timestamp with time zone | func
oracle | least | timestamp with time zone | timestamp with time zone, timestamp with time zone, timestamp with time zone | func
oracle | least | time without time zone | time without time zone, time without time zone | func
oracle | least | time without time zone | time without time zone, time without time zone, time without time zone | func
(21 rows)
示例:
-- 返回最大值
postgres=# select greatest ('c', 'f', 'e') from dual;
greatest
----------
f
(1 row)
-- 返回最小值,测试带 null 值的情况
-- postgresql 自带的行为,仅在所有参数为 null 时才返回 null
postgres=# \pset null ###
postgres=# select least ('c', null, 'e');
least
-------
c
(1 row)
postgres=# select least (null,null,null);
least
-------
###
(1 row)
-- oracle,其中一个参数为 null 时就返回 null
sql> select least ('c', null, 'e') from dual;
l
-
sql>
-- orafce,也是其中一个参数为 null 时就返回 null ,就像在 oracle 中一样。
postgres=# \pset null ###
postgres=# select oracle.least('c', null, 'e') from dual;
least
-------
###
(1 row)
lnnvl
lnnvl 确定指定条件的值是 true 还是 false。
如果条件的结果为 false 或 null,则返回 true。如果条件的结果为 true,则返回 false。
postgres=# \df lnnvl
list of functions
schema | name | result data type | argument data types | type
------------ ------- ------------------ --------------------- ------
pg_catalog | lnnvl | boolean | boolean | func
(1 row)
在以下示例中,当 col3 的值小于等于 2000 或为空值时,将返回表 tt 的 col1 和 col3。
drop table tt;
create table tt (col1 int,col3 int);
insert into tt values (1001,1000),(1002,2000),(2002,null),(3001,3000);
postgres=# select * from tt;
col1 | col3
------ ------
1001 | 1000
1002 | 2000
2002 |
3001 | 3000
(4 rows)
postgres=# select col1,col3 from tt where lnnvl( col3 > 2000 );
col1 | col3
------ ------
1001 | 1000
1002 | 2000
2002 |
(3 rows)
nanvl
nanvl,当值不是数字 (nan) 时返回替代值。
替代值可以是数字或可以转换为数字的字符串。
postgres=# \df nanvl
list of functions
schema | name | result data type | argument data types | type
-------- ------- ------------------ ------------------------------------- ------
public | nanvl | double precision | double precision, character varying | func
public | nanvl | double precision | double precision, double precision | func
public | nanvl | numeric | numeric, character varying | func
public | nanvl | numeric | numeric, numeric | func
public | nanvl | real | real, character varying | func
public | nanvl | real | real, real | func
(6 rows)
在以下示例中,如果表 tt 中 col3 的值为 nan 值,则返回 “0”。
select col1, nanvl(col3,0) from tt;
--不知道怎么插入 nan 值,放弃本次测试
nvl
nvl,当值为 null 时返回替代值(必须是数值类型)。
postgres=# \df nvl
list of functions
schema | name | result data type | argument data types | type
-------- ------ ------------------ ------------------------ ------
oracle | nvl | bigint | bigint, integer | func
oracle | nvl | integer | integer, integer | func
oracle | nvl | numeric | numeric, integer | func
public | nvl | anyelement | anyelement, anyelement | func
(4 rows)
在以下示例中,如果表 tt 中 col3 的值为 null 值,则返回 “0”。
drop table tt;
create table tt (col1 int,col3 int);
insert into tt values (1001,1000),(1002,2000),(2002,null),(3001,3000);
postgres=# select col1, nvl(col3,0) "nvl" from tt;
col1 | nvl
------ ------
1001 | 1000
1002 | 2000
2002 | 0
3001 | 3000
(4 rows)
nvl2
nvl2,根据值是否为 null 返回替代值(不要求是数值类型)。
postgres=# \df nvl2
list of functions
schema | name | result data type | argument data types | type
-------- ------ ------------------ ------------------------------------ ------
public | nvl2 | anyelement | anyelement, anyelement, anyelement | func
(1 row)
在以下示例中,如果表 tt 中 col3 列的值为 null,则返回 “is null”,如果不为 null,则返回 “is not null”。
drop table tt;
create table tt (col1 int,col3 int);
insert into tt values (1001,1000),(1002,2000),(2002,null),(3001,3000);
-- oracle
sql> select col1, nvl2(col3,'is not null','is null') from tt;
col1 nvl2(col3,'
---------- -----------
1001 is not null
1002 is not null
2002 is null
3001 is not null
-- orafce 对这个函数似乎支持的还是有问题
postgres=# select col1, nvl2(col3,0,1) from tt;
col1 | nvl2
------ ------
1001 | 0
1002 | 0
2002 | 1
3001 | 0
(4 rows)
-- 返回数值类型的没问题,返回字符类型有问题
postgres=# select col1, nvl2(col3,'is not null','is null') from tt;
error: invalid input syntax for type integer: "is not null"
line 1: select col1, nvl2(col3,'is not null','is null') from tt;
^
问题已解决,详见:https://www.modb.pro/db/389172
listagg
listagg,连接并分隔一组字符串值并返回结果。
postgres=# \df listagg
list of functions
schema | name | result data type | argument data types | type
------------ --------- ------------------ --------------------- ------
pg_catalog | listagg | text | text | agg
pg_catalog | listagg | text | text, text | agg
(2 rows)
在以下示例中,将返回表 tt 中列 col1 的值由 ‘:’ 分隔的结果。
drop table tt;
create table tt (col1 int,col3 int);
insert into tt values (1001,1000),(1002,2000),(2002,null),(3001,3000);
-- oracle
sql> select listagg(col1,':') within group (order by col1) from tt;
listagg(col1,':')withingroup(orderbycol1)
--------------------------------------------------------------------------------
1001:1002:2002:3001
-- orafce,问题:不支持隐式转换
postgres=# select listagg(col1,':') from tt;
error: function listagg(integer, unknown) does not exist
line 1: select listagg(col1,':') from tt;
^
hint: no function matches the given name and argument types. you might need to add explicit type casts.
postgres=# select listagg(col1::text,':') from tt;
listagg
---------------------
1001:1002:2002:3001
(1 row)
postgres=# select listagg(col3::text,':') from tt;
listagg
----------------
1000:2000:3000
(1 row)
-- orafce,问题:不能排序,不支持 oracle 的 within
drop table tt;
create table tt (col1 text,col3 int);
insert into tt values ('2001',1000),('1002',2000),('1002',null),('3001',3000);
postgres=# select listagg(col1,':') from tt;
listagg
---------------------
2001:1002:1002:3001
(1 row)
postgres=# select listagg(col1,':') within group (order by col1) from tt;
error: function listagg(text, unknown, text) does not exist
line 1: select listagg(col1,':') within group (order by col1) from t...
^
hint: no function matches the given name and argument types. you might need to add explicit type casts.
median
median,计算一组数字的中位数。
postgres=# \df median
list of functions
schema | name | result data type | argument data types | type
------------ -------- ------------------ --------------------- ------
pg_catalog | median | double precision | double precision | agg
pg_catalog | median | real | real | agg
(2 rows)
在以下示例中,返回表 tt 中列 col1 的中位数。
drop table tt;
create table tt (col1 text,col3 int);
insert into tt values ('2001',1000),('1002',2000),('1002',null),('3001',3000);
-- 一样不支持隐式转换
postgres=# select median(col1) from tt;
error: function median(text) does not exist
line 1: select median(col1) from tt;
^
hint: no function matches the given name and argument types. you might need to add explicit type casts.
postgres=# select median(col1::double precision) from tt;
median
--------
1501.5
(1 row)
dump
dump,返回值的内部信息。
postgres=# \df dump
list of functions
schema | name | result data type | argument data types | type
-------- ------ ------------------- --------------------- ------
public | dump | character varying | "any" | func
public | dump | character varying | "any", integer | func
public | dump | character varying | text | func
public | dump | character varying | text, integer | func
(4 rows)
在下面的示例中,返回表 tt 中列 col1 的内部信息。
drop table tt;
create table tt (col1 text,col3 int);
insert into tt values ('2001',1000),('1002',2000),('1002',null),('3001',3000);
postgres=# select col1, dump(col1) from tt;
col1 | dump
------ ------------------------------
2001 | typ=25 len=5: 11,50,48,48,49
1002 | typ=25 len=5: 11,49,48,48,50
1002 | typ=25 len=5: 11,49,48,48,50
3001 | typ=25 len=5: 11,51,48,48,49
(4 rows)
sql 运算符
date 类型的 orafce 支持以下日期时间运算符。